







本文首发于微信公众号 CVHub,不得以任何形式转载到其它平台,仅供学习交流,违者必究!

Title: VoxFormer: Sparse Voxel Transformer for Camera-based
3D Semantic Scene Completion
Paper: https://arxiv.org/pdf/2302.12251.pdf
Code: https://github.com/nvlabs/voxformer
导读

从视觉图像估计场景中完整的几何结构和语义信息对于认知和理解至关重要。为了在人工智能系统中实现这种能力,论文提出了VoxFromer,一个基于Transformer的语义场景补全(SSC,Semantic Scene Completion)框架,可以仅从二维图像中预测空间中的体素占据和类别信息。VoxFromer的框架采用两阶段设计,首先从深度估计得到一组稀疏的可见和占据的体素查询,然后进从稀疏体素生成密集的三维体素。这种设计的一个关键思想是,二维图像上的视觉特征仅对应于可见的场景结构而不是被遮挡或空的空间,因此,从可见结构的特征化和预测开始更加可靠。一旦获得稀疏查询集,VoxFromer采用一个带掩膜的自编码器设计,通过自注意力将信息传播到所有的体素中。在SemanticKITTI数据集上的实验结果表明,VoxFormer在几何和语义方面的相对改进分别达到20.0%和18.1%,并且在训练期间将GPU内存减少了约45%,降至不到16GB。
研究背景
仅从视觉图像进行完整的3D场景理解是自动驾驶汽车感知中的一个重要问题,它直接影响规划和地图构建等下游任务。然而受限于传感器有限的视野和场景物体的遮挡,获得真实世界的准确和完整的3D信息是⼀项具有挑战性的任务。
为了应对这些挑战,语义场景补全(Semantic Scene Completion, SSC)被提出来,其从有限的观察中联合推断完整的场景几何和语义。SSC解决方案必须同时解决两个子任务:可见区域的场景重建和遮挡区域的场景推断。
