







文章目录
深度学习与AI的关系
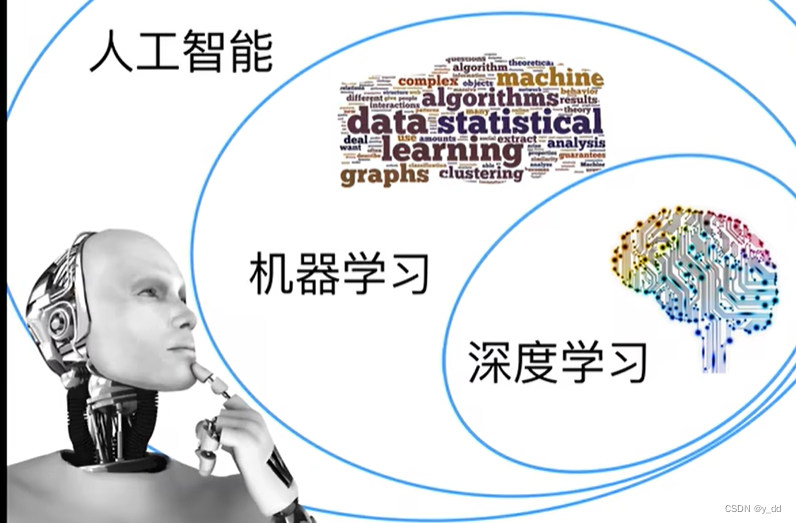
AI 包括 机器学习 包括 深度学习
目前深度学习的算法表现更好
机器学习的流程
数据获取
特征工程
建立模型
评估与应用
机器学习的核心以及问题
特征、算法
特征决定了模型的上限,算法和参数决定了如何去逼近这个基线
问题:传统的机器学习算法,在数据规模上升时,效果无法提升
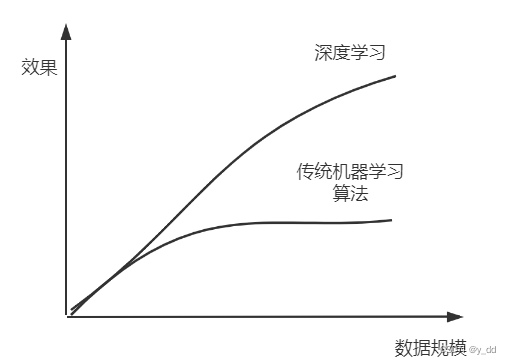
深度学习要解决的问题
模型如何搭建?
领域都有成型的模型,每年都有很多优秀的论文可以参考,反而特征提取更加重要
特征如何提取?
数值特征比较好提取
但是文本和图像 音视频等怎么提取呢?
留到下文详述
为什么要深度学习?
深度学习是一个黑盒子,能够提取出来最合适的特征,且能够自我学习更新,具备强大的学习能力
深度学习的应用
视觉类和自然语言类
- 视觉类任务
目标检测:无人驾驶汽车 怎么识别和检测目标

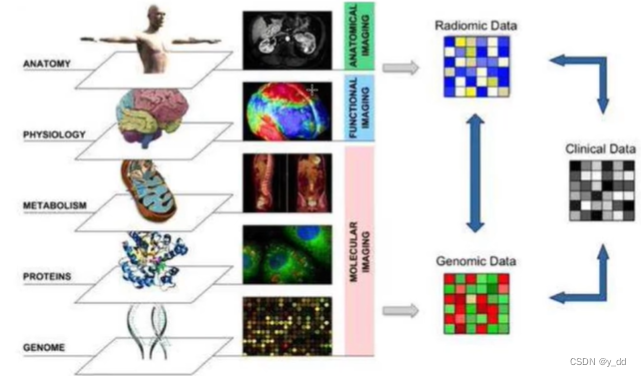
医学 影像识别 基因检测
-
自然语言处理
聊天机器人,生成对话机器人 -
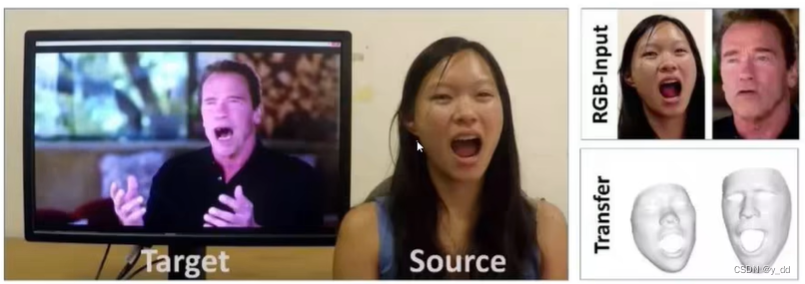
人脸识别 人脸替换
-
超分辨率重构
深度学习的问题
计算量很大
计算中涉及的参数上千万 上亿,计算和更新耗时很长
因此移动端不能很好的支持
计算机视觉任务
分类与检索
分类是指:让程序分类图片是什么,
由斯坦福大学的李飞飞教授带领创建IMAGENET分类数据集。该数据集包合 14,197,122张图片和21,841个Synset索引,基本可涵盖大部分分类了。

