







BERM: Training the Balanced and Extractable Representation for Matching to Improve Generalization Ability of Dense Retrieval
原文链接:https://aclanthology.org/2023.acl-long.365/
(2023)
摘要
当在域内标记数据集上进行训练时,密集检索在第一阶段检索过程中显示出了前景。然而,先前的研究发现,密集检索由于其对领域不变和可解释特征(即两个文本之间的信号匹配,这是信息检索的本质)的建模较弱,很难推广到未见过的领域。在本文中,我们提出了一种通过捕获匹配信号(称为 BERM)来提高密集检索泛化能力的新方法。完全细粒度的表达和面向查询的显着性是匹配信号的两个属性。因此,在BERM中,单个段落被分割成多个单元,并提出两个单元级的表示要求作为训练中的约束以获得有效的匹配信号。一是语义单元平衡,二是必要的匹配单元可提取性。单元级视图和平衡语义使得表示能够以细粒度的方式表达文本。基本匹配单元可提取性使段落表示对给定查询敏感,以从包含复杂上下文的段落中提取纯匹配信息。 BEIR 上的实验表明,我们的方法可以有效地与不同的密集检索训练方法(vanilla、硬负例挖掘和知识蒸馏)结合起来,以提高其泛化能力,而无需任何额外的推理开销和目标域数据。
matching signal(匹配信号):领域不变且可以解释的特征
1)语义单元平衡:细粒度表示文本
2)基本匹配单元的可提取性:使段落表示对给定查询敏感,以从包含复杂上下文的段落中提取纯匹配信息。
1. 引言
密集检索将文本编码为密集嵌入,并通过近似最近邻搜索有效地获取目标文本(Johnson 等人,2021)。与BM25(Robertson et al,1995)等传统的词对词精确匹配方法相比,密集检索可以捕获两个文本在语义层面的相关性。由于密集检索在效率和效果方面具有优异的性能,因此被广泛应用于第一阶段检索,从大型语料库中高效地召回候选文档(Karpukhin et al, 2020; Xiong et al, 2021a)。
然而,最近的研究表明,密集检索的优异性能依赖于大型域内数据集的训练。当训练好的密集检索模型应用于与训练数据集不一致的领域(即零样本设置)时,模型的性能会严重下降(Ren et al, 2022;Thakur et al, 2021)。泛化性差限制了密集检索的应用场景,因为在医学、生物学、法律等对数据隐私有限制或需要专业知识注释的领域,通常无法获得足够的训练样本。
在这项工作中,我们指出,根据域外泛化学习理论(Y e et al, 2021),使模型捕获域不变特征(即任务的本质)对于提高泛化能力是有效的。对于密集检索,查询和段落之间的匹配信号是重要的域不变特征,反映了信息检索(IR)的本质。例如,MoDIR(Xin 等人,2022)表明,基于交互的交叉编码器的表示(用于匹配的更细粒度的描述)比密集检索的表示具有更多的域不变性。Match-Prompt (Xu et al, 2022a)、NIRPrompt (Xu et al, 2022b) 和 MatchPyramid (Pang et al, 2016) 指出了匹配信号对于各种 IR 任务的积极意义。