







论文解读:Dynamic Fusion Network for Multi-Domain End-to-end Task-Oriented Dialog
作者:Libo Qin, Xiao Xu, Wanxiang Che, Yue Zhang, Ting Liu
题目翻译:用于多域端到端任务导向对话的动态融合网络
摘要
最近的研究表明,在端到端的面向任务的对话系统中取得了巨大的成功。但是,大多数神经模型都依赖于大型训练数据,这些数据仅可用于一定数量的任务域,例如导航和调度。这使得很难为具有有限标签数据的新域进行扩展。但是,关于如何有效地使用来自所有域的数据来改善每个域以及未看见域的性能的研究相对较少。为此,我们研究了可以显式使用领域知识并引入共享-专用网络以学习共享和特定知识的方法。此外,我们提出了一种新颖的动态融合网络(DF-Net),该网络可自动利用目标域与每个域之间的相关性。结果表明,我们的模型在多域对话方面的表现优于现有方法,为文献提供了最新技术。此外,在训练数据很少的情况下,我们的性能比以前的最佳模型平均低13.9%。
1 介绍
面向任务的对话系统帮助用户实现特定目标,例如餐厅预订或导航查询。 近年来,文献中的端到端方法通常采用序列到序列(Seq2Seq)模型来产生对话历史记录的响应。 以图1中的对话框为例,为了回答驾驶员关于“加油站”的查询,端到端的对话系统根据查询和相应的知识库(KB)直接生成系统响应。

尽管端到端模型实现了令人鼓舞的性能,但它们依赖于大量标记数据,这限制了它们对新域和扩展域的有用性。实际上,我们无法为每个新域收集丰富的数据集。因此,重要的是考虑能够有效地将知识从具有足够标记数据的源域转移到具有有限标记数据或很少标记数据的目标域的方法。
现有工作可以分为两个主要类别。如图2(a)所示,第一部分工作简单地组合了多域数据集为了训练。此类方法可以隐式提取共享功能,但无法有效捕获特定领域的知识。如图2(b)所示,第二部分工作分别为每个域训练模型,可以更好地捕获特定域的特征。但是,这些方法会忽略不同域之间的共享知识(例如,位置字同时存在于计划域和导航域中)。
我们考虑通过显式地建模领域之间的知识联系来解决现有工作的局限性。尤其是,合并域共享和域私有功能的简单基准是共享私有框架。如图2(c)所示,它包括一个用于捕获域共享功能的共享模块和一个用于每个域的私有模块。该方法明确区分了共享知识和私有知识。但是,该框架仍然存在两个问题:(1)给定一个新的领域,其数据极少,私有模块可能无法有效地提取相应的领域知识。 (2)框架忽略了某些领域子集的细粒度相关性。 (例如,时间表域与导航的相关性要比天气域的相关性大。)

为了解决上述问题,我们进一步提出了一种新颖的动态融合网络(DF-Net),如图2(d)所示。与共享-私有模型相反,进一步引入了动态融合模块(请参见第2.3节)以明确捕获域之间的关联。特别是,利用门来自动找到当前输入与所有特定领域模型之间的相关性,以便可以为每个域分配权重以提取知识。编码器和解码器都采用了这种机制,并且存储器模块也采用了这种机制来查询知识库特征。给定一个几乎没有训练数据或没有训练数据的新域,我们的模型仍可以充分利用现有域,而基线模型是无法实现的。
我们对两个公开基准进行了实验,即SMD和Multi-WOZ 2.1。 结果表明,我们的框架始终显着优于当前的最新方法。 由于培训数据有限,我们的框架平均比以前的最佳方法要高13.9%。 据我们所知,这是在多域端到端任务导向对话中有效探索共享-私有框架的第一项工作。 另外,当给定一个新的域时,它的镜头数据很少或为零,我们扩展的动态融合框架可以利用细粒度的知识来获得所需的精度,从而使其更适合于新域。
2 模型架构
