










近年来,深度表示在强化学习中取得了许多成功。尽管如此,其中许多应用程序使用传统架构,如卷积网络,lstm或自动编码器。本文提出一种新的用于无模型强化学习的神经网络架构。所提出的对抗网络代表了两个独立的估计器:一个用于状态值函数,一个用于状态依赖的动作优势函数。这种分解的主要好处是跨动作泛化学习,而不对底层的强化学习算法进行任何更改。我们的结果表明,在存在许多相似价值的行动的情况下,这种架构可以带来更好的策略评估。此外,决斗架构使我们的RL智能体在Atari 2600领域的性能超过了最先进的技术。
阅读者总结:这篇论文相当于将状态价值和优势函数结合估计结合起来。模型的考虑是:对于许多状态来说,没有必要估计每个动作选择的价值
本文的贡献点主要是在 DQN 网络结构上,将卷积神经网络提出的特征,分为两路走,即:the state value function 和 the state-dependent action advantage function.
1. Introduction
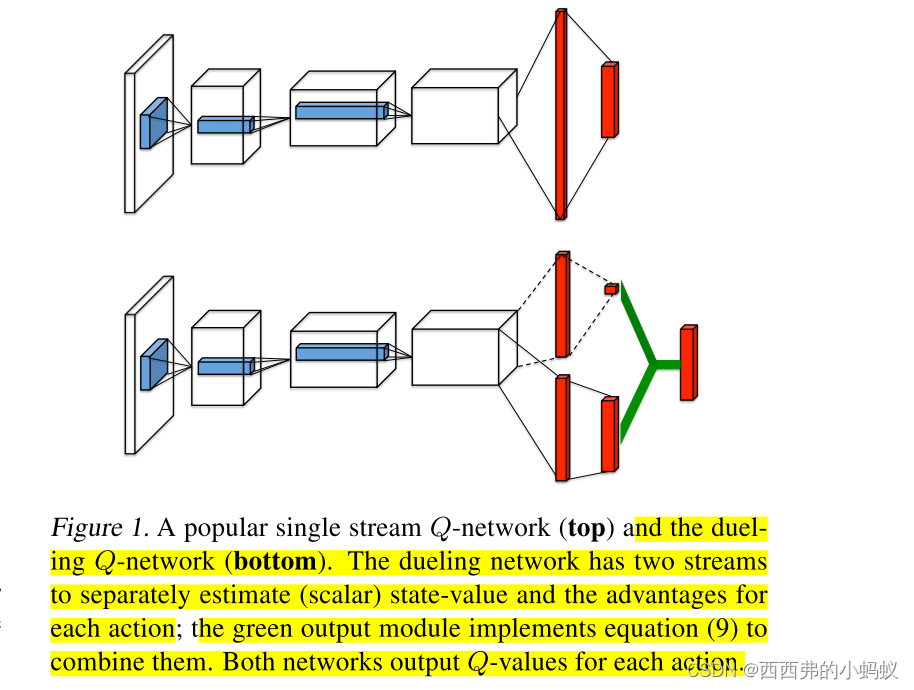
提出的网络体系结构,我们称之为Dueling Network Architectures,它明确地分离了状态值和(依赖于状态的)行动优势。Dueling Network Architectures由表示价值和优势函数的两个流组成,同时共享一个公共的卷积特征学习模块。通过一个特殊的聚合层将两个流结合起来,以产生状态-动作值函数Q的估计,如图1所示。这种决斗网络应该被理解为具有两个流的单个Q网络,它取代了现有算法中流行的单流Q网络,如深度Q网络(DQN;Mnih等人,2015)。该对抗网络自动产生状态值函数和优势函数的独立估计,无需任何额外的监督。
实验表明,随着在学习问题中添加冗余或类似的动作,决斗架构可以在策略评估期间更快地识别正确的动作
2 Motivation
发表这篇论文的时候,大家已经把各种各样的深度学习的架构应用在了强化学习中,在这个方向已经不太好创新了,这篇作者结合DQN的特点,对网络结构进行创新。在很多应用场景,存在很多的状态不同的动作对应Q值几乎是一样的,如在 Atari 游戏 Enduro 中,如下图所示,由于前方没有车,所以不同的动作对 Q 值没有影响,在训练 DQN 时,当执行一个动作后我们会修正该动作对应的 Q 值,而其他的动作对应的 Q 值如何变化我们是不关心的, 但是若我们把 Q(S, A) 值分成 V(S) 和 A(A, S) 来看待,同时训练了 V 和 A,那么对 V 部分的训练同样适用于别的动作,比如下图这个例子,我们随便执行一个动作,修正的 V 值同样也适用于别的动作,所以这样收敛更快。而下图的实验也证明了这一点,V 的输出注意力集中在远处的道路与当前的得分,因为这与该状态的得分有关,而 A 没有什么特别关注的地方,因为前方没有车,所以当前执行什么动作是不影响未来得分的。

3. The Dueling Network Architecture
如图2所示,我们的新架构背后的关键见解是,对于许多状态来说,没有必要估计每个动作选择的价值。例如,在Enduro游戏设置中,只有在即将发生碰撞时才知道向左或向右移动。在一些州,最重要的是知道采取什么行动,但在许多其他州,选择行动对发生的事情没有任何影响。然而,对于基于bootstrapping的算法来说,状态值的估计对于每个状态都是非常重要的
为了实现这一见解,我们设计了一个单一的Qnetwork架构,如图1所示,我们将其称为决斗网络。与原始的dqn一样,决斗网络的较低层是卷积的(Mnih等人,2015)。然而,我们不是使用一个全连接层的序列来跟踪卷积层,而是使用两个全连接层的序列(或流)。流被构造成它们能够提供单独的值估计和优势函数。最后,将两个流合并以产生单个输出Q function.
将两个全连接层流结合起来输出Q值的模块需要非常周到的设计。

为了解决可识别性的问题,我们可以强制优势函数估计器在选定的动作处为零优势。


因此,流V(s;θ, β)提供了价值函数的估计,而其他流产生了优势函数的估计

















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