让密集检索模型学习捕获匹配信号的挑战在于,在许多 IR 任务中,例如开放域问答(Chen 等人,2017)和文档检索(Mitra 等人,2017),与查询匹配的内容是通常只是文本的一个单元。匹配信号的描述需要区分文本中匹配和不匹配的信息并估计整体相关性。这就要求检索模型能够均匀地表达文本中的每个单元,并通过两个文本表示的交互动态地提取匹配单元。然而,第一阶段检索对效率的要求使得密集检索只能通过点积、余弦等向量相似度来估计相关性。先前基于该架构的训练方法由于粗粒度的训练目标和交互而缺乏上述能力。
在本文中,我们提出了一种称为BERM的新方法来捕获查询和段落之间的匹配信号,即域不变特征,以在不使用目标域的情况下在单源域上训练期间提高密集检索的泛化能力数据和其他附加模块。首先,我们引入密集检索中的一个新概念,即匹配表示。匹配表示由查询和段落的文本表示(文本编码器的输出)确定,它可以反映查询和段落的匹配信息。我们提出,在密集检索模型的训练中,除了使用对比损失(Xiong et al,2021b)来优化文本表示之外,还可以使用匹配表示的信息作为约束来辅助优化。基于此,我们将单个段落划分为多个单元(每个句子是一个单元),并提出对可泛化密集检索模型作为训练约束的两个要求(如图1所示)。一是文本表示的语义单元平衡(R1)。另一个是匹配表示的基本匹配单元可提取性(R2)。这两个要求可以集成到不同的密集检索训练方法中并解决上述挑战。 R1意味着段落中单元的语义隐式聚合到其文本表示中,并且文本表示应该均匀、全面地表达每个单元的语义。 R2意味着查询和段落的文本表示(即匹配表示)的组合应该提取匹配的信息(即段落中与查询匹配的文本块,我们称之为必要匹配单元),同时减少过度拟合域偏差。这反映了密集检索模型在包含复杂上下文的段落中确定和评分真正匹配查询的信息的能力,这是密集检索和领域不变性的本质。 R1和R2实现了在文本表示以平衡方式表达各个单元的前提下,为了提取不同查询的必要匹配单元,单元的语义趋于相互正交。这样,在查询和段落表示之间的点积中,基本匹配单元的语义被保留,而其他单元被屏蔽,适合匹配。
在标准零样本检索基准(BEIR)上的实验表明,我们的方法可以有效地与不同的密集检索训练方法(vanilla、硬负例挖掘和知识蒸馏)结合起来,以提高泛化能力,而无需任何额外的模块、推理开销、和目标域数据。即使在领域适应中,我们的方法也是有效的并且比基线表现得更好。代码发布于 https://github.com/xsc1234/BERM。
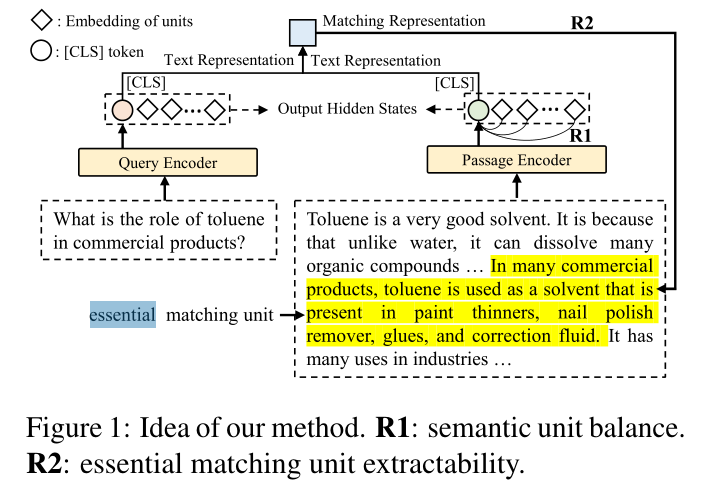
1)matching signal:query 和 passage 之间的域不变特征。在一个数据集学习之后,可以直接泛化到其他数据集。
2)matching representation:query 和 passage 文本表示的组合
3)passage --> unit:
a)semantic unit balance of text representation :每个 unit 信息隐式聚合,并且 text representation 可以反应每个 unit 的信息
b)essential matching unit extractabenility of matching representation:既能够提取匹配信息,又能够减少过度拟合
