



 该代码用于将VOC数据集的XML注解转换成TXT格式,并按训练集、验证集和测试集划分。同时,它还涉及图像的复制以及创建分割文件列表。程序中包含了对XML文件的解析,边界框坐标转换,以及随机抽样以分割训练、验证和测试集。
该代码用于将VOC数据集的XML注解转换成TXT格式,并按训练集、验证集和测试集划分。同时,它还涉及图像的复制以及创建分割文件列表。程序中包含了对XML文件的解析,边界框坐标转换,以及随机抽样以分割训练、验证和测试集。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import shutil
sets = [('TrainVal', 'train'), ('TrainVal', 'val'), ('Test', 'test')]
classes = ["mask_weared_incorrect", "with_mask", "without_mask"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_set, image_id):
in_file = open('VOC%s/Annotations/%s.xml' % (year, image_id))
out_file = open('VOC%s/labels/%s_%s/%s.txt' % (year, year, image_set, image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def copy_images(year, image_set, image_id):
in_file = 'VOC%s/JPEGImages/%s.jpg' % (year, image_id)
out_flie = 'VOC%s/images/%s_%s/%s.jpg' % (year, year, image_set, image_id)
shutil.copy(in_file, out_flie)
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/%s_%s' % (year, year, image_set)):
os.makedirs('VOC%s/labels/%s_%s' % (year, year, image_set))
if not os.path.exists('VOC%s/images/%s_%s' % (year, year, image_set)):
os.makedirs('VOC%s/images/%s_%s' % (year, year, image_set))
image_ids = open('VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
list_file = open('VOC%s/%s_%s.txt' % (year, year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/images/%s_%s/%s.jpg\n' % (wd, year, year, image_set, image_id))