如何实现分类
- 传统的算法识别图片类别的方法:
比如K临近算法
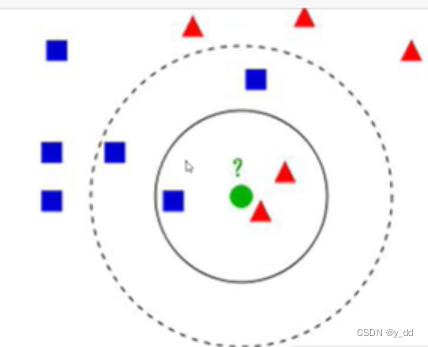
以上图为例:
选择离目标最近的3个点,比如第一个圈部分,三角形居多,那这个图片的分类就很可能是三角形。
但是这也有问题,如果选择的K是5个呢? 那这个类别的判定就是正方形,分类截然相反
- 以像素的近似点分类
先看一下,图像在计算中的表现形式,以3通道为例:RGB 3通道,一个3维 0到255的图像(h, w, c)形式
比如543的图片为例,在计算机中的表示


这样一个3维的像素数据如何判定出图片类别呢?
既然颜色的明亮程度可以用像素值类标识,最先想到的就是找出一些分类目标图片,计算输入图片与分类图片的像素差,哪两个个像素差最小,就归属于哪一类,最终分类的效果如下:

可以看出来部分图片的分类是正确,但是还有很大一部分是错误的,比如马被识别到了翻斗车的类别里
问题出在哪里呢?
首先无法区分背景和主题,对一幅图片来说,主题和背景的权重应该是不一样的,显然像素值的大小无法应对这种情况,另外还有如下所述的难点:
面临的挑战
比如照射的角度会导致像素变化
比如主体被别的东西遮蔽了

形状改变了

被挡住了一部分

背景混子在一起:

如何解决呢?
具体实现方式:
学习一次就知道了,比如遮蔽的情况,找一些类似的图片进行标注,进行学习
,通过学习后的网络就会记住这些特征也是属于这种分类的
神经网络基础
线性函数
(32,32,3)的图像 ,目标就是能计算它属于每个分类的得分。
这个猫是由3072个像素点决定的,也就是所谓的特征有3072个,记为x,怎么得出分值呢?
首先我们考虑一个问题,每个像素点对于这个猫的重要程度一样么?
答案是肯定不一样,比如背景的像素点是不相关的,重要程度低
比如眼睛,耳朵等等的像素点很重要,需要一个高的权重参数
所以需要3072个权重参数,来标注这个像素对于这个分类的重要程度
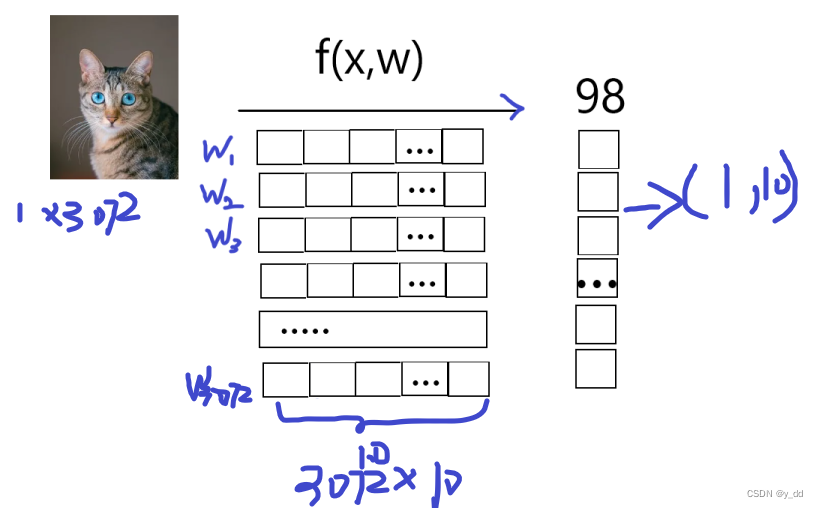
我们用一个w(3072)标识 每个像素是猫这个分类的权重
如果是判定十分类,就需要3072组w,10*3072大小的权重矩阵,分别去表示3073个像素分别对应10分类的权重。
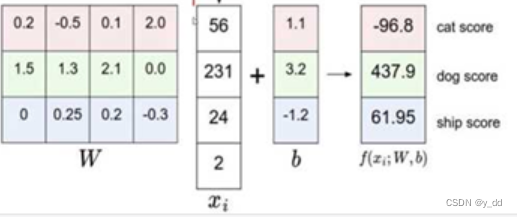
矩阵中的数字的意义:
越大的权重数据说明,当前的这个像素,对这个类别比较重要
权重中的负数表示对这个类别是抑制的作用
0表示对这个类别没有作用
这个矩阵哪里来的?
初始是随机值
比如现在判定错了,说明是权重不太对,想出一种方法,不断的去优化权重矩阵,直至能够区分出这个分类。那么问题来了,这个优化方法是什么?答案是利用损失函数
损失函数
