







在本文中,我们重点研究了通用分布式流数据处理系统(dsdps),该系统可以在实时或接近实时的情况下处理大规模的无界连续数据流。DSDPS中的一个基本问题是调度问题(即,将工作负载分配给工人/机器),其目标是最小化平均端到端元组处理时间。一种广泛使用的解决方案是以循环的方式将工作负载均匀地分布在集群中的机器上,这显然不是一种简单的方法.
本文旨在开发一种新的无模型方法,可以学习从其经验中很好地控制DSDPS,而不是准确的和数学可解决的系统模型,就像人类学习一项技能(如烹饪、驾驶、游泳等)。首次建议利用新兴的深度强化学习(DRL)在DSDPSs中实现无模型控制;设计、实现和评估一种新颖的、高度有效的基于深度强化学习的控制框架,通过收集非常有限的运行时统计数据和在强大的深度神经网络(DNNs)指导下做出决策,通过联合学习系统环境,最小化平均端到端元组处理时间。为了验证和评估所提出的框架,基于广泛使用的DSDPS Apache Storm实现了该框架,并在连续查询、日志流处理和单词计数(流版本)3个具有代表性的应用上进行了测试。实验结果表明:1)与Storm默认调度器和基于模型的方法相比,该框架平均减少元组处理次数33.5%和14.0%。2)所提框架能够在在线学习过程中快速得到较好的调度解,在DSDPSs中的在线控制中具有实用性
问题:
DSDPS中的一个基本问题是调度问题(即,将工作负载分配给工人/机器),其目标是最小化平均元组处理时间。
DESIGN AND IMPLEMENTATION OF THE PROPOSED FRAMEWORK
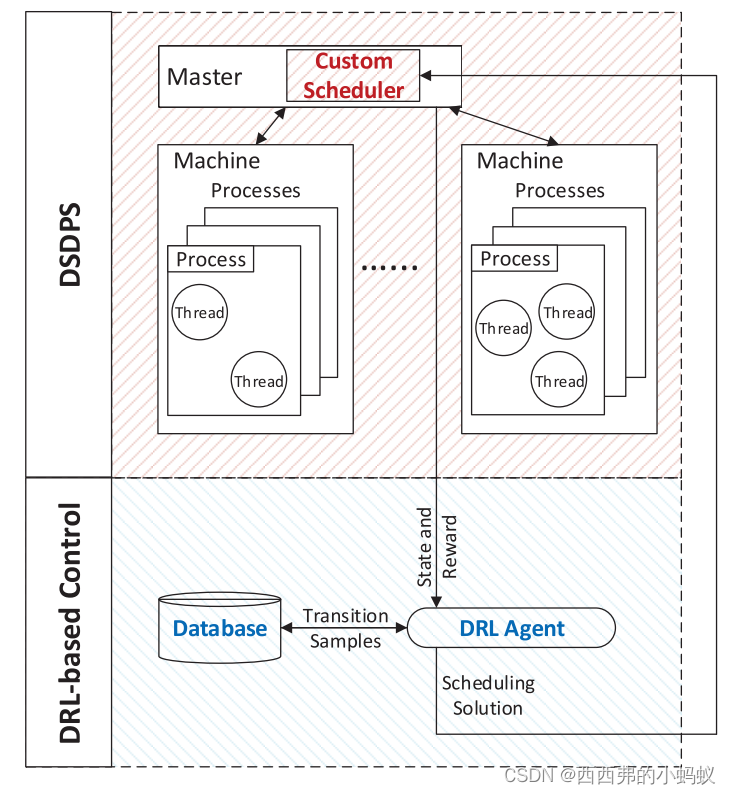
我们在图1中说明了所提出的框架,可以看到它有两个部分:DSDPS和基于drl的控制。该架构相当简单干净,由以下组件组成。















 3672
3672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