Ps:essential matching unit:与 query 匹配的 passage 中的 text chunk
2. 相关工作
密集检索通过两个文本的表示来估计相关性。 DPR(Karpukhin 等人,2020)将密集检索与用于开放域问答的预训练模型相结合(Chen 等人,2017)。此外,一些方法侧重于获得更有价值的负例(Qu et al, 2021; Xiong et al, 2021a; Zhan et al, 2021)。一些方法使用更强大的重新排序器来进行知识蒸馏(Hofstätter 等人,2021;Lin 等人,2021)。最近,密集检索的泛化受到了关注。 (Ren 等人,2022)对密集检索的泛化进行了检查。
BEIR(Thakur et al,2021)被提出作为评估信息检索模型的零样本能力的基准。 MoDIR(Xin 等人,2022)使用来自源域和目标域的数据进行对抗训练,以执行无监督域适应。 GenQ(Ma 等人,2021)和 GPL(Wang 等人,2022)生成用于域适应的查询和伪标签。 Contriever (Izacard et al, 2021) 在大型语料库(维基百科和 CC-Net (Wenzek et al, 2020))上使用对比预训练。COCO-DR(Yu et al, 2022)对目标域进行无监督预训练,并引入分布式鲁棒优化。 GTR(Ni et al, 2021)扩大了模型大小以提高泛化能力。 (Huebscher 等人,2022;Formal 等人,2022)引入稀疏检索以实现更好的泛化。
以往研究中密集检索泛化能力的提高来自于目标领域的适应、来自大型预训练语料库的知识以及稀疏检索的辅助而不是密集检索本身。他们需要在训练中获取目标领域数据或增加系统的复杂性。在本文中,我们介绍了一种通过学习匹配的泛化表示来提高密集检索的泛化性的新方法,无需目标域数据和附加模块。
必须强调的一点是,多视图密集检索的方法(Zhang et al, 2022; Hong et al, 2022)也将一段段落划分为多个单元,但我们的方法本质上是一种完全不同的方法。多视图密集检索使用多种表示形式从多个视图充分表达一段文字,侧重于域内检索。我们的方法使用多个单元使模型学习从包含复杂上下文的段落中提取必要的匹配单元,这对于泛化来说是领域不变的。在我们的方法中,多个单元仅用作训练优化的约束,并且仅在推理中使用单个表示。基于学习的稀疏检索,例如 COIL (Gao et al, 2021) 和 SPLADE (Formal et al, 2021) 也旨在表达细粒度的标记级语义,但它们需要多个向量来表示段落中的标记 (COIL) 或稀疏-词汇大小的向量(SPLADE)并通过token-to-token匹配来计算分数,这不适合使用单个密集向量执行表示和点积的密集检索。
3. 动机
由于其对域不变特征(即两个文本之间的信号匹配,这是信息检索的本质)的建模较弱,密集检索很难推广到未见过的领域。完全细粒度的表达(P1)和面向查询的显着性(P2)是匹配信号的两个属性。这两者要求段落表示能够均匀地表达文本中的每个单元,并根据与不同查询的交互动态地提取匹配单元。例如,BM25使用one-hot来均匀地表达文本的每个单词,仅对匹配的单词进行评分,通过两个文本的词对词精确匹配来忽略不匹配的单词。交叉编码器使用词嵌入来表示每个标记的语义,并使用注意力机制以细粒度的方式描述文本之间的标记到标记的语义匹配。
