







Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset I3D论文精读
论文地址:https://openaccess.thecvf.com/content_cvpr_2017/papers/Carreira_Quo_Vadis_Action_CVPR_2017_paper.pdf
这篇论文的主要贡献有两个。其中一个是提出了inflated膨胀的卷积神经网络,这样就可以把2D里面已经训练好的网络直接扩展到3D,比如VGG,ResNet等,还可以利用一些方式,将预训练模型利用起来,另一个贡献是提出了Kinetics数据集,这是一个大小适中的数据集,它有400类人体行为类别,每个类别有400多个clips。作者提出的I3D模型在Kinetics数据集上预训练之后,在基准数据集HMDB-51和UCF101上分别达到了80.9%和98.0%的准确率,相比之前的模型,效果有了大大的提升。
在当时,行为识别有几大主流方法。他们的不同之处在于,卷积和层运算是使用2D核还是3D核,网络输入只包含视频信息还是也包括光流信息,作者对比了图一的几种方法的优点和缺点:
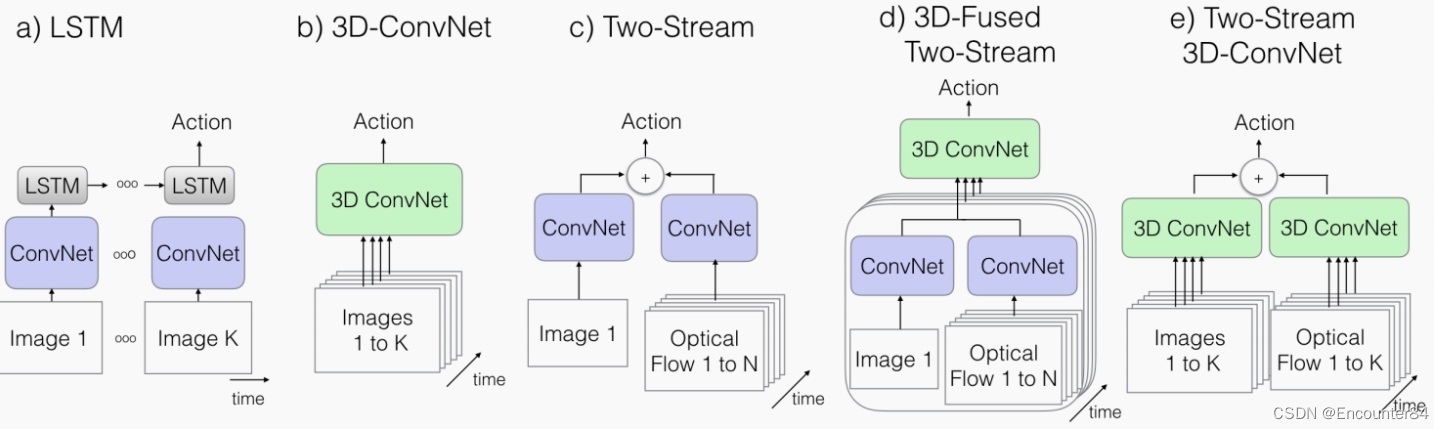
如图(a),第一种方法是在卷积神经网络后面接一个时许神经网络LSTM,这种方式还是将视频当作图像分类的任务来完成。这个网络的结构和时序神经网络很相似,将视频帧按照时间顺序一张一张送入网络,先经过一个卷积神经网络抽取特征,再将其送入LSTM网络中,用LSTM去模拟时序信息。最后再加一个全连接层,就可以实现分类任务了,但是这种方法表现的并不是很好。
如图(b),是一个3D卷积神经网络。首先将视频切割成一个一个的视频段,每个视频段里面都有1-k一共k张照片,然后在这些图像段上面应用3D卷积神经网络。相比于2维的图像,多了一个时间维度,因此卷积核的大小为3X3X3。由于多了一个维度,神经网络训练所需的参数大大增加了,在训练集比较小的时候,该方法优势不明显,但是使用比较大的数据集时,就可以体现出神经网络的优势来了。Input输入维度为16帧 尺寸112*112,本文实现了C3D的一个变种,在最顶层有8个卷积层,5个pooling层和2个全联接层。模型的输入是16帧,每帧112x112的片段。不同于论文中的实现是,作者在所有的卷积层和全联接层后面加入了BN层,同时将第一个pooling层的temporal stride由1变为2,来减小内存使用,增加batch的大小。
如图(c),是双流网络,我上一篇博客有讲解:(100条消息) Two-Stream Convolutional Networks for Action Recognition in Videos双流网络论文精读_Encounter84的博客-CSDN博客
如图(d),结合了3D网络和双流网络,刚开始的输入和双流网络是一样的,左边使用一个2D的CNN网络,输入的是单帧图片,右边也是2D的CNN网络,然后输入是光流,最后在还没有出结果的时候把两个特征先融合在一起,然后用一个3D卷积神经网络去提取特征,最后直接得到一个分类结果,这里的3DCNN也可以用LSTM替代的,但是相对来说3DCNN的效果更好一些。网络的输入是相隔10帧采样的5个连续RGB帧,采用端到端的训练方式.
