







论文地址:https://arxiv.org/pdf/2110.11474.pdf
Abstract
在本文中,我们试图通过提出行为者环境交互(AEI)网络来模拟人类的能力,以改进针对时间动作建议生成的视频表示。AEI包含两个模块,即基于感知的视觉表示(PVR)和边界匹配模块(BMM)。PVR通过使用所提出的自适应注意机制来考虑人-人关系和人-环境关系来表示每个视频片段。然后,由BMM通过视频表示来生成行动建议。AEI在ActivityNet-1.3和THUMOS-14数据集中进行了时间动作建议和检测任务,采用两种边界匹配架构(即基于cnn和GCN)和两种分类器(即Unet和PGCN)。我们的AEI在时间动作建议生成和时间动作检测方面具有显著的性能和泛化性,其性能显著优于最先进的方法。
Introduction
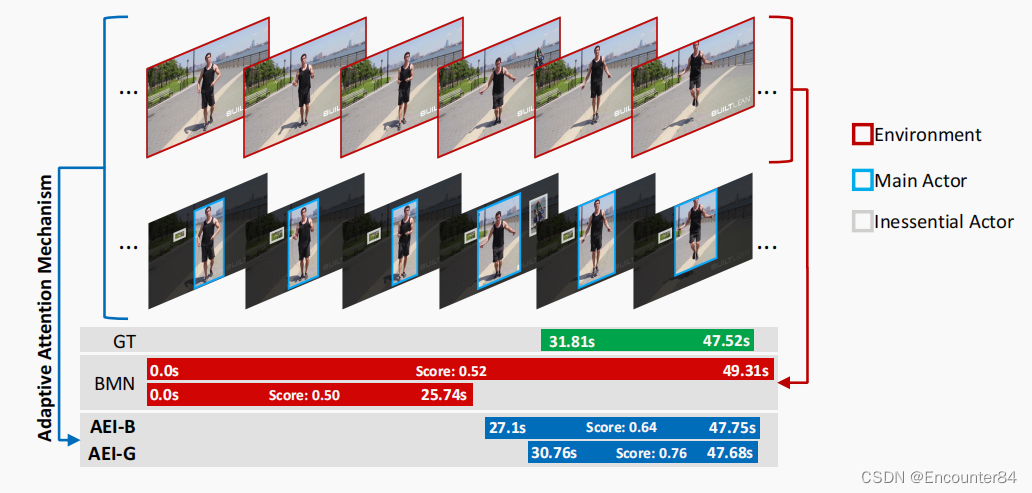
上图是TAPG比较。现有的方法(例如,BMN)将网络主干应用于整个空间域(红框);我们的AEI通过AAM考虑了主要的参与者。我们的AEI是通过基于cnn的BMM(AEI-B)和基于GCN的BMM(AEI-G)来实现的。
尽管在基准数据集[9,20]上取得了很好的成就,但SOTA方法忽略了上述人类的感知过程,只应用一个主干网络(预先训练的动作识别任务)来提取视频表示,从而导致一些建议的潜在丢失。例如,在上图中,文献中的作品采用了视频帧的整个空间区域(例如,红框)来提出动作间隔;然而,这可能会导致不准确的结果,因为背景比执行动作的参与者(例如,蓝框)要大得多。在上图中,“跳绳”动作可以欺骗动作建议模型,由于“跳跃”和“站立”之间的细微差异而错过动作开始或结束的时间。
我们的贡献总结如下:
我们提出了一个视频表示网络AEI,它遵循人类的感知过程来理解人类的行为。
我们引入了一种新的适应性注意机制(AAM),它同时选择主要行为者,消除非必要行为者(s),然后提取主要行为者之间的语义关系。
我们通过在基于CNN和基于GCN的两种网络架构下实现BMM来研究所提出的AEI的有效性。
我们提出的AEI网络在TAPG和TAD轨道上都实现了SOTA-1.3和THUMOS-14的通用基准数据集上的SOTA性能,与之前的工作相比有很大的优势。
Our proposed AEI
之前的工作是使用一个预先训练过的主干网络(例如,C3D网络[19]或双流网络[37])来提取视频特征。然而,简单地将这些网络用于视频表示可能会有一些缺点,不能将注意力集中在视频中的动作人物身上。在第3.1节中,我们提出的基于感知的视觉表示(PVR)作为前一种策略的替代。然后,在第3.2节中讨论了用于时间动作建议生成的边界匹配模块。
Perception-based Visual Representation (PVR):
PVR模块旨在根据人类如何感知一个动作来提取视频视觉表示,即识别每个时间段的主要参与者以及主要参与者和环境之间的交互,以指定动作的开始和结束。PVR由三个主要组成部分组成:(i)环境spectator;(ii)演员spectator;(iii)演员的环境互动spectator。PVR的总体架构如下图所示。
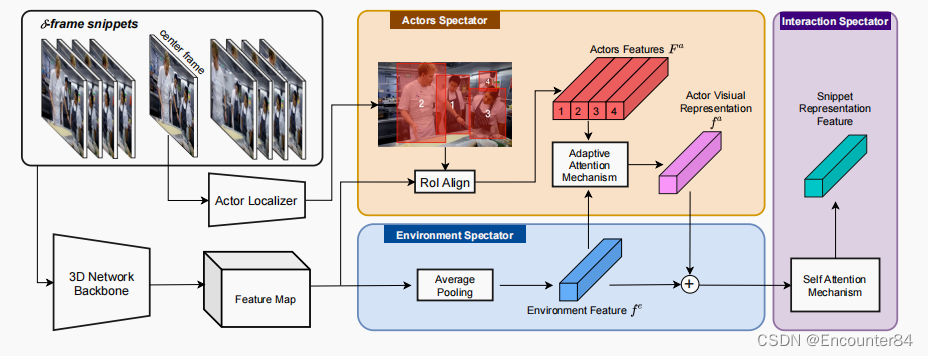
(i)环境观察者的目的是提取输入的δ-frame代码片段的全局语义信息。为了提取代码片段的时空细节,我们采用了一个预先训练过的动作识别基准数据集的三维网络作为骨干特征提取器。通过三维网络的所有卷积块对该片段进行处理,得到一个特征图M,然后,利用一个平均池化算子生成一个时空特征向量fe。
(ii)演员观察者的目的是语义提取。在没有人(演员)的情况下,一个行动不能发生。演员旁观者通过一个演员定位模块检测代码片段中所有现有的演员。然后,提出了一种自适应注意机制(AAM),自适应选择任意数量的主参与者(s),提取它们的相互关系,将它们表示为单一特征向量。
Actor Localization:
为了在δ-frame片段中定位所有参与者,我们在其中间帧上应用Human检测器,