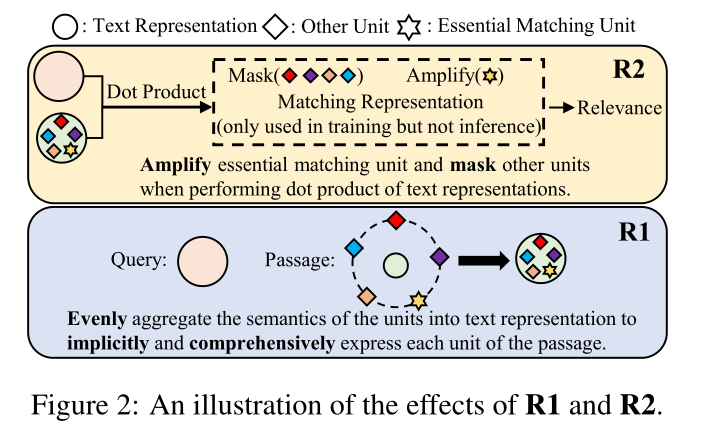
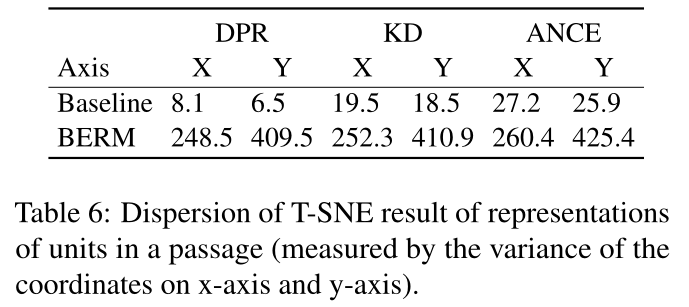
本文基于上述两个特性,对于密集检索的训练,我们将单个文章分割成多个单元,并提出两个要求作为训练中的约束,以便密集检索能够捕获更强的匹配信号并产生合适的表示用于匹配。一是文本表示的语义单元平衡性(R1),二是匹配表示的基本匹配单元可提取性(R2)。在R1下,文本表示均匀地聚合了段落中各个单元的语义,以细粒度的方式全面表达段落。另外,R1是R2的前提。这是因为匹配表示由来自段落和查询的文本表示组成。文本表示中不同单元的语义表达不平衡会影响匹配表示中基本匹配单元的识别,因为它会导致不同单元的偏好不同。在R2下,可以从段落中提取查询的基本匹配单元并反映在匹配表示中。与使用 one-hot 或词嵌入显式表达每个单元的语义并通过 token-token 交互提取匹配信息不同,如图 2 所示,R1 使模型隐式地将每个单元的语义聚合到文本表示中以满足P1,和R2使得单元的语义趋于相互正交(如表6所示)。在查询和段落表示之间的点积中,基本匹配单元的语义被保留,而其他单元被屏蔽,这可以满足P2。我们的方法解锁了密集检索捕获匹配信号的能力,无需额外的交互。
4. 方法
本节介绍我们方法的实现(图 3)。我们的方法优化了文章中的表示和单位之间的关系。因此,在训练之前,我们进行单元分割并注释数据集的基本匹配单元。然后,我们根据R1和R2的要求设计损失函数,并将这些函数与密集检索(对比损失)的任务损失结合起来进行联合训练。
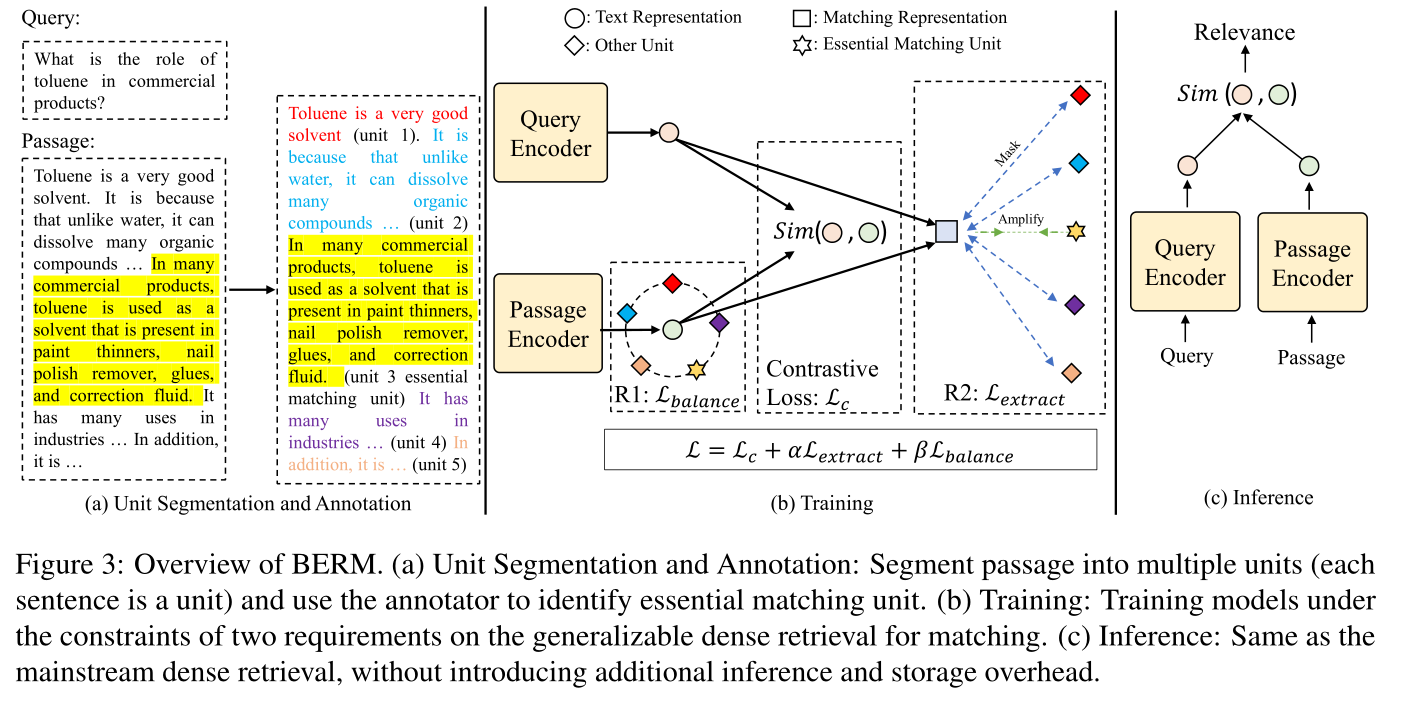
4.1 单元分割和标注
给定训练数据中的每个 positive 查询-段落对(q,ppos),我们将正段落分割成多个单元 U,如图3(a)所示(我们使用句子作为分割粒度,以确保每个单元具有完整的语义信息.):
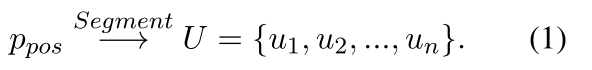
对于 U 和 q,BM25 用于计算 q 和 ui ∈ U 之间的单词到单词匹配分数 Sbm25:
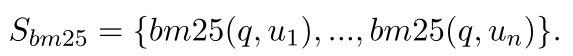
对于问答数据集,还引入了经过训练的阅读器模型来计算 q 和 ui ∈ U 之间的语义匹配分数 Sreader。具体来说,阅读器模型计算的概率分布 A = {a1, a2, …, at} ppos 中答案的起始位置。 ai 表示 ppos 中第 i 个标记是 q 答案开始的概率。对于每个 ui ∈ U,阅读器模型的语义匹配分数为:
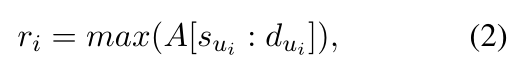
其中 [sui : dui] 是 ui 中标记的索引。ui 和 q 之间的混合匹配得分 hi 为:
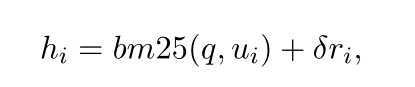
其中 δ 是超参数。我们将 δ 设置为 0.1,以赋予 BM25 比 reader 更高的权重。这是因为BM25的词对词精确匹配比读者的语义匹配更具领域不变性并且有利于泛化(Thakur等人,2021)。然后我们得到U的匹配分数列表H = {h1, h2, …, hn}。基本匹配单元是H中最大值对应的单元。对于(q, ppos)对,标签列表中的yi Y = {y1, …, yn} 的基本匹配单元是,如果i是H中最大值对应的索引,yi = 1,否则,yi = 0。