现有的基于视觉方案的SSC,如MonoScence,使用密集特征投影将2D图像输入提升为3D。然而,这样的投影不可避免地会将可见区域的2D特征分配给空的或被遮挡的体素。例如,被汽车遮挡的空体素仍将获得汽车的视觉特征。结果,生成的3D特征包含许多歧义,无法用于后续的几何补全和语义分割,导致性能不尽如人意。
贡献
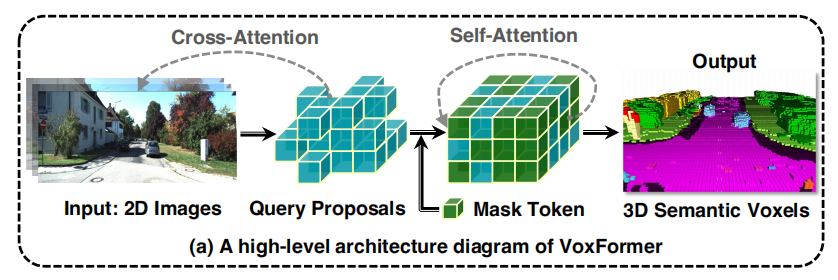
与MonoScene不同,VoxFormer考虑3D到2D交叉注意力来表示稀疏查询。所提出的设计受到两个见解的启发:
- **遮挡区域场景推断:**以重建的可见区域作为起点,可以更好地完成不可见区域的三维信息
- **稀疏三维空间表示:**由于三维空间大量的体素通常是不被占用的,使用稀疏表示而不是密集表示肯定更有效和可伸缩
VoxFormer的主要贡献如下:
- 一种新颖的两阶段框架,将图像提升到一个完整的3D体素化语义场景
- 一种基于2D卷积的新型查询提议(query proposal)网络,可以从图像深度生成可靠的查询
- 一种新的Transformer类似于掩蔽自编码器(MAE),产生完整的3D场景表示
- VoxFormer在SemanticKITTI 的SCC任务上取得SOTA
方法
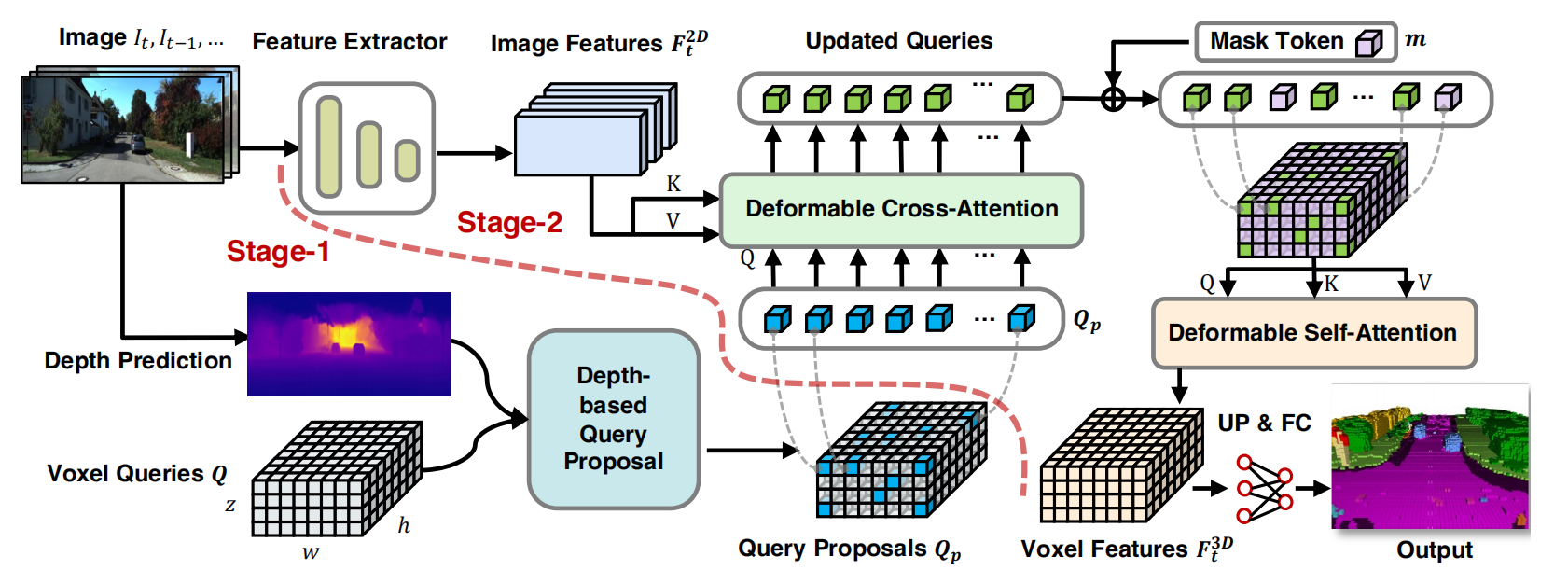
VoxFormer框架分为两阶段,第一阶段为类不可知(class-agnostic)的查询提议,第二阶段为类特定(class-specific)的语义分割。具体来说:
- 阶段一包含一个轻量级的基于2D CNN的查询提议网络,使用图像深度来重建场景的几何形状,从可学习体素查询中得到一个稀疏的体素。
- 阶段二是一个新的稀疏到密集的类似于MAE的架构,如上图所示,它首先通过与图像的Cross-Attention增强体素的特征,然后将未提出的体素与一个可学习的掩码标记相关联,并将整个体素集进行自注意处理,以完成逐体素语义分割的场景表示。