损失函数的作用是来衡量分类的结果的,神经网络可以分类可以回归等,相同的网络,配以不同的损失函数,就可以完成不同的任务。
举个例子:经过神经网络输出猫 狗 飞机的分数是22 56 48,损失函数sum(max(0, y_predict - y_true)),这样设计的损失函数,在分类正确时,损失就为0
另一个问题,损失函数有不同的类型,如果损失函数的值相同,意味着模型相同么?如下的例子:
比如输入数据 1,1,1,1
模型1最终w1 [1,0,0,0]
模型2最终w2 [0.25, 0.25, 0.25, 0.25]
答案肯定是否定的,这两个模型肯定是不同的,虽然这两个参数与输入矩阵相乘后损失相同的。第一个模型是一种突然的变化,就容易导致结果过拟合
防止过拟合
通常为了防止过拟合,损失函数都设计为加上正则化的惩罚项:
损失函数 = 数据损失 + 正则化的惩罚项
我们总是希望模型不要太复杂,过拟合的模型是没用的,神经网络太强大了,而越强大的模型,过拟合就越大
前向传播
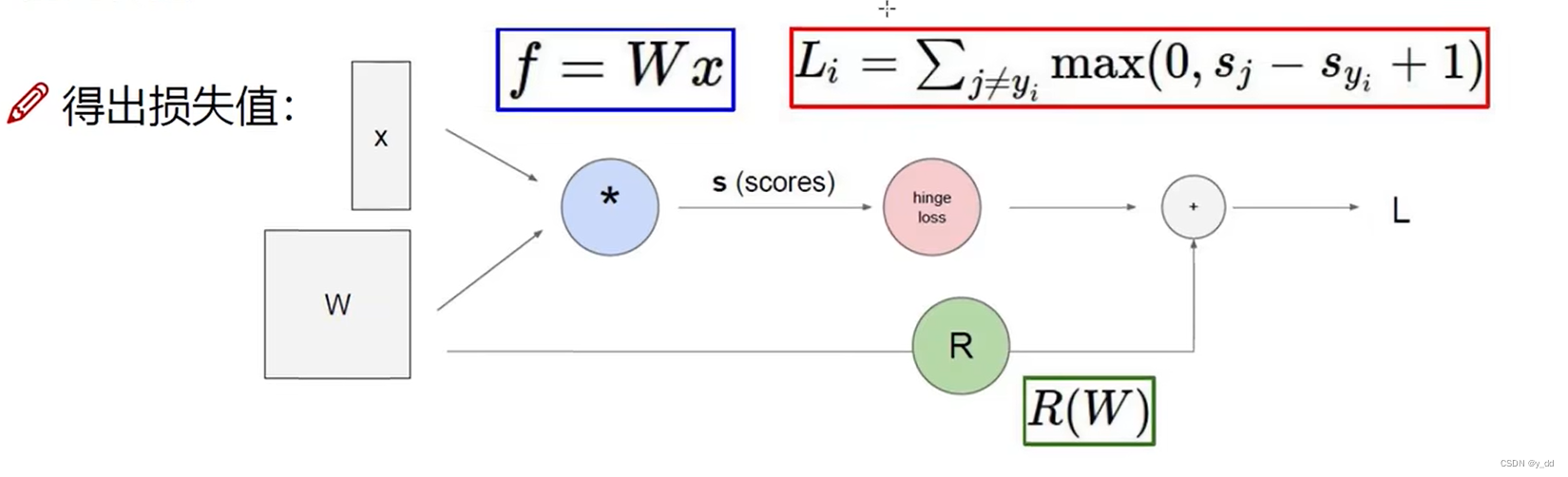
f(w, x)计算损失的过程,就是所谓的前向传播。
更进一步,在神经网络中,最终到的是一个分数值,但如果给我们一个概率的话是不是更好?
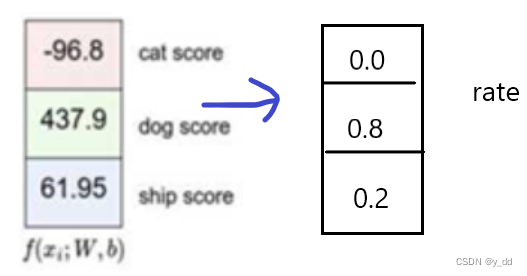
这就是通常所说的 归一化f,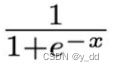