1)essential matching unit:hi 得分最高的那个句子。
2)对于 query-passage 训练对,y1-yn 的 label 列表。得分最高 yi=1,其他为0。
4.2 泛化训练
基于第3节中匹配信号特性的分析,我们提出了两个要求作为密集检索训练的约束,以获得匹配的通用表示(如图3(b)所示)。这两个要求使得密集检索能够在各个单元均衡表达的前提下提取必要的匹配信息,从而学习领域不变的特征(即匹配信号)进行泛化。
R1 的实现
第一个要求是文本表示的语义单元平衡,这意味着段落编码器的文本表示能够以平衡的方式全面表达各个单元的语义。给定段落 ppos,文本编码器 g(·; θ),输出隐藏状态 Z = g(ppos; θ)。 ppos 的文本表示 tp 是 Z 的 [CLS] token 的嵌入。 ppos 中单元的嵌入 E 可以从 Z 中获得,作为等式(1)中的分割:
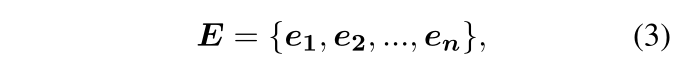
其中 ei 是相应单元 (ui) 的嵌入,它是该单元中标记 (Z[sui : dui]) 嵌入的平均池化,其中 [sui : dui] 是 ui 中标记的索引。在R1的约束下,tp和E之间的关系用损失函数描述为:
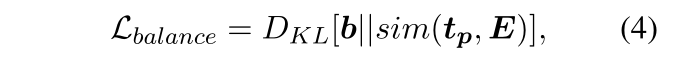
其中 DKL[·||·] 是 KL 散度损失,b = [ 1 n, …, 1 n] 是等值均匀分布,并且 sim(tp, E) = {dot(tp, ei)| ei ∈ E} 是表示 tp 和 ei ∈ E 之间语义相似度的分布,dot(·,·) 是点积。
1)从 encoder 的隐藏状态 Z 中获得每个 unit 的嵌入,句子中所有 token 的平均池化。
文章向量表示:cls;
unit 向量表示:平均池化 token
2)KL 散度衡量两个分布的差异性,要使得 passage 编码的信息中,每个 unit 的信息尽可能均衡。
R2 的表示
第二个要求是匹配表示的基本匹配单元可提取性,这意味着在R1的前提下,匹配表示可以显着地表示基本匹配块所在的单元。这种设计的动机在第1节和第3节中讨论。给定正查询段落对 (q, ppos)、文本编码器 g(·; θ) 以及 q (tq) 和 ppos (tp) 的文本表示。 q 和 ppos 的匹配表示 m ∈ Rv (v 是表示的维度)可以通过 tq ∈ Rv 和 tp ∈ Rv 的组合获得:
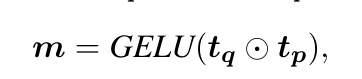
其中 ⊙ 是逐元素乘法运算符,GELU(·) 是引入随机正则化的激活函数(Hendrycks 和 Gimpel,2016)。