我们基于seq2seq对话生成模型(第2.1节)构建模型,如图3(a)所示。 为了明确集成域意识,如图3(b)所示,我们首先建议使用共享私有框架(第2.2节)来学习共享和相应的特定于域的功能。 接下来,我们进一步使用动态融合网络(第2.3节)来动态利用所有域之间的相关性以进行细粒度的知识转移,如图3(c)所示。 此外,还采用对抗训练来鼓励共享模块生成域共享功能。

2.1 Seq2Seq对话生成
我们将Seq2Seq面向任务的对话生成定义为根据输入的对话历史X和KB B查找系统响应Y。正式地,将响应的概率定义为
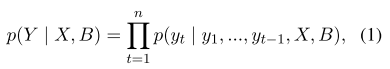
其中 yt代表输出令牌。在原始的Seq2Seq面向任务的对话系统中,长期记忆网络用于编码对话历史X =(x1,x2, …,xT)(T是对话历史中的令牌数量)以产生共享的上下文相关隐藏状态H =(h1,h2,…,hT):
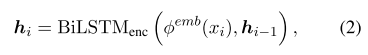
其中 φemb(·)表示单词嵌入矩阵。 LSTM还用于通过解码器隐藏状态(hdec,1,hdec,2,…,hdec,t)重复预测输出(y1,y2,…,yt-1)。对于 yt的生成,模型首先在编码表示 H 上计算对话历史的专注表示 h’dec,t 。然后,通过 U 将 hdec,t和 h’dec,t的级联投影到词汇空间V中:
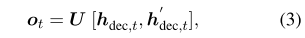
其中 ot 是下一代令牌的分数(logit)。下一个令牌 yt∈V的概率最终计算为:
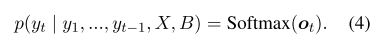
与使用Seq2seq模型生成的典型文本不同,面向任务的对话系统的成功对话很大程度上取决于准确的知识库(KB)查询。我们采用全局到本地内存指针机制(GLMP)(Wu et al。,2019a)来查询以KB为单位的实体,这显示了最佳性能。 建议使用外部知识存储器来存储知识库(KB)B和对话历史记录X。KB存储器用于知识源,而对话存储器用于直接复制历史单词。 外部知识存储器中的实体以三元格式表示,并存储在存储模块中,可以表示为M = [B; X] =(m1,…,mb+T),其中mi是M的三元组之一,b和T分别表示KB数和对话历史记录。 对于k跳内存网络,外部知识由一组可训练的嵌入矩阵C =(C1,…,Ck + 1)组成。 我们可以在编码器和解码器过程中查询知识,以增强与知识模块的模型交互。
编码器查询知识
我们采用最后的隐藏状态作为初始查询向量:

此外,它可以循环k个跃点,并计算每个跃点k的注意力权重:
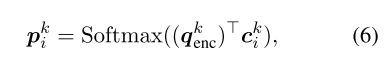
其中ck i是使用嵌入矩阵在第i个存储器位置的嵌入 Ck。 我们通过应用 gki = Sigmoid((qkenc)T cki)获得全局内存指针G =(g1,…,gb+T),该内存用于过滤外部知识以获取相关信息以进行解码。
最后,模型通过ck+1上的加权和读出内存ok,并更新查询向量qk+1enc。 正式地,
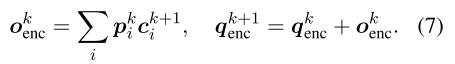
qk+1可以看作是编码的KB信息,并用于初始化解码器。
解码器查询知识
我们使用草图标记来表示以特殊标记开头的所有可能的插槽类型。(例如,@ address代表所有地址)。 当由等式4在t时间步生成草图标记时,我们使用隐藏状态hdec,t和注意表示h dect的级联来查询知识,这与在编码器中查询知识的过程类似:
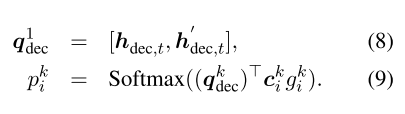
