







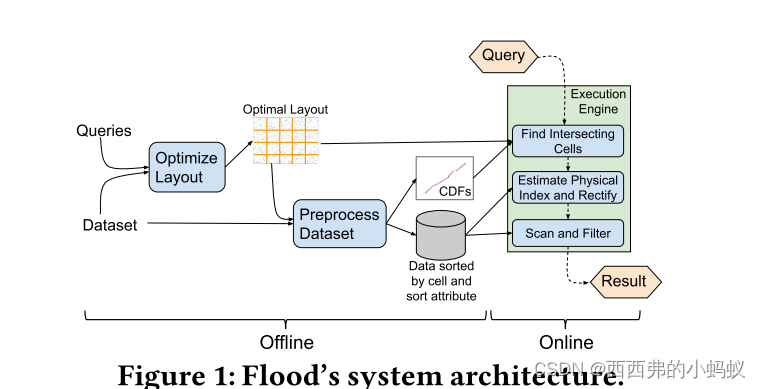
扫描和过滤多维表是现代分析数据库引擎中的关键操作。为了优化这些操作的性能,数据库通常在单一维度或多维索引(如r - tree)上创建聚集索引,或使用复杂的排序顺序(如z -排序)。然而,这些模式通常很难调优,而且它们在不同的数据集和查询上的性能不一致。在本文中,我们引入了一种多维内存读优化索引Flood,它通过联合优化索引结构和数据存储布局来自动适应特定的数据集和工作负载。在现实世界的数据集和工作负载上,与最先进的多维索引或排序顺序相比,Flood在范围扫描方面的性能提高了3个数量级。我们的工作是构建一个端到端的学习数据库系统。
背景:
多维索引仍然有很大的缺点。首先,这些技术非常难以调整。例如,Vertica对多个属性进行分层排序的能力需要管理员仔细选择排序顺序。因此,管理员必须知道哪些列是一起访问的,以及它们的选择性,以便做出明智的决定。第二,没有一种方法(即使调整正确)能够支配所有其他方法。正如我们的实验所显示的,最佳多维索引取决于数据分布和查询工作负载。第三,大多数现有技术不能完全针对特定的数据分布和查询工作负载进行定制。虽然它们都提供了可调参数(例如,页面大小),但它们不允许对特定数据集和过滤器访问模式进行更细粒度的定制
方案:
我们提出了Flood,这是第一个学习过的多维内存索引。Flood的目标是通过针对特定的数据和查询分布自动联合优化数据布局和索引结构,从而比现有索引更快地定位与查询过滤器匹配的记录。
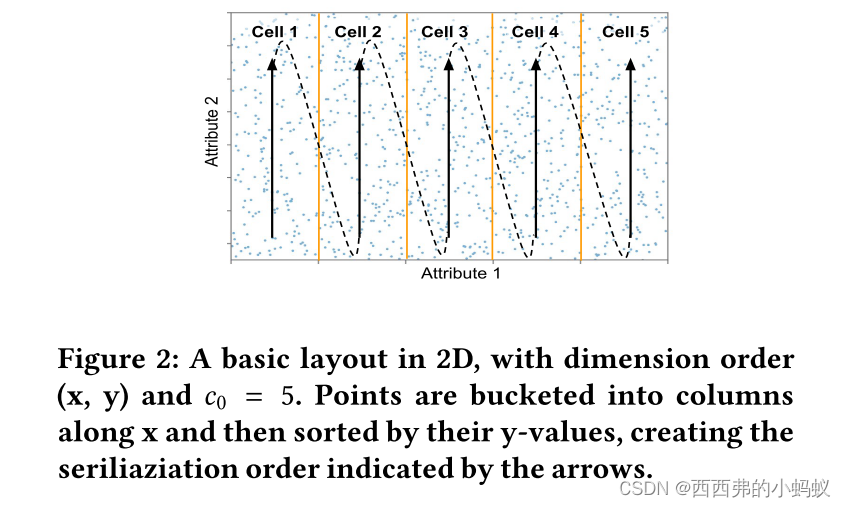
首先,flood use sample查询筛选工作负载了解使用某些维度的频率,哪些维度一起使用,以及哪些维度比其他维度更具选择性。基于此信息,Flood自动定制整个布局,以优化给定工作负载上的查询性能。其次,Flood利用经验的CDF模型将多维的、潜在倾斜的数据分布投影到一个更均匀的空间。这一“扁平化”步骤有助于限制搜索点的数量,是实现良好性能的关键
 总结:这篇论文在方法是新颖度不是很强,主要从两个方面:1)数据布局优化 2)考虑了特定数据的分布,主要利用CDF模型投影偏斜数据到统一空间。
总结:这篇论文在方法是新颖度不是很强,主要从两个方面:1)数据布局优化 2)考虑了特定数据的分布,主要利用CDF模型投影偏斜数据到统一空间。
论文的优点1:实验部分非常的详实,充分。这点是论文很大的亮点。其次论文写作上每个部分的采用技术的合理性,都给了详细的实验证实,使得论文有很强的根据。
缺点:1)在离线部分,找到经常访问的维度,然后构建数据布局,这种做法,看似合理,实际不容易,比如历史访问数据比较少的话,很难找到可以划分的维度,而且这部分论文没有给出较为合理的说明 2)其次一个CDF模型 适配所有特定的数据,模型训练和更新成本很高。

















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