在R1的前提下,tp可以平衡地表达ppos中单元的语义。此外,基本匹配单元的语义表示比其他单元更类似于 tq,因为它确实与查询 q 匹配。基于此,可以训练模型以实现tq和tp之间的逐元素乘法可以放大相似模式(即基本匹配单元的语义表示)并屏蔽其他上下文单元的信号的目标。这种设计可以得到卷积神经网络的支持(LeCun 等人,1998),其卷积运算可以放大张量中的相似模式(Girshick 等人,2014)。对于ppos,不同的q放大了不同的匹配单元,这使得m反映了相应的基本匹配单元的语义。此外,m是通过tq和tp之间的元素相乘获得的,这是估计两个文本相关性的重要部分,因为dot(tq, tp) = sum(tq ⊙ tp)。因此,m的优化可以使模型在估计相关性时获得根据不同查询提取必要匹配单元的能力。在训练中,我们的方法利用交叉熵损失函数来优化 m 与每个单元之间的语义距离,以识别相应的基本匹配单元。给定查询-段落对 (q, ppos),ppos 中单元的嵌入 E 如方程中所述。 (3),以及(q,ppos)的基本匹配单元的标签Y,如第2节所述。 4.1. R2 的损失函数为:
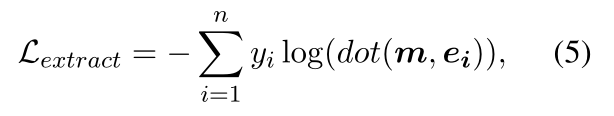
其中 ei Î E,yi Î Y 。 m 仅用作训练中的约束,但对推理具有重要意义。这是因为 m 是文本表示(tp 和 tq)的组合。 m的优化是训练文本编码器输出适合匹配的文本表示,以提高泛化能力。
element-wise multiplication(和点积相比,没有相加):可以放大相似 pattern,屏蔽其他 pattern。
R1 和 R2 的影响
表6表明,与之前的密集检索方法相比,我们的方法使得文本表示中的单元语义趋于彼此正交。在两个文本之间的点积中,保留基本匹配单元的语义,而其他单元被屏蔽以捕获匹配信号。
总损失
除了 Lextract 和 Lbalance 之外,还使用对比损失来训练密集检索模型(Karpukhin 等人,2020):
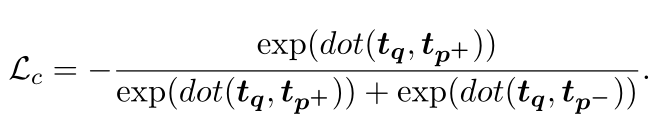 所以我们方法中训练的总损失是:
所以我们方法中训练的总损失是:
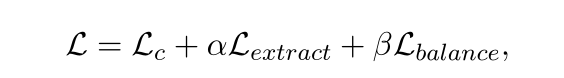
其中 α 和 β 是超参数。
1)三种损失:正负文章的对比损失 + R1的文章平衡损失 + R2的基本匹配单元提取损失
a)对比损失:softmax 多分类
b)R1损失:unit表示与文章表示内积,与等值均匀分布的 KL 损失
c)R2损失:query和passage表示的逐元素乘,然后gelu,放大passage中基本匹配单元的pattern,得到的m,再与unit表示点积之后进行交叉熵损失
5. 实验
本节介绍实验设置并分析结果
5.1 实验设置
数据集
我们使用 MS-MARCO (Nguyen et al, 2016) 作为训练数据(源域),并从 BEIR 1(一个评估检索模型泛化能力的异构基准)中选择 14 个公开可用的数据集。此外,我们还引入了 OAG-QA (Tam et al, 2022) 来评估主题(20个)泛化能力。数据集的详细信息参见附录 A。
基线
我们的方法(BERM)旨在提高密集检索的泛化能力,无需任何额外的模块和目标域数据,并且它可以与不同的密集检索训练方法相结合。我们选择三种主流的密集检索训练方法,包括普通方法、硬负例挖掘和知识蒸馏方法作为基线。我们遵循 DPR(Karpukhin 等人,2020)执行普通操作,遵循 ANCE(Xiong 等人,2021a)执行硬负例挖掘,并使用经过训练的交叉编码器作为教师模型来执行知识蒸馏。我们比较了将 BERM 与这三种方法结合后泛化的变化,以显示我们方法的有效性。此外,由于先前的方法需要获取目标域数据以进行域适应,例如MoDIR(Xin等人,2022)、GenQ(Ma等人,2021)、GPL(Wang等人,2022)和COCODR(Y u等人, 2022),我们还在域适应设置中将我们的方法与这些方法进行了比较。