Adaptive Attention Mechanism (AAM)::给定NB检测到的行动者,只有少数被检测到的行动者(称为主要行动者)实际上对行动做出了贡献。因为主要参与者的数量是未知的,并且在整个输入视频中不断变化,我们提出了一种自适应注意机制(AAM),它继承了自适应硬注意的优点,选择任意数量的主要参与者,以及一种软自注意机制来提取它们之间的关系。AAM算法如下图所示;
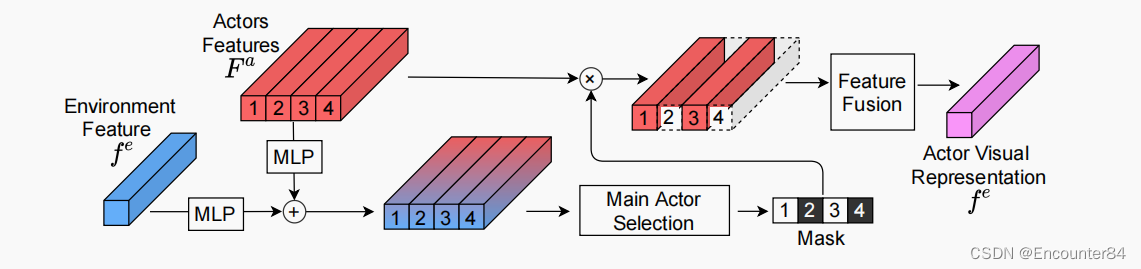
(iii) Actors-Environment Interaction Spectator
该模块旨在对环境特征和行为者表示特征之间的关系进行建模,然后将它们组合为单个特征f。在此,我们采用自注意模型,其中fe和fa是输入。我们将fi表示为代码片段si的视觉表示。
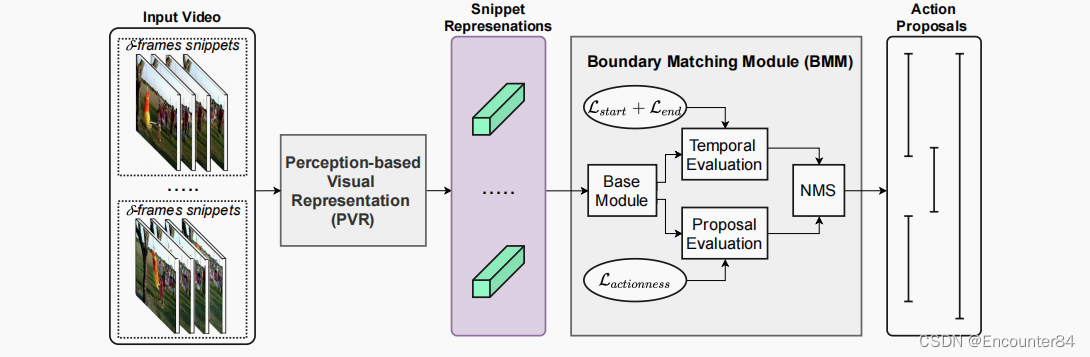
Boundary-Matching Module (BMM)

在推理阶段,我们通过PS和PE进行搜索,选择PiS或PiE为局部最大值的时间位置i,分别形成潜在的起始和结束时间位置集。然后,从满足时间约束的列表中配对开始和结束位置形成候选提案。基于候选提案的时间戳和分数,我们最终应用NMS来生成最终的行动提案集。
在我们的论文中,我们在两种不同的网络架构下进行了BMM:基于CNN的和基于GCN的。我们基于CNN的BMM,称为AEI-B,其中基本模块由一维卷积层组成,以学习和提取片段之间的时间关系。另一方面,我们的基于GCN的BMM,称为AEI-G,不仅可以用来提取局部关系,而且还可以提取共享相近语义特征的片段之间的关系。















 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