convert_annotation(year, image_set, image_id)
copy_images(year, image_set, image_id)
list_file.close()
创建txt文件的代码如下
# -*- encoding:utf-8 -*-
import os
import random
xmlfilepath = r'F:\v7\VOCData\VOCTranVal\Annotations'
saveBasePath = r'F:\v7\VOCData\VOCTranVal\ImageSets'
trainval_percent = 0.9
train_percent = 0.9
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
ftrainval = open(os.path.join(saveBasePath, 'F:/v7/VOCData/VOCTranVal/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'F:/v7/VOCData/VOCTranVal/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'F:/v7/VOCData/VOCTranVal/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'F:/v7/VOCData/VOCTranVal/ImageSets/Main/val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
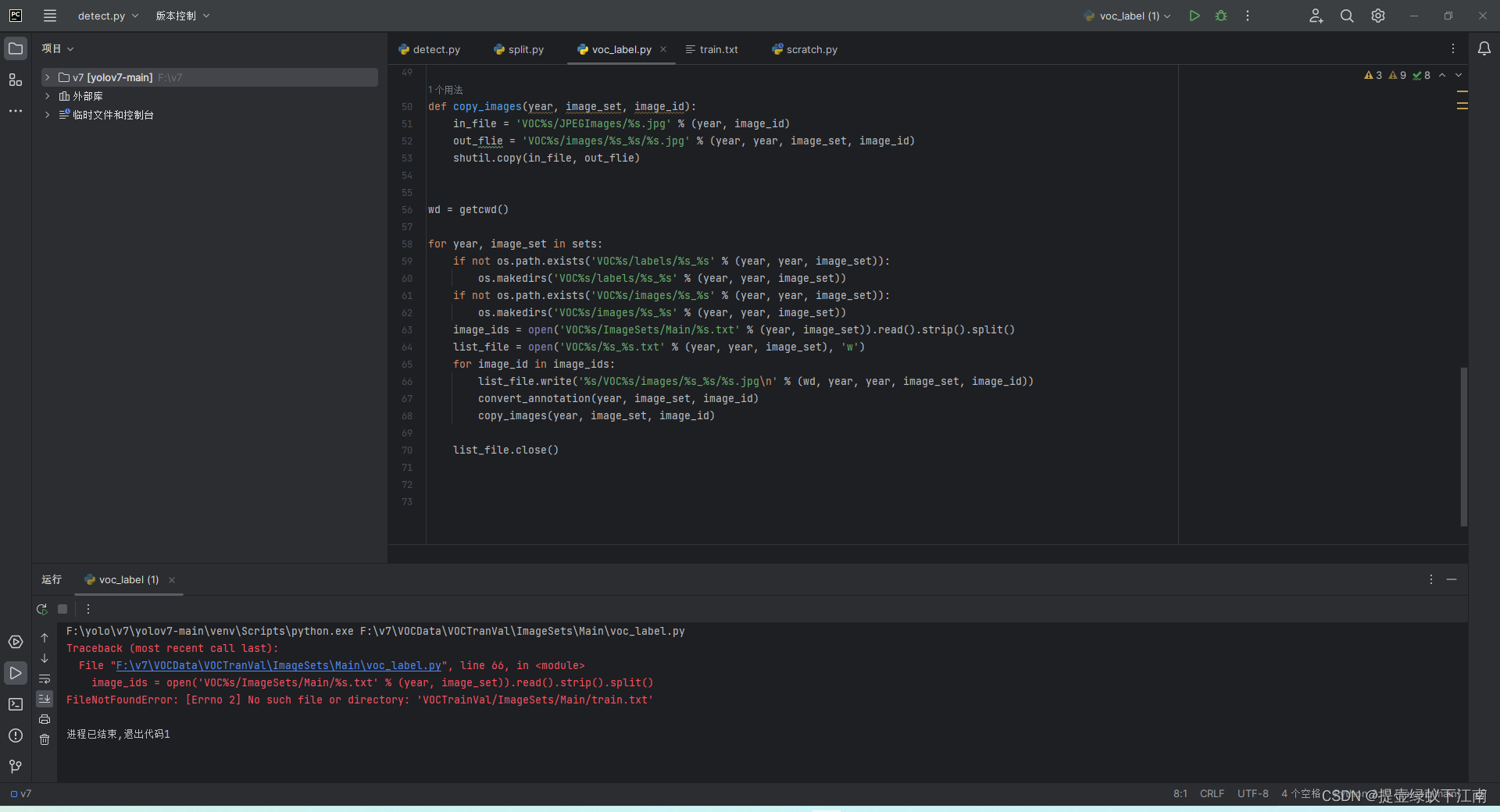
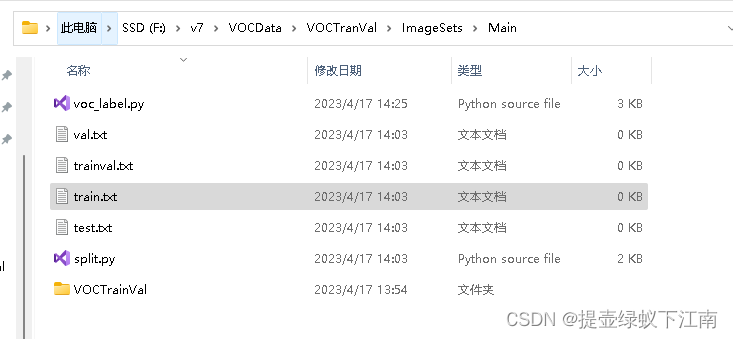
如图路径中有这个文件还是报错
错误如下
F:\yolo\v7\yolov7-main\venv\Scripts\python.exe F:\v7\VOCData\VOCTranVal\ImageSets\Main\voc_label.py
Traceback (most recent call last):
File "F:\v7\VOCData\VOCTranVal\ImageSets\Main\voc_label.py", line 63, in <module>
image_ids = open('VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
FileNotFoundError: [Errno 2] No such file or directory: 'VOCTrainVal/ImageSets/Main/train.txt'
进程已结束,退出代码1
小白的脑袋快抠烂了,求解!

















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