e指数次幂可以放大变化,上述可以归为0.1区间的概率值,也是常说的softmax
反向传播
由输入一步步计算出损失,是正向传播
那么如何更新模型呢? 更新模型的实质就是更新权重w, 这就是所谓的反向传播(也叫梯度下降)
反向传播的计算方法
当我们得到了一个目标损失函数后,让损失尽可能的小,结果就越靠近真实值,那怎么去求解呢?
寻找一种方法,更新后的参数能使目标函数达到极值点,极值点又是怎么求?数学上已经证明了的是极值点导数为0的点,这就是所谓的更新的方向。
我们需要从损失出发,向前去寻找导数为0的点,这种从后向前传播的过程就是反向传播,具体来说的计算方法是用了导数的链式法则
传播就是根据这个法则一步步往后计算的,常见的梯度下降算法:
-
批量梯度下降:
容易得到最优解,但是考虑所有样本,速度很慢 -
随机梯度下降SGD
每次找一个样本,迭代速度快,但不一定是朝收敛的方向 -
小批量梯度下降
每一次更新选择一小部分数据来算
学习率(或步长):
梯度下降的粒度,它对结果产生巨大影响,一般都会选择小一点
另外每次批处理的数量: 32 64 128都可以,很多时候需要考虑内存和效率
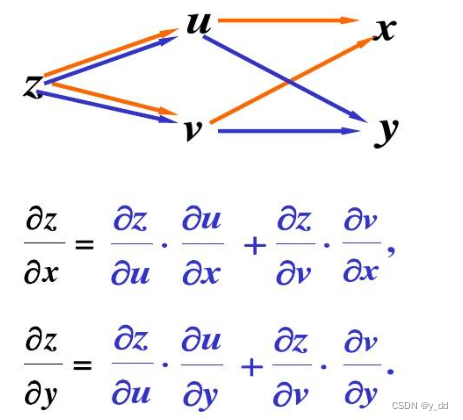
神经网络的架构
输入层 输出层 隐藏层
除了输入和输出,其它层叫做隐藏层
全连接层
中间这些连接线,其实就是所谓的参数,被称为全连接层,实质上是权重矩阵,意义是什么呢?比如上述对于10分类的权重矩阵,是对3072个像素的每个像素点,10个分类的不同权重。
神经元
隐层中的特征个数
神经元对网络的影响:
- 参数个数
举个例子 (800,600,3)的图片 100万个像素点,100w输入,增加一个神经元,1个隐层就增加100w个参数 - 拟合的程度
斯坦福大学有一个网站,可以显示神经元个数对分类的影响 https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
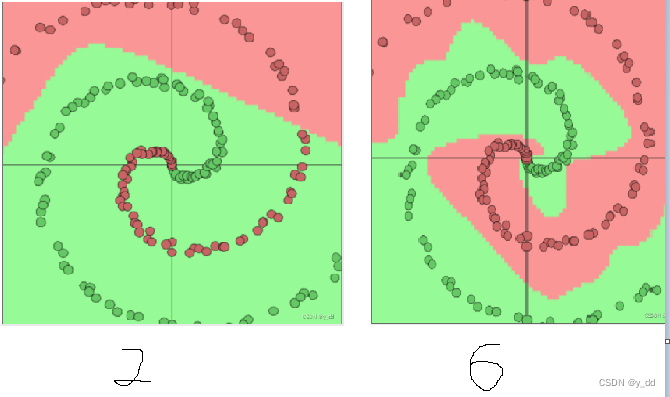
上图分别是2和6个神经元的展示结果,6确实是更拟合
惩罚粒度对结果拟合的影响
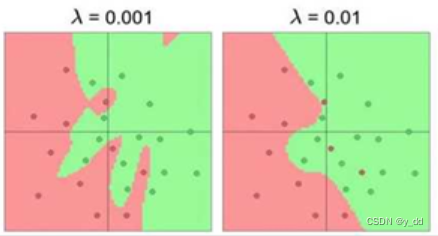
显然这里,更大的惩罚力度,可以让模型更稳定
激活函数
非线性函数 sigmod RELU tanh 等
实际上几乎每个隐藏层后面都还包括一些激活函数,加入一些非线性特征,常用的激活函数及其优缺点:
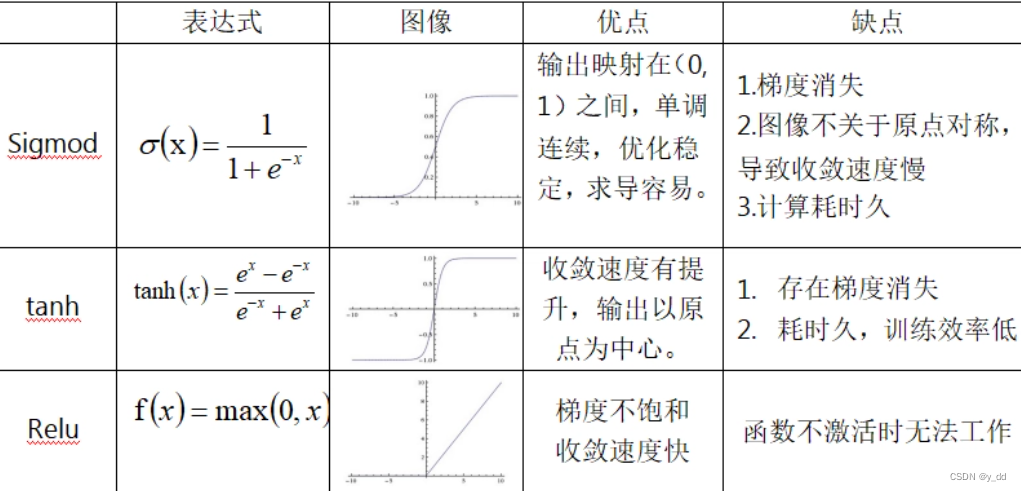
如上所述,sigmod 一旦数值较大或者较小,sigmod函数获取不到了,也就是所谓的梯度消失
ReLU及变种,是当前最常用的激活函数
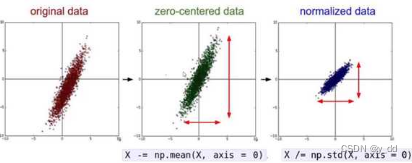
数据预处理
zero center 移动中心点 , normalized 缩小尺寸
参数初始化
一般都是随即策略进行参数初始化
过拟合解决方法
- 正则化
- 惩罚力度
- drop out 舍弃一部分神经元
- 其他















 3683
3683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









