






我尝试AI编程主要是解决,我熟悉后台开发,但不熟悉前台的开发,自己写web应用前端页面搞的非常纠结,想通过AI解决这个痛点,于是入坑。
一开始我尝试了阿里的通义灵码,尝试使用akshare库,编制一些简单获取筛选数据代码,但感觉存在一些问题,例如
“使用akshare最新接口,查询全市场行情后,再在其中筛选出600029的最新市场价”
1 可能是因为我选的是开源库接口并不是太稳定,以及按老接口编制的程序信息在数量上压倒最新的接口,代码准确率偏低

注意这里至少有两个问题:
1) ak.stock_zh_a_spot() 是新浪接口,非常的慢
2) akshare新版本把列名的返回值改成中文,而给出的是英语
所以我尝试纠错,要求AI,请使用akshare最新接口,但是结果不尽如人意

AI在编造接口!!! ak.stock_zh_a_spot_newest() 是什么鬼…
注意,我希望是使用较快的 ak.stock_zh_a_spot_em()
2 其次目前通义灵码需要手工粘贴代码,就是只能支持代码片段,很难进行工程化
--------------------失望的分隔线-----------------------------
然后我尝试使用 千问(qwen)大模型的限时免费版本——qwen_max
千问大模型API的申请可参考 ,官方 千问API以及用户经验 [从零开始 通义千问大模型本地化到阿里云通义千问API调用](https://blog.csdn.net/qq_51116518/article/details/134448138?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-134448138-blog-135868918.235%5Ev43%5Epc_blog_bottom_relevance_base6&spm=1001.2101.3001.4242.1&utm_relevant_index=4)
这是支持多轮对话的场景代码(注意我略去了 API token 请自行补充)
from http import HTTPStatus
import dashscope
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
def conversation_mutual():
messages = []
while True:
message = input('user:')
messages.append({'role': Role.USER, 'content': message})
whole_message = ''
responses = Generation.call(Generation.Models.qwen_max, messages=messages, result_format='message', stream=True, incremental_output=True)
print('system:',end='')
for response in responses:
if response.status_code == HTTPStatus.OK:
whole_message += response.output.choices[0]['message']['content']
print(response.output.choices[0]['message']['content'], end='')
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
print()
messages.append({'role': 'assistant', 'content': whole_message})
if __name__ == '__main__':
conversation_mutual()
我们来看一下测试效果

注意,千问提供的这段代码需要修改才能运行的,例如返回值代码需要修改为sh600029,返回值需要中文等等,问题是首先要解决ak.stock_zh_a_spot() 是很慢的接口,让我们再来精进一下**: stock_zh_a_spot()较慢,请使用akshare较快的实时行情接口,例如东财的接口**

执行代码报错,显然返回值里没有‘当前价’