如图(e),双流Inflated 3D卷积,扩展2D卷积base model为3D base model卷积,卷积核和pooling增加时间维,尽管3D卷积可以直接学习时间特征,但是将光流加进来后会提高性能。
这篇论文中有一个很有创意的想法,就是Bootstrapping。即如何能从一个2D的ImageNet上面已经训练好的模型出发,然后去初始化一个3D模型继续做训练。作者这里使用的思想是:给定同样的输入,用这个输入在原来的那个模型上跑一遍,然后再在初始化后的模型上再跑一遍,这两种输出按道理来说应该是完全一样的,这两个模型是完全对等的,如果是同样的输入同样的模型,那输出就应该相等。这里作者用同样一张图片反复复制粘贴,最后变成了一个视频,这个视频里全都是同样的视频帧,播放是没有变化的,作者把所有2D的filter全都在这个时间的维度,也复制粘贴了N次,这样就跟2DCNN的参数对应起来了,得到了一个初始化好的3D模型,不需要再从头开始训练了。
在模型的具体实现细节上,对于3D卷积神经网络来说,时间维度不能缩减地过快或过慢。如果时间维度的感受野尺寸比空间维度的大,将会合并不同物体的边缘信息。反之,将捕捉不到动态场景。因此作者改进了BN-Inception的网络结构。在前两个池化层上将时间维度的步长设为了1,空间还是2X2。最后的池化层是2X7X7。训练的时候将每一条视频采样64帧作为一个样本,测试时将全部的视频帧放进去最后average_score。除最后一个卷积层之外,在每一个卷积后面都加上BN和relu,具体如下图。
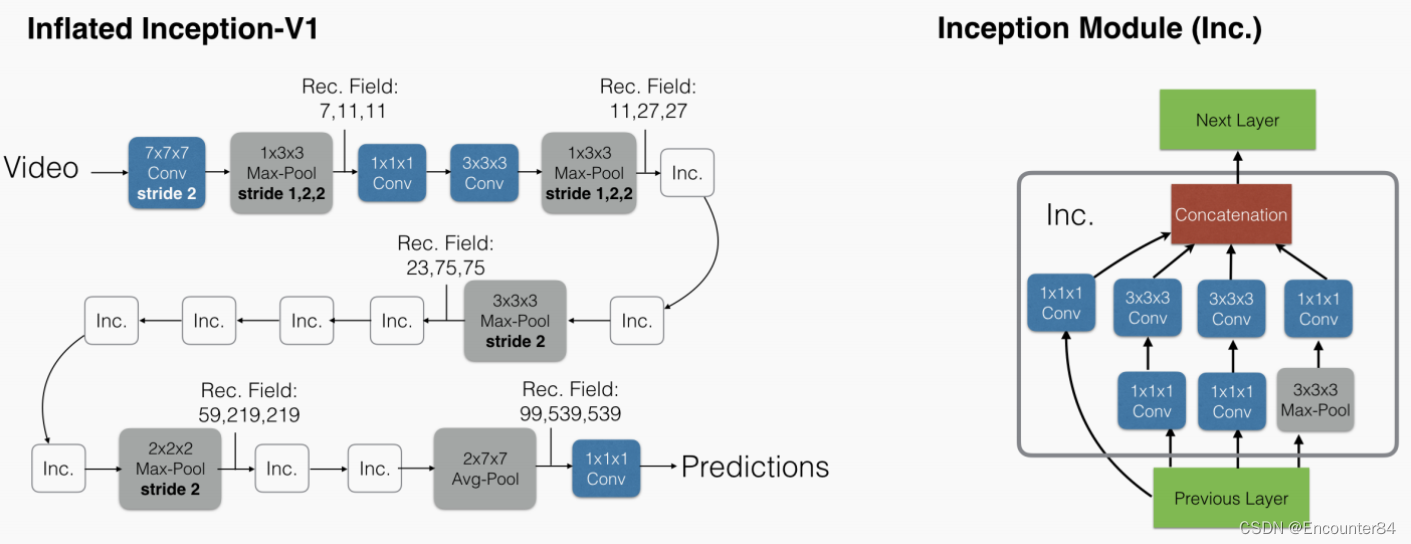