在这里,我们可以将Pt =(pk1,…,pkb+T)视为查询的知识的概率,并从查询结果中选择概率最高的单词作为生成的单词。
2.2共享专用编码器-解码器模型
第2.1节中的模型在混合的多域数据集上进行训练,并且模型参数在所有域之间共享。 我们称这种模型为共享编码器-解码器模型。 在这里,我们建议使用一个共享专用框架,其中包括用于捕获域共享功能的共享编码器-解码器和每个域的专用模型,以明确考虑特定于域的功能。 每个实例X都经过共享及其对应的专用编解码器。
增强编码器
给定一个实例及其域,共享-私有编码器-解码器会生成表示为H {s,d} enc的一系列编码器矢量,其中包括来自相应编码器的共享和特定于域的表示形式:
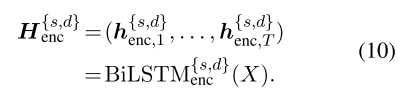
最终的特定于共享的编码表示形式Hfenc是以下混合:
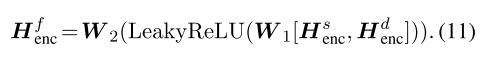
为了便于说明,我们将共享特定的融合函数定义为:
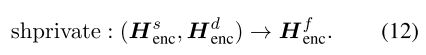
此外,自注意力已被证明对获取情境信息有用。 最后,我们遵循Zhong等人(2018)在 Hfenc上使用自注意力来获取上下文向量 cfenc。 我们将等式5中的 cfenc替换为 hT。 这使我们的查询向量将域共享功能与域特定功能结合在一起。
增强解码器
在解码器的第t步,私有和共享隐藏状态为:
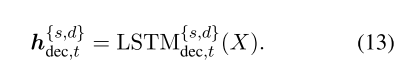
我们还将共享特定的融合函数应用于隐藏状态,并且混合向量为:
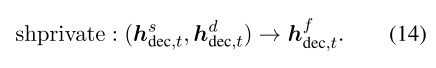
类似地,我们通过对 H fdec,t的 h fdec,t,t的关注来获得融合的专注表示 h f’dec,t。 最后,我们用合并共享的和特定于域的功能的[ hdec,t, h’dec,t]替换等式8中的[ hfdec,t和 hf’dec,t]。
2.2共享专用编码器-解码器模型
第2.1节中的模型在混合多域数据集上进行训练,并且模型参数在所有域之间共享。 我们称这种模型为共享编码器-解码器模型。 在这里,我们建议使用一个共享专用框架,其中包括用于捕获域共享功能的共享编码器-解码器和每个域的专用模型,以明确考虑特定于域的功能。 每个实例X都经过共享及其对应的专用编解码器。
增强编码器
给定一个实例及其域,共享-专用编码器-解码器会生成表示为H{s,d}enc的编码器矢量序列,其中包括来自相应编码器的共享和特定于域的表示形式:
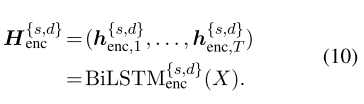
最终共享特定的编码表示形式Hfenc是混合的:
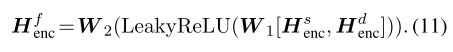
为了便于说明,我们将共享特定的融合函数定义为:
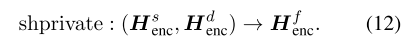
此外,自注意力已被证明对获取情境信息有用。 最后,我们遵循Zhong等人(2018)在Hfenc上使用自注意力来获取上下文向量cfenc。 我们将等式5中的cf enc替换为hT。 这使我们的查询向量将域共享功能与域特定功能结合在一起。
增强解码器
在解码器的第t步,私有和共享隐藏状态为:
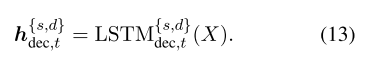
我们还将共享特定的融合函数应用于隐藏状态,并且混合向量为:
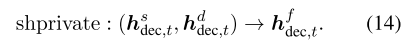
类似地,我们通过对Hfenc的hf dec,t的关注来获得融合的专注力表示hfdec,t。 最后,我们将等式8中的[hdec,t,hdec,t]替换为[h],其中包含共享和特定于域的功能。
