







论文地址:https://arxiv.org/pdf/2107.12960.pdf
Abstract
有效地解决时间动作定位(TAL)问题需要一个共同追求两个混杂目标的视觉表征,即时间定位的细粒度识别和动作分类的足够的视觉不变性。我们通过在流行的两阶段时间定位框架中丰富局部和全局上下文来解决这一挑战,在该框架中,首先生成行动建议,然后进行行动分类和时间边界回归。我们提出的模型,称为ContextLoc,可分为三个子网:L-Net、G-Net和P-Net。L-Net通过对代码片段级特性的细粒度建模,丰富了本地上下文,这被表述为一个查询和检索过程。G-Net通过对视频级表示的更高层次的建模,丰富了全局上下文。此外,我们引入了一个新的环境适应模块,以适应全球环境适应不同的建议。P-Net进一步模拟了上下文感知的proposal间关系。
Introduction
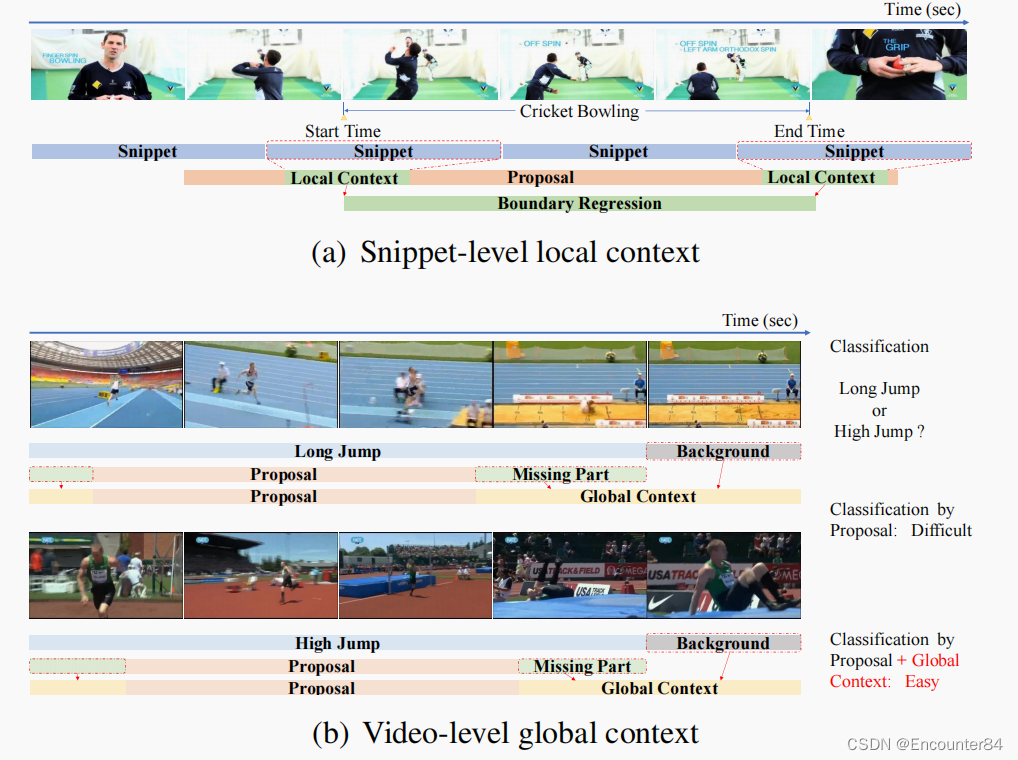
本地上下文是指proposal中的snippets。它们包含对本地化至关重要的细粒度时间信息。如上图所示,我们通过打保龄球和接球板球的时刻来定位动作“板球保龄球”的边界。因此,正是捕获这些特殊时刻的代码片段促进了在时域中的定位。然而,先前的方法通过将时间最大池化应用于proposal中的snippets的特征来获得proposal的特征,这不可避免地丢弃了细粒度的时间信息。
全局上下文指的是整个视频。它提供了补充行动分类建议的特征的鉴别信息。如上图所示,为了区分“跳远”和“跳高”,我们不仅需要检查动作持续时间的最后几帧,还需要检查持续时间之外的背景帧。此外,全局上下文提供了高级活动信息,对应该出现的操作类别执行强有力的优先执行。例如,它不太可能在一段关于家庭活动的视频中看到体育活动。不幸的是,视频级别的全局背景在很大程度上被现有的TAL模型忽略了。
我们引入了一种新的网络架构,称为上下文Loc,以在TAL的统一框架中建模局部和全局上下文。它由三个子网络组成:LNet、G-Net和P-Net。受自注意的启发,LNet执行了一个查询和检索过程。但与自我注意不同的是,L-Net中的查询、键和值对应于不同的语义实体,它们是专门为丰富本地上下文而设计的。具体来说,将提案的特征向量作为查询来匹配该提案中片段的关键特征向量,以便可以检索本地上下文中的相关细粒度值并聚合到该提案中。具体来说,将提案的特征向量作为query来匹配该提案中片段的key特征向量,以便可以检索本地上下文中的相关细粒度values并聚合到该提案中。
G-Net通过整合每个提案的视频级表示和特征来为全局环境建模。此外,需要加强的不同建议所需的背景部分是不同的。为了有效地将视频级信息与提议级特征相结合,我们提出了全局上下文自适应方案。它关注每个提案中的本地上下文的视频级表示,以便全局上下文分别适应它们。
P-Net模型是基于上下文感知的建议间关系。这包括由本地上下文增强的提案级特性之间的交互,以及适应不同提案的全局上下文之间的交互。我们使用一个现有的模型作为P-Net,并研究了两个候选模型:PGCN[44]和非本地网络[40]。
本文的贡献总结如下:
据我们所知,这是第一个尝试利用snippet级本地上下文和视频级全局上下文来在两阶段TAL框架中增强提案级特性的工作。
我们介绍了一种新的网络架构,称为ContextLoc,由三个子网络组成,即LNet、G-Net和P-Net。L-Net是第一个使用提议来查询其中的片段并检索本地上下文以用细粒度的时间信息补充它的提议。G-Net通过集成视频级表示来增强每个方案的特性。我们引入了一种新的环境适应过程来适应全球环境,以适应不同的建议。虽然P-Net是建立在现有网络上的,但我们证明了P-Net,无论其实例化如何,都是对我们的L-Net和G-Net的补充。我们的上下文Loc统一了这三个子网络各自的优势,实现了更有效的TAL。
The ContextLoc Model
Overview
**Problem statement:**我们的上下文Loc的输入是一个未修剪的视频,由N个不重叠的片段组成。每个代码片段都是少量的连续帧。我们使用I3D网络从每个片段中提取特征。
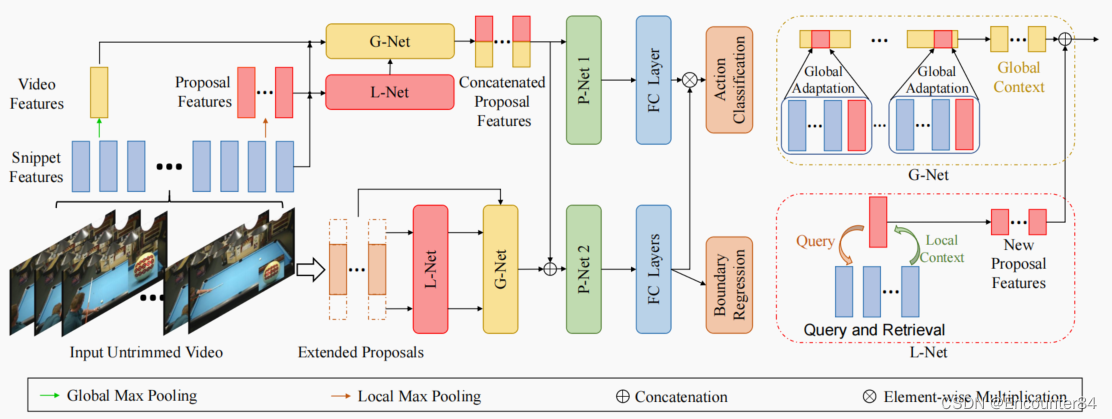
**Multi-level representations:**如上图所示,ContextLoc显式地建模了三个不同级别的表示:片段级表示(本地上下文)、提案级表示和视频层表示(全局上下文)。这些提案由BSN获得,每个提案i都有一个开始时间和一个结束时间。第i个提案的初始特征,记为yi,是通过在其持续时间的时间内对片段级特征进行最大池化而获得的,其中S(i)表示持续时间在第i个提案的开始时间和结束时间之间的片段。同样,初始的视频级特征,表示为z,是通过时间最大池化视频中的所有片段级特征得到的。
**Network architecture:**ContextLoc由三个子网络组成:L-Net、G-Net和P-Net。它们分别通过本地上下文、全局上下文和上下文感知的提案间关系来增强每个提案的表示。在之前的工作之后,我们还将ContextLoc应用于每个延长时间持续时间的扩展提案。原始方案的最终表示用于动作分类(通过一个全连接层),而扩展方案的最终表示用于完整性预测和时间边界细化。这些分类和完整性分数是元素明智地相乘,以做出最终的分类预测。
L-Net
通过时间最大池化获得的proposal的初始特征是不够的,因为对定位至关重要的细粒度时间信息丢失了。L-Net通过在提案中找到与之最相关的代码片段并聚合它们以保留信息特性来解决这个问题。我们将这些片段称为本地上下文,因为它们的时间范围在提案中,而且它们处于较低的语义级别。
受自注意的启发,L-Net执行了一个查询和检索过程。查询、键和值分别是每个提案的特性、每个提案中的代码片段的特性以及这些代码片段的转换特性。具体来说,一个query proposal与此proposal中的key snippets相匹配,以便可以检索本地上下文中的相关细粒度values并聚合到此proposal中。这是通过在查询和键之间建立一个注意力映射,然后根据注意力权重聚合值来实现的。
Attention map:
一个proposal i和一个snippet j∈S(i)之间的注意权重度量了它们的相关性,并决定了将从这个代码片段中检索到多少信息。计算方法为:

其中σ为ReLU函数,s是两个向量之间的余弦相似度。ReLU函数将负相似度值设置为0。因此,在检索过程中将忽略这些不相关的片段。Normalization确保了所有代码片段的注意力权重之和为1。
Local context aggregation:
我们首先通过一个全连接的层转换每个snippet的特征来计算values,然后通过注意力权重将它们线性组合。该本地上下文最终与proposal的转换特性进行聚合,以获得该提案的新表示:

其中,
y
i
L
y_i^L
yiL∈
R
D
/
2
R^{D/2}
RD/2是一个新的携带细粒度时间信息的proposal-level表示,σ是ReLU函数,
W
1
L
W_1^L
W1L,
W
2
L
W_2^L
W2L∈
R
(
D
/
2
)
×
D
R^{(D/2)×D}
R(D/2)×D是可训练的权重。在实践中,我们发现将从所有片段中汇集的特性作为一个特殊的片段,并将其包含在S(i)中可以略微提高性能。
G-Net (Global Context)
视频级的全局上下文很重要,因为它涉及到背景和高级活动信息,这些信息对于区分具有相似外观和运动模式的动作类别至关重要。丰富全局上下文的一种直接方法是将视频级别的表示z和每个提案的特性连接起来.然而,这是不够的,因为全局表示不仅包含相关的上下文,而且还包含不相关的噪声。
Global context adaptation:
为了使全局上下文适应第i个proposal,我们首先将视频级的表示z应用到这个提议yi的特征中,以及其中的片段级特性{xj:j∈S(i)}:

其中,
a
i
,
j
G
a_{i,j}^G
ai,jG是视频级表示与第i个提案的第j个片段之间的注意权重,
b
i
G
b_i^G
biG是视频级表示与第i个提案之间的注意权重。利用注意权重,通过

其中
z
i
G
z_i^G
ziG∈
R
D
/
2
R^{D/2}
RD/2是适应第个提案的全球背景,
W
1
G
W_1^G
W1G,
W
2
G
W_2^G
W2G∈
R
(
D
/
2
)
×
D
R^{(D/2)×D}
R(D/2)×D是可训练的权重。
Global context aggregation:
最后,G-Net连接了适应第i个提案的全局背景,即
z
i
G
z_i^G
ziG∈
R
D
/
2
R_{D/2}
RD/2,以及从L-Net获得的该提案的特征,即
y
i
L
y_i^L
yiL∈
R
D
/
2
R_{D/2}
RD/2:

其中,⊕表示连接,
y
i
G
y_i^G
yiG∈
R
D
R^D
RD是第i个提案的G-Net的输出。
P-Net (Inter-proposal Relations)
P-Net接受
y
i
G
y_i^G
yiG作为输入,并为每个提案输出一个新的表示形式。我们使用一个现有的模型作为P-Net,并研究了两个候选模型:P-GCN和non-local network。
P-GCN构造了一个行动proposal图。每个proposal都被作为一个节点。关系边有两种类型。一个连接重叠的提案,另一个连接不同但附近的提案。然后,应用GCN对proposal级特性的关系进行更新。与P-GCN不同,non-local network对所有proposal建立一个完整的图,并根据它们的成对相似性动态计算边缘权值。我们将深入调查它们作为我们的背景逻辑中的构建模块的有效性。
Extended Proposals
TAL中的一个common practice是将proposal的两端都进行延长(例如延长50%的时间范围)。原先的一些方法比如P-GCN将延长的proposal作为单一proposal独立于原始proposal,然而该策略不适用于l-net和g-net。一方面来说,设置扩展提案的特征维度远远超过原始提案,增加了时间持续时间,但显著增加了模型复杂性。另一方面,将扩展提案的特征维度设置为与原始提案相同,会导致性能较差。此外,还对扩展方案和原方案分别进行了处理。它们的内部联系(即,最初的提案是扩展提案的一部分)被忽略了。
为了解决这个问题,我们将扩展提案视为L-Net和G-Net中的三个提案,即原提案和双方的扩展区域。每个扩展区域的持续时间比原提案的持续时间长50%。
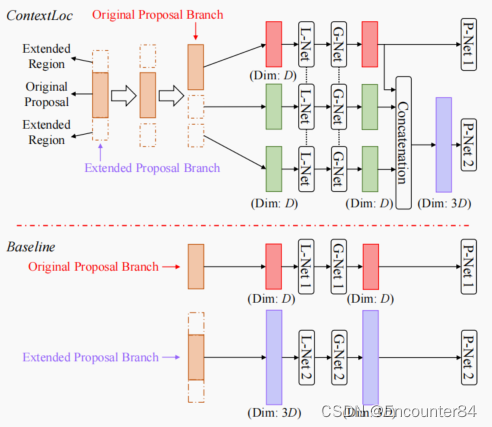
如上图所示,L-Net和G-Net分别处理这三个proposals,但使用共享的权重。然后,我们将它们的新表示形式连接起来。最后,P-Net,即上图中的“P-Net2”,将扩展提议视为单一的提议,并处理这些连接的特性。注意L-Net和G-Net原始proposal的处理现在是延长的proposal的处理的一部分。这不仅降低了模型的大小和计算复杂度,而且反映了原始方案和扩展方案之间的联系。















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