Stage-1: Class-Agnostic Query Proposal
Depth estimation
论文利用现有的单目深度估计网络得到每个像素点 ( u , v ) (u,v) (u,v)的深度 Z ( u , v ) Z(u,v) Z(u,v),然后将预测的深度图 Z Z Z反向投影到点云中:
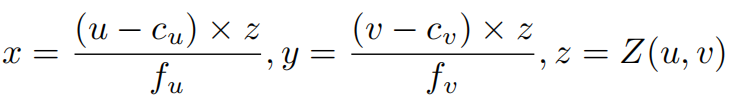
Depth correction
上述的深度估计质量较差,论文使用一个lightweight的UNet风格网络 Θ o c c \Theta_{o c c} Θocc来预测较低空间分辨率下的体素占用图,以帮助矫正图像深度。首先将点云转换为一个体素网格图 M i n ∈ { 0 , 1 } H × W × Z \mathbf{M}_{i n} \in\{0,1\}^{H \times W \times Z} Min∈{0,1}H×W×Z,输入 M out = Θ occ ( M in ) \mathbf{M}_{\text {out }}=\Theta_{\text {occ }}\left(\mathbf{M}_{\text {in }}\right) Mout =Θocc (Min ) 得到低分辨率的 M out ∈ { 0 , 1 } h × w × z \mathbf{M}_{\text {out }} \in\{0,1\}^{h \times w \times z} Mout ∈{0,1}h×w×z。因为较低的分辨率对深度错误更鲁棒
Query proposal
经过深度校正后,得到基于深度图转点云输出的二进制 M out \mathbf{M}_{\text {out }} Mout 的query proposals Q p \mathbf{Q}_p Qp:
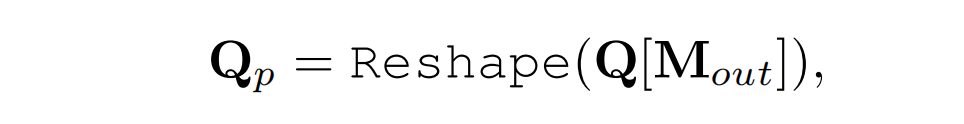
Stage-2: Class-Specific Segmentation