基线的详细信息参见附录 B。
实现细节
为了保持公平的比较,我们遵循(Xiong et al,2021a)保持所有常见的超参数(学习率和批量大小等)与基线中的三种密集检索训练方法相同。模型由Robertabase 125M初始化。对于BERM中的超参数,δ为0.1,α为0.1,β为1.0。在领域适应中,我们将 BERM 与连续对比预训练(Y u et al, 2022)相结合,在 BEIR 上进行无监督预训练,并使用 BERM 在 MS-MARCO 上微调模型。我们使用 Pytorch(Paszke 等人,2019)和 Hugging Face(Wolf 等人,2020)在 2 个 Tesla V100 32GB GPU 上训练模型约 72 小时。
5.2 检索性能
主要结果
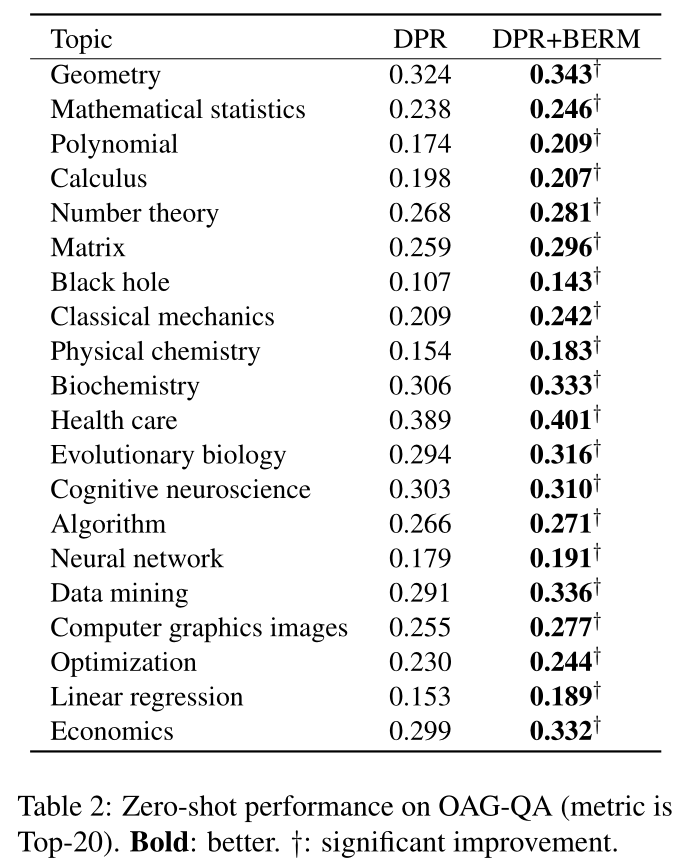
表1显示了不同密集检索训练方法的BEIR主要结果。结果表明,我们的方法(BERM)可以与三种主流的密集检索训练方法(vanilla、知识蒸馏和硬负例)相结合,以提高泛化能力,而无需任何额外的模块和目标域数据。
为了公平比较,我们将 BERM 与基线结合起来,并确保它们的公共超参数一致。我们计算每个数据集和 MS-MARCO 之间的 Jaccard 相似度(Ioffe,2010),它可以反映源域和目标域之间的域转移。表1表明,我们的方法对于MS-MARCO之间Jaccard相似度较低的数据集更有效(即域转移更显着)。这个结果反映了我们的方法捕获域不变特征的能力。 DPR+BERM 和 KD+BERM 优于 KD,这表明 BERM 比交叉编码器的知识蒸馏更有效地使密集检索学习捕获匹配信号。
1)本文方法可以与三种主流密集检索方法结合来提高泛化性能;
2)对于源域和目标域相似度低的数据集,提升效果更大
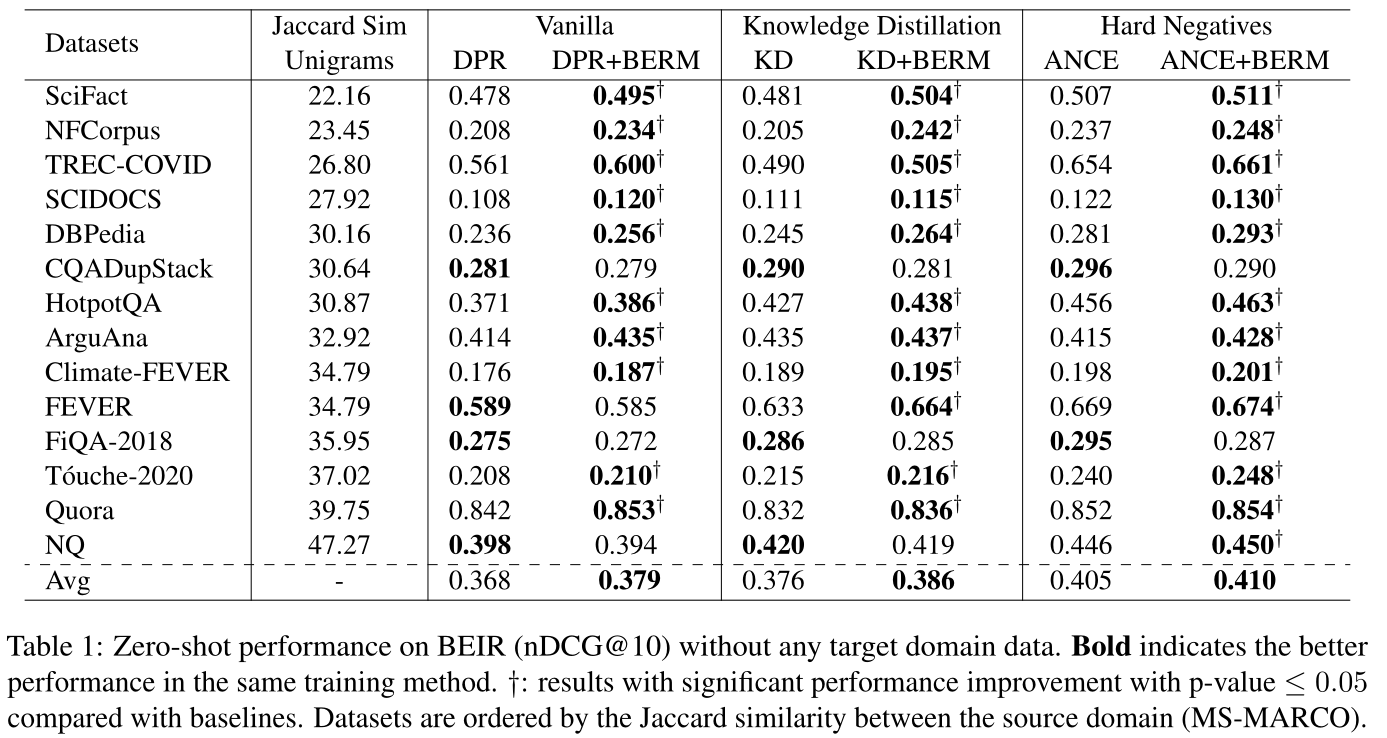
主题泛化
表2显示了DPR和DPR+BERM在QAG-QA不同主题上的泛化性能。主题泛化对于域外泛化很重要,这反映了密集检索模型对不同词分布的主题的可用性。结果表明,BERM 可以显着提高密集检索的跨主题泛化能力。
1)可以提高跨主题泛化的能力
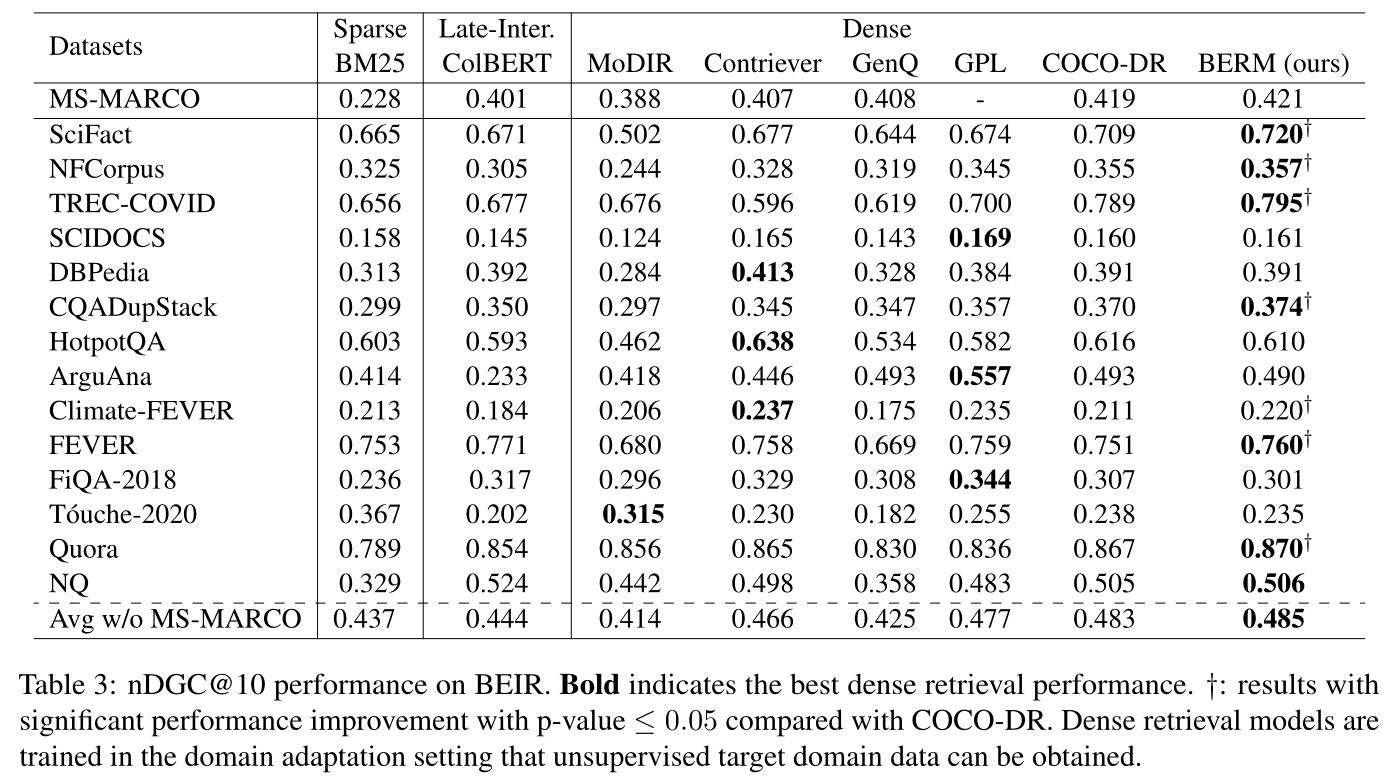
域适应
表 3 显示,与之前的基线相比,BERM 在域适应方面实现了最佳性能。具体来说,BERM 实现了最佳的平均域外自适应和域内性能。此外,它在BEIR的7个数据集上得到了最好的密集检索结果,是所有方法中最多的。我们的方法不仅学习目标域的单词分布,而且在域适应期间学习适合匹配目标语料库中的文档的表示。
1)在域适应方法也是最优
5.3 消融研究
损失函数的影响
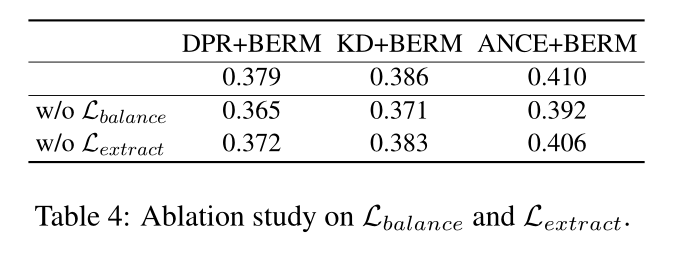
表 4 显示了通过 BEIR 上的平均性能对 R1 和 R2 约束的损失函数进行的消融研究。结果表明,如果没有 Lbalance,Lextract 就无法提高泛化能力,这支持了我们在第 3 节中的直觉,即只有基于文本表示中每个单元的平衡语义表达,匹配表示对于提取基本语义单元才有意义。该实验表明,当模型同时受到R1和R2约束时,泛化能力可以得到显着提高。