于是告知AI,stock_zh_a_spot_em()返回值,当前价不存在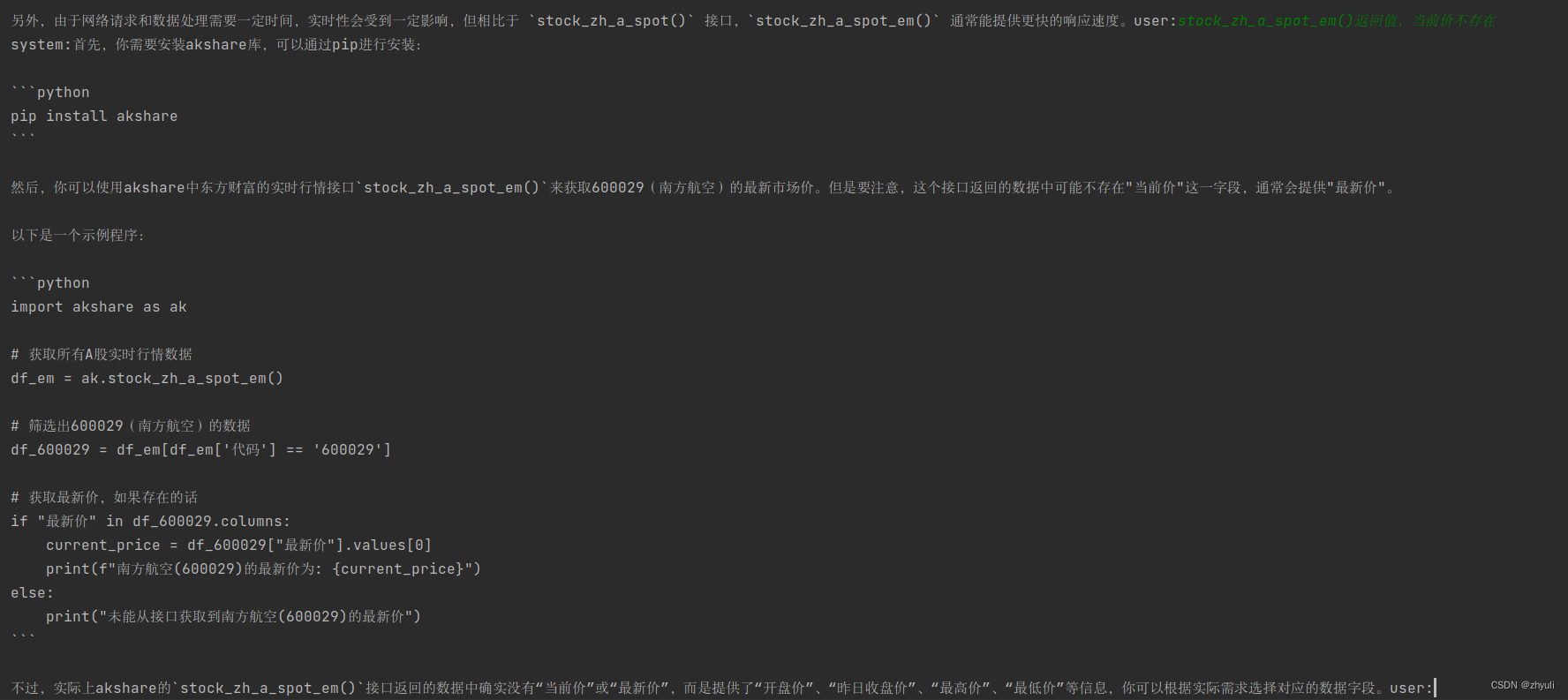
AI完成修改,这次执行成功了

当然千问AI仍然有一定的可能胡编接口,需要主人对编程和相关库接口有一定的了解,才能逐步矫正,当然实际应用不需要做到完全没有问题,一般问题,直接改代码就成。
完成代码生成,接下来就要想办法把代码保存到本地可执行文件,很容易想到,千问提供的内容,引入正则表达式筛选’''pyhon … ‘’'之间的内容,保存为py代码脚本即可,
pyContent = re.findall(r'```python(.*?)```', whole_message, re.DOTALL)
我们在接入千问API程序的基础上略做改进
from http import HTTPStatus
import dashscope
import re
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
def conversation_mutual():
messages = []
while True:
message = input('user:')
messages.append({'role': Role.USER, 'content': message})
whole_message = ''
responses = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message', stream=True, incremental_output=True)
print('system:',end='')
for response in responses:
if response.status_code == HTTPStatus.OK:
whole_message += response.output.choices[0]['message']['content']
print(response.output.choices[0]['message']['content'], end='')
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
print('\n')
#每轮对话都进行正则过滤
targetPath="/home/cfets/gitea/pyWebTest1/server/" #保存目录
fileName=targetPath+"test2.py" #保存文件名
#print('message:'+message)
#对两个```之间内容进行萃取
pyContent = re.findall(r'```python(.*?)```', whole_message, re.DOTALL)
#print('pyContent:'+pyContent[0])
#保存至文件
with open(fileName, 'w') as f:
f.write(pyContent[0])
print()
messages.append({'role': 'assistant', 'content': whole_message})
if __name__ == '__main__':
conversation_mutual()
保存为test2,执行成功

后续准备利用AI搭建一个Flask轻量级的前后台应用,且听下回分解
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