2.3动态融合查询知识
共享-私有框架可以捕获相应的特定功能,但是忽略了某些域子集之间的细粒度相关性。 我们进一步提出了一个动态融合层,以充分利用所有领域知识,如图4所示。给定来自任何领域的实例,我们首先将其放入多个私有编码器-解码器,以从所有领域获得领域特定的功能。 接下来,所有特定于域的特征都由动态的特定于域的特征融合模块融合,然后是共享特定的特征融合以获取特定于共享的特征。
动态领域特定功能融合
给定来自所有域的特定于域的功能,专家混合机制适用于动态合并编码器和解码器中当前输入的所有特定于域的知识。现在,我们对如何融合解码的时间步t进行详细描述,并且融合过程与编码器相同。给定t解码步骤中的所有域特征表示:{hdidec,t} |D|i=1,
| D |代表域的数量,专家门E取{hdidec,t}作为输入,并输出softmax分数αt,i,该分数表示每个域与当前输入令牌之间的相关程度。我们通过一个简单的前馈层来实现:
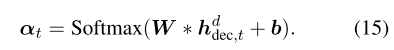
最终的特定领域特征向量是所有领域输出的混合,由专家门权重αt=(αt,1,…,αt,|D|)决定,可以写成 hdfdec,t = ∑i α t,ihdi dec,t
在训练过程中,以解码器为例,我们将交叉熵损失Lmoe dec作为专家门的监督信号,以预测响应中每个令牌的域,其中专家门输出αt可被视为Ken的多个私有解码器的预测域概率分布。因此,领域预测越准确,专家就越正确:
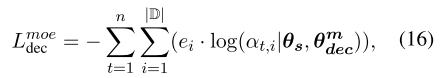
其中θs代表编码器-解码器模型的参数,θmdec代表解码器中MoE模块(方程15)的参数,ei∈{0,1}代表具有n个令牌的响应是否属于域di。 同样,我们可以得到编码器的Lmoeenc并将其总结为:
Lmoe = Lmoeenc + Lmoedec。
Lmoe用于鼓励某个来源域中的样本使用正确的专家,并且每个专家都将学习相应的领域特定功能。 当新域几乎没有标签数据或没有标签数据时,专家门可以自动计算不同域与目标域之间的相关性,从而更好地从编码器和解码器模块中的不同源域传递知识。
共享特定功能融合
我们直接采用私有操作来融合共享和最终特定于域的功能:
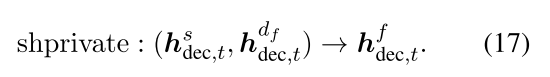
最后,我们将动态融合函数表示为dynamic(hs dec,t,{hdidec,t} |D| i=1)。 与第2.2节类似,我们将等式8中的[ hdec,t, h’dec,t]替换为[ hfdec,t和 hf’dec,t]。 其他组件与共享专用编码器-解码器框架保持相同。
对抗训练
为了鼓励模型学习域共享功能,我们在共享的编码器和解码器模块上应用对抗学习。 继Liu等人之后,在领域分类器层之后引入了梯度反转层。 对抗训练损失表示为Ladv。 我们遵循Qin等人(2019a),动态融合网络的最终损失函数定义为:
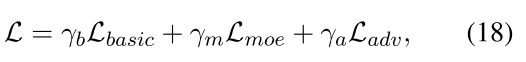
其中Lbasic与GLMP相同,γb,γm和γa是超参数。 有关Lbasic和Ladv的更多详细信息,请参见附录3
3 实验
4 相关工作
5 总结
在本文中,我们建议使用共享-专用模型来研究多域对话框的显式建模域知识。 另外,提出了动态融合层以动态捕获目标域和所有源域之间的相关性。 在两个数据集上的实验表明了所提出模型的有效性。 此外,我们的模型可以在几乎没有注释数据的情况下快速适应新领域















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