每个语义单元平衡表达,提取基本语义单元才有意义
超参数的影响
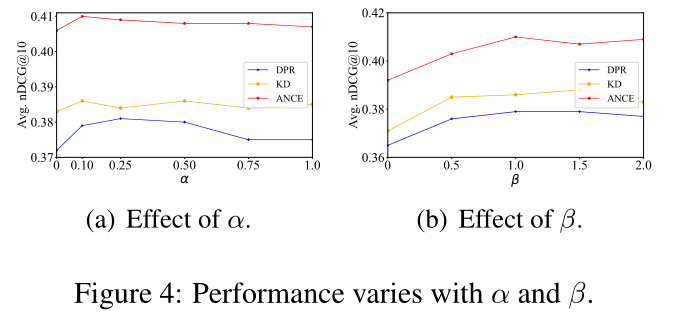
图 4 显示了具有不同 α 和 β 的 BEIR 上的平均 nDCG@10 性能,这些α和β用于调整训练中不同损失函数的权重。当α为0.1且β为1.0时,我们的方法可以获得最佳性能。当α和β太大时,它们会干扰对比损失的优化,导致性能下降。
5.4 模型分析
域不变表示
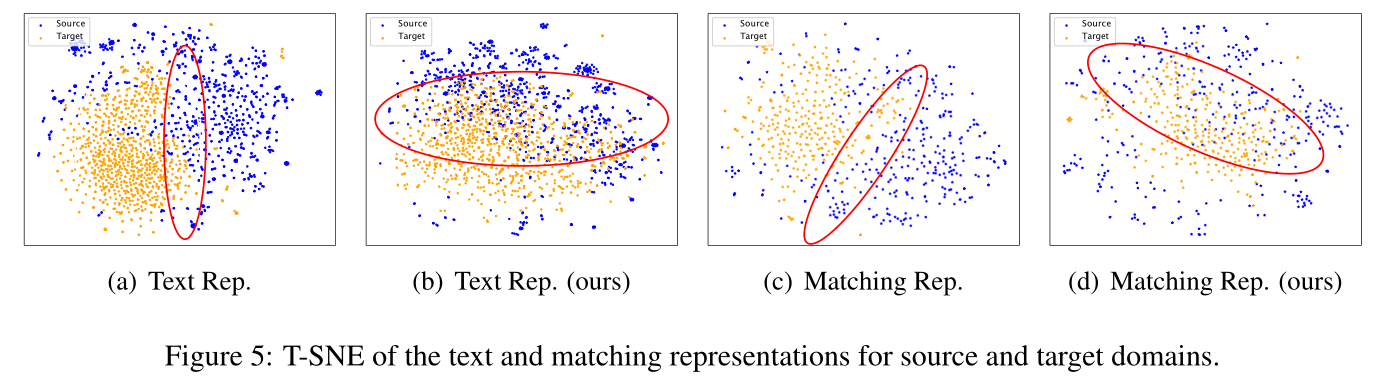
图 5 显示我们的方法可以有效捕获表示的域不变特征。我们利用 T-SNE 来可视化分别由 DPR 和 DPR+BERM 编码的源域和目标域 (SciFact) 的表示。结果表明,DPR 编码的两个域的表示更加可分离。结合我们的方法后,这两个域变得更难以分离,这表明我们的方法在表示不同域中的文本时更具不变性。更多数据集见附录 C。
R1和R2的评估
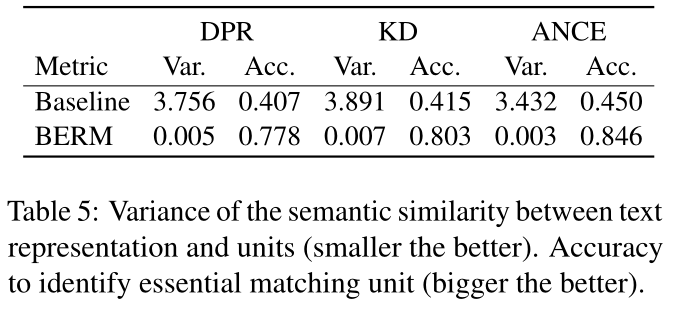
表 5 显示了 R1 和 R2 的有效性。我们从测试集中随机抽取 100,000 个查询-段落对。对于每个段落 p,我们通过 sim(tp, E) = {dot(tp, ei)|ei ∈ E} 计算文本表示和每个单元之间的语义相似度。我们计算 sim(tp, E) 的方差并得到采样集上的方差平均值,这可以反映文本表示在表达单位语义上的平衡。表5显示,BERM比基线具有更小的方差(文本表示的语义单元平衡)并且在识别基本匹配单元(匹配表示的基本匹配单元可提取性)方面更准确,这表明了R1和R2的有效性。
单元之间的关系
表6显示我们的方法使段落中的单元更加分散(趋于正交),这更有利于确定与查询匹配的单元并屏蔽其他单元的信号。我们的方法使段落的表示更适合匹配,这是泛化的领域不变特征。
6. 结论
在本文中,我们提出了一种称为 BERM 的有效方法来提高密集检索的泛化能力,而无需目标域数据和附加模块。 BERM的基本思想是学习域不变特征,即匹配信号。为了实现这一目标,我们引入了密集检索的新概念来表示两个文本之间的匹配信息,即匹配表示。此外,我们提出了匹配和文本表示两个要求作为密集检索训练中的约束,以增强在平衡文本表达的前提下根据不同查询从段落中提取必要匹配信息的能力。这两个要求解锁了密集检索在无需额外交互的情况下捕获匹配信号的能力。实验结果表明,BERM是一种灵活的方法,可以与不同的密集检索训练方法相结合,而无需推理开销,以提高域外泛化能力。在域适应设置中,我们的方法也是有效的并且比基线表现更好。
补充知识:
Vanilla
单输入,单输出的神经网络。就叫Vanilla neural network。
知识蒸馏
利用 teacher 模型训练一个 student 模型。
参考资料:
【1】vanilla:https://www.zhihu.com/question/68433311
【2】知识蒸馏:https://zhuanlan.zhihu.com/p/258390817

















 5911
5911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









