







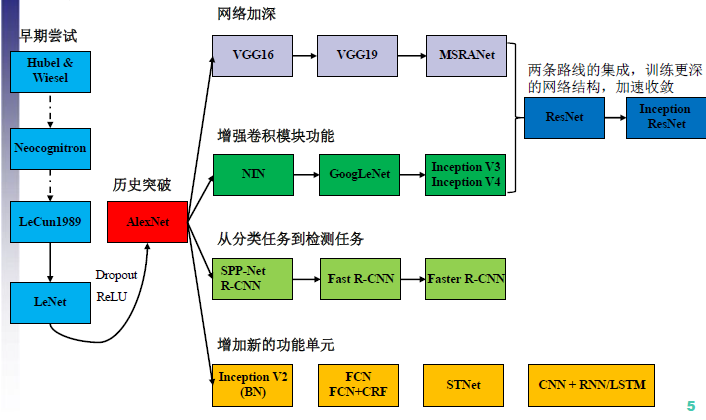
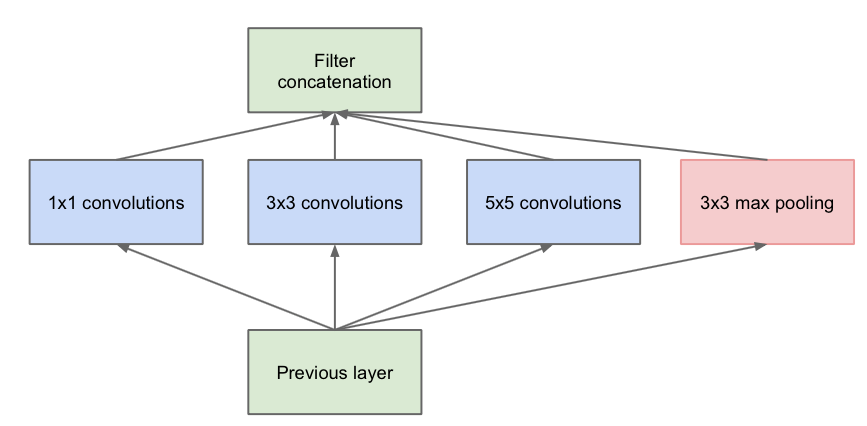
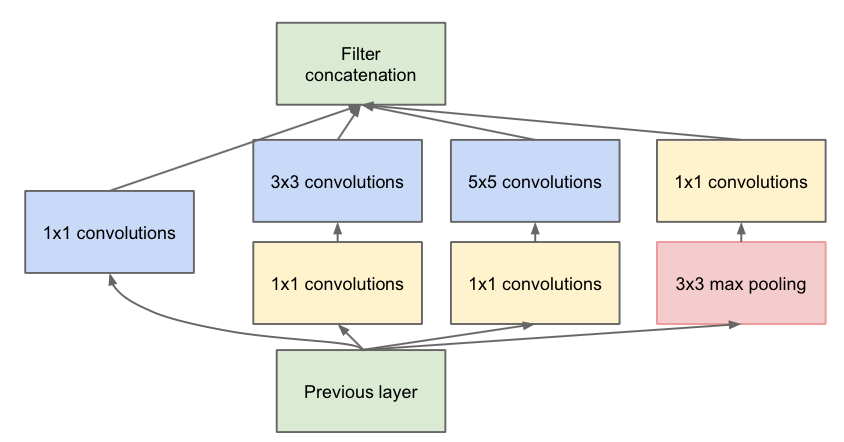
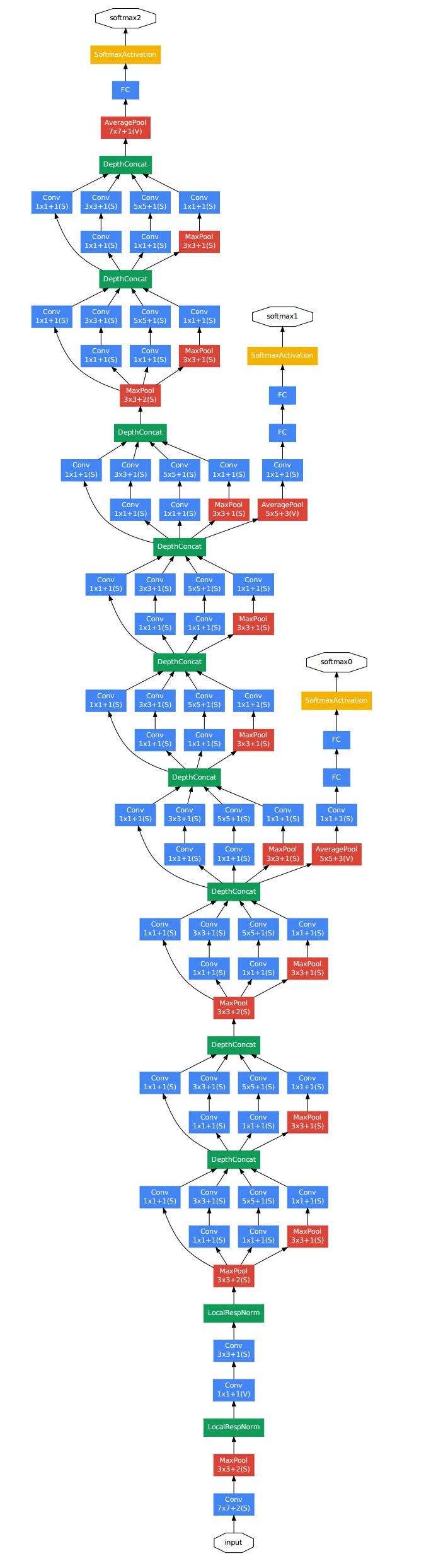
深入浅出——网络模型中Inception的作用与结构全解析
转载地址http://blog.csdn.net/u010402786
转载地址http://blog.csdn.net/u010402786
一 论文下载
本文涉及到的网络模型的相关论文以及下载地址:
[v1] Going Deeper with Convolutions, 6.67% test error
http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error
http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error
http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error
http://arxiv.org/abs/1602.07261
本文涉及到的网络模型的相关论文以及下载地址:
[v1] Going Deeper with Convolutions, 6.67% test error
http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error
http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error
http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error
http://arxiv.org/abs/1602.07261















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