Deformable attention
在阶段1之后,可以通过query proposals Q p \mathbf{Q}_p Qp来关注图像特征,以学习3D场景中丰富的视觉特征。为了提高效率,论文提出deformable attention:参考点与局部感兴趣区域相互作用,即只在参考点的邻域采样点 N s N_s Ns来计算注意力结果。每个3D的query q将由以下一般方程进行更新:

其中 p p p表示query点投影到2D图像上对应的2D参考点, F F F表示2D图像输入特征, s s s为 N s N_s Ns点索引。 W s W_s Ws表示值生成的可学习的权重, A s A_s As的注意力权重。 δ p s δp_s δps是邻域采样点相对于参考点在2D图像上的预测偏移量,而 F ( p + δ p s ) F(p+δp_s) F(p+δps)是通过双线性插值提取的特征。
Deformable cross-attention
对于3D空间中每个proposed query,通过投影矩阵得到在的输入的连续帧 V t \mathcal{V}_t Vt中的位置,对连续帧这些位置的特征进行加权和,作为可变形交叉注意力的输出:
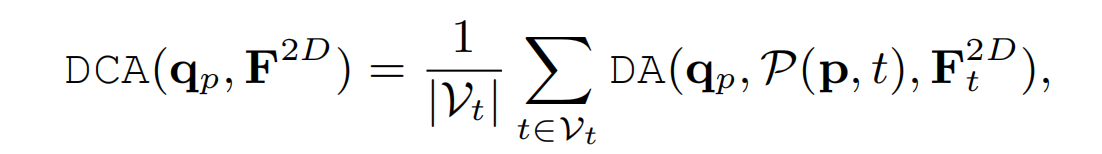
Deformable self-attention
在经过几层可变形的交叉注意之后,proposed query将被更新为 Q ^ p \hat{\mathbf{Q}}_p Q^p。结合更新后的proposed query和mask tokens得到初始体素 F 3 D ∈ R × h × w × z × d \mathbf{F}^{3 D} \in \mathbb{R}^{\times h \times w \times z \times d} F3D∈R×h×w×z×d,然后使用可变形自注意力得到精细化的体素 F ^ 3 D ∈ R × h × w × z × d \hat{\mathbf{F}}^{3 D} \in \mathbb{R}^{\times h \times w \times z \times d} F^3D∈R×h×w×z×d:
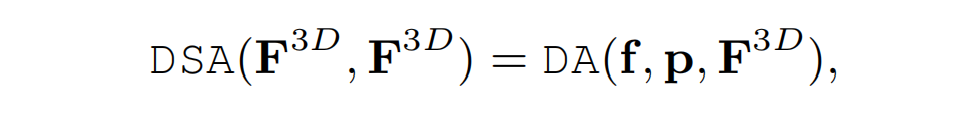
Output Stage
在获得细化的体素特征 F ^ 3 D \hat{\mathbf{F}}^{3 D} F^3D后,将其上采样并投影到输出空间,得到最终的输出 Y t ∈ R H × W × Z × ( M + 1 ) {\mathbf{Y}}_t \in \mathbb{R}^{ H \times W \times Z \times {(M+1)}} Yt∈RH×W×Z×(M+1),M+1表示M个语义类和一个空类
实验
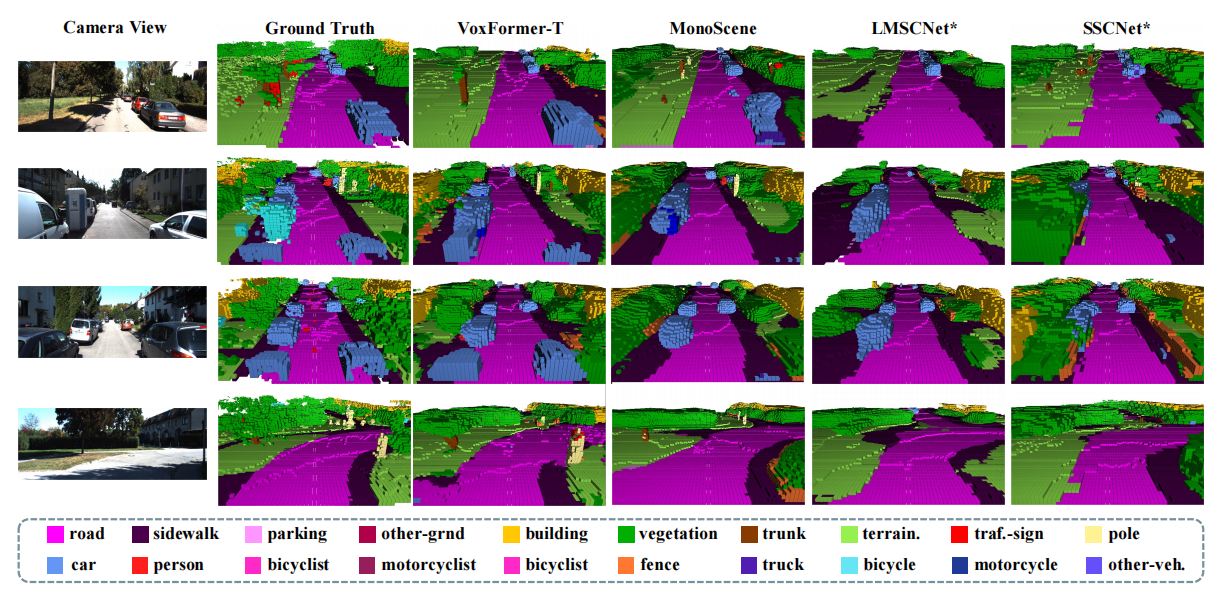
在大型自动驾驶场景中,VoxFormer可以更好地捕捉场景的布局。同时,在树干、杆等小物体方面表现出满意的性能。
Comparison against camera-based methods
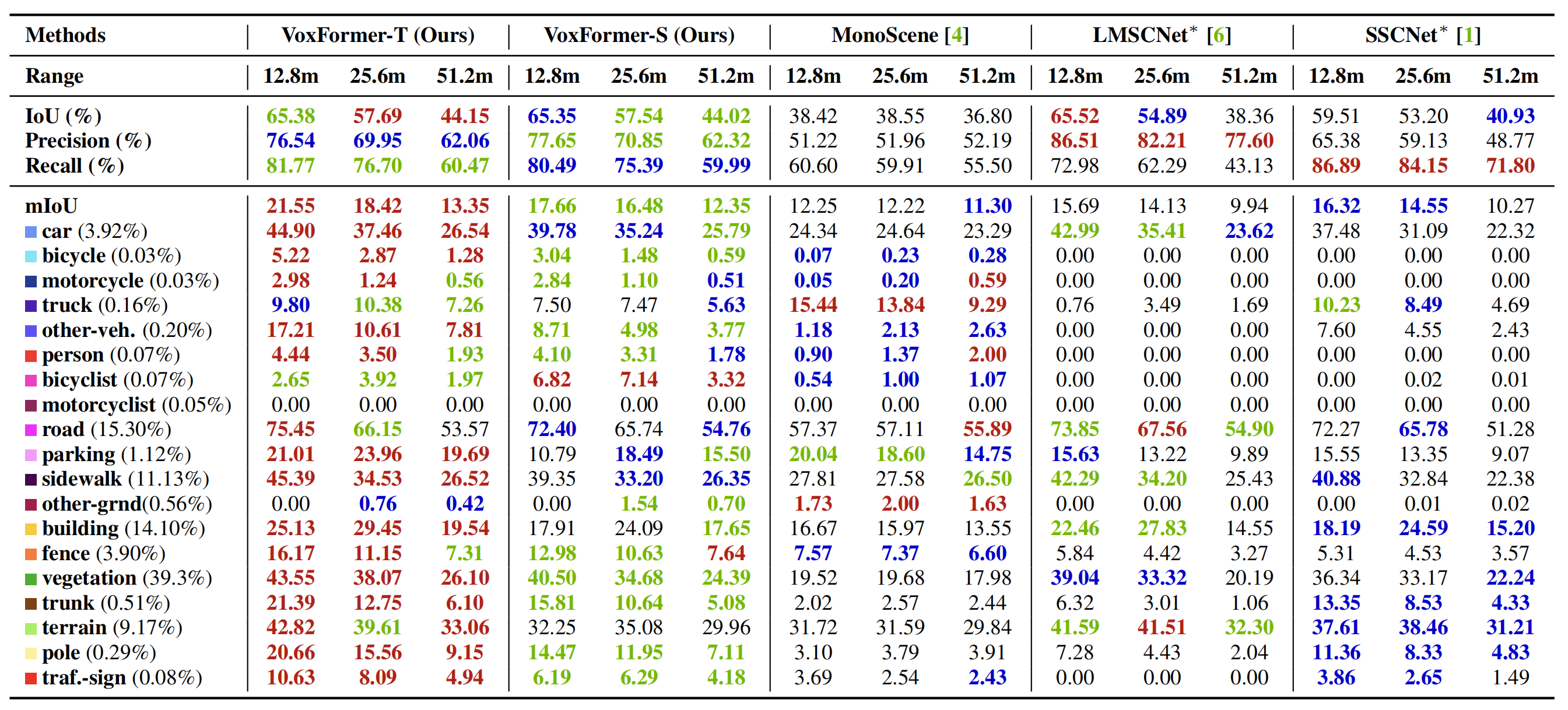
如上表所示:
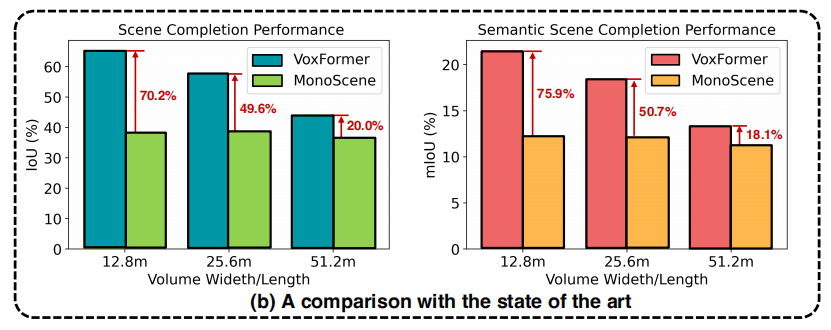
- VoxFormer-S在几何补全方面大大优于MonoScene(36.80->44.02,19.62%)。如此大的改进源于阶段1,它具有明确的深度估计和校正,减少了查询过程中的大量空白。
- 具有时域信息VoxFrorer-T进一步提高了的VoxFrorer-S的SSC性能
- VoxFormer在自动驾驶安全关键的短程领域比其他基于相机的方法有了显著的改进
- VoxFormer在小物体上的更具优势
- VoxFormer在模型大小和GPU显存上都优于MonoScene
Comparison against LiDAR-based methods
