







customer purchases can use this information to automatically detect groups of customers
with similar buying patterns, in addition to regular demographic information.
blogs can be grouped according to their text
Techniques that use example inputs and outputs to learn how to make predictions
are known as supervised learning methods. Many supervised learning
methods includes neural networks, decision trees, support-vector
machines, and Bayesian filtering.
Clustering is an example of unsupervised learning. Unlike a neural network or a decision
tree, unsupervised learning algorithms are not trained with examples of correct
answers. Other examples of unsupervised
learning include non-negative matrix factorization
By clustering blogs based on word frequencies, it might be possible to determine if
there are groups of blogs that frequently write about similar subjects or write in similar
styles. Such a result could be very useful in searching, cataloging, and discovering
the huge number of blogs that are currently online.
Hierarchical Clustering
Hierarchical clustering builds up a hierarchy of groups by continuously merging the two most similar groups. In each iteration this method calculates the distances between every
pair of groups, and the closest ones are merged together to form a new group. This is
repeated until there is only one group.

After hierarchical clustering is completed, you usually view the results in a type of
graph called a dendrogram, which displays the nodes arranged into their hierarchy.
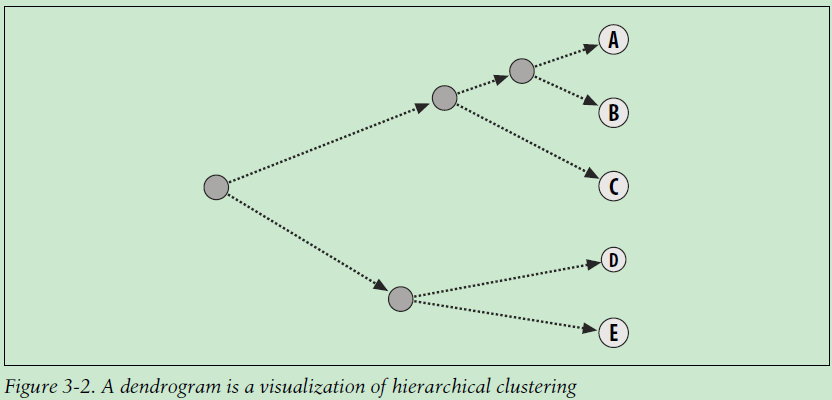
This dendrogram not only uses connections to show which items ended up in each
cluster, it also uses the distance to show how far apart the items were. The AB cluster
is a lot closer to the individual A and B items than the DE cluster is to the individual
D and E items. Rendering the graph this way can help you determine how similar the
items within a cluster are, which could be interpreted as the tightness of the cluster.
Hierarchical clustering gives a nice tree as a result, but it has a couple of disadvantages.
The tree view doesn’t really break the data into distinct groups without
additional work, and the algorithm is extremely computationally intensive. Because
the relationship between every pair of items must be calculated and then recalculated
when items are merged, the algorithm will run slowly on very large datasets.
An alternative method of clustering is K-means clustering.















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