关于上述各种模型的实现细节,除了C3D之外,其他模型使用预训练的Inception-V1作为基网络,除了最后的卷积层之外,对其他卷积层都进行了BN操作和ReLU激活。在所有情况下,视频训练使用标准SGD,动量设置为0.9, 作者在Kinetics数据集上训练了110k步的模型,当验证损失饱和时,学习率降低了10倍。在Kinetics的验证集上调整了学习率超参数。模型在UCF-101和HMDB-51上训练模型达5k步,使用相似学习率适应程序。在训练期间,spatial上是先将原始帧resize成256X256的,然后随机剪裁成224X224的。在temporal上,尽量选择前面的帧以保证足够光流帧的数目足够多。短的视频循环输入以保证符合网络的input_size。在训练中还用到了随机的左右翻转。测试的时候选用中心剪裁224X224,将整条视频的所有帧输入进去,之后average_score。实验测试256x256的视频并没有提高,测试时左右翻转video,训练时增加额外的augmentation,如phonemetric,可能有更好的效果。
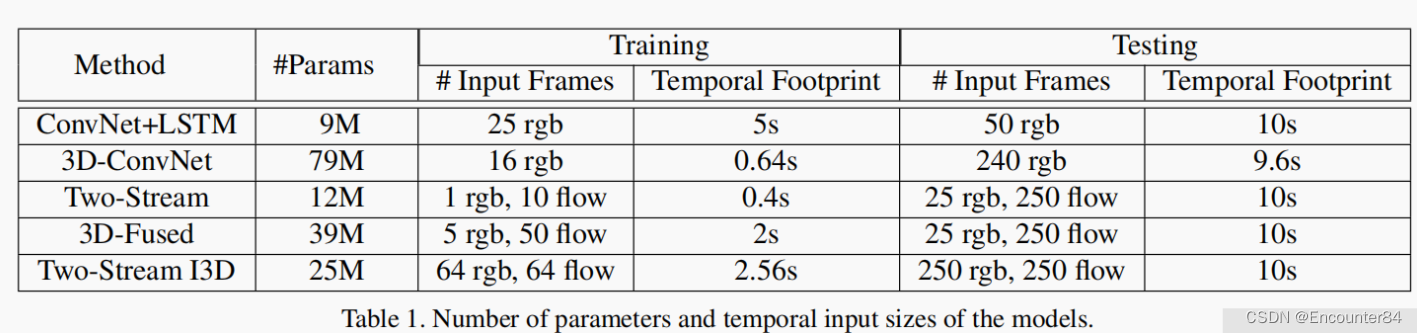
通过对不同结构模型进行训练和测试。下图显示了在UCF-101,HMDB-51或Kinetics上进行训练和测试时的分类准确度。















 3586
3586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