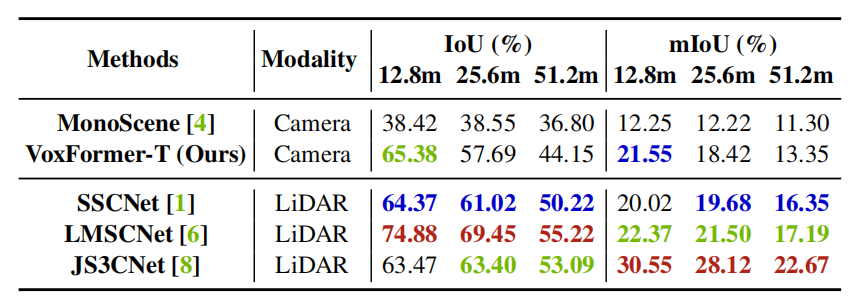
如上表所示,目标距离越近,VoxFormer-T和最先进的基于激光雷达的方法之间的性能差距越来越小。
Ablation studies
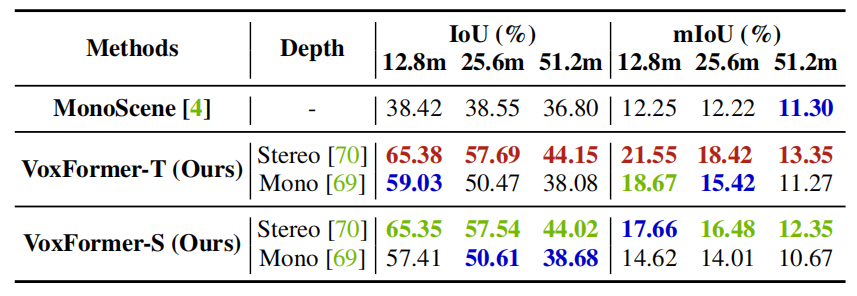
上表可以看出,基于双目的方法效果由于单目方法,因为前者利用了外极性几何结构,但后者依赖于模式识别。
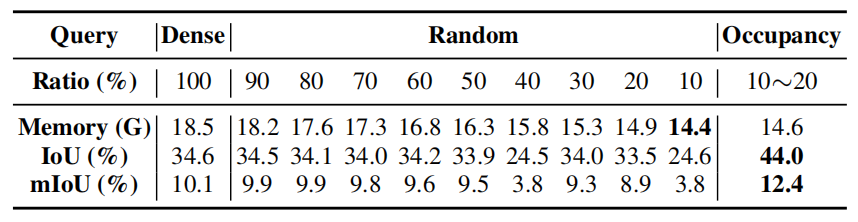
上表可以看出:
- 密集查询(在第二阶段中使用所有体素查询)消耗了大量内存且比占用查询效果更差
- 随机查询效果不稳定,与占用查询有较大差距
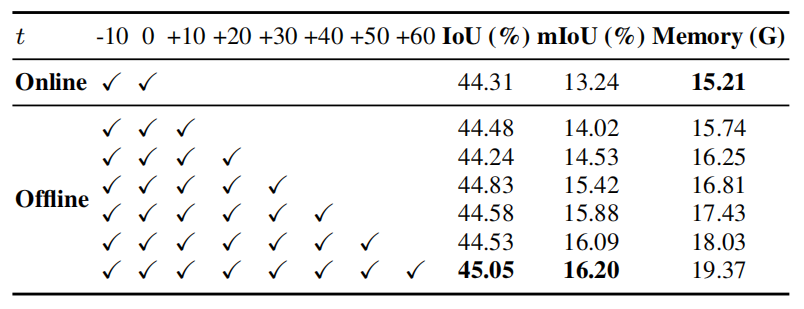
上表可以看出,时序连续帧输入可以提高性能
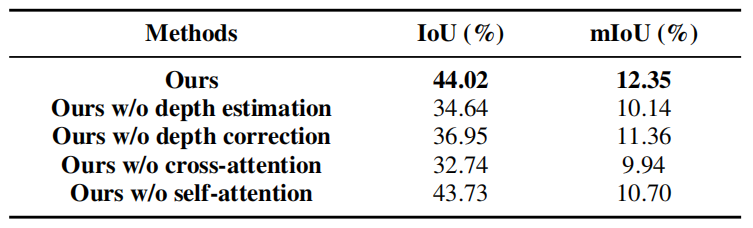
上表可以看出,对于阶段1,深度估计和校正都很重要,因为一组合理的体素查询可以为完整的场景表示学习奠定良好的基础。对于第二阶段,自注意和交叉注意可以通过启用voxel-to-voxel和voxel-to-image的交互来帮助提高性能。
总结
在本文中,作者提出了VoxFormer,一个强大的三维语义场景补全(SSC)框架,由(1)基于深度估计的类不可知查询提议和(2)类特定分割的稀疏到密集的类设计。VoxFormer优于最先进的基于相机的方法,甚至与基于激光雷达的方法相当。作者希望VoxFormer能激发基于摄像机的SSC及其在自动驾驶感知中的应用。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!
同时欢迎添加小编微信: cv_huber,备注CSDN,加入官方学术|技术|招聘交流群,一起探讨更多有趣的话题!

















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











