







数据可视化已经成为数据工程的一个基本过程。t-SNE是最流行的数据可视化方法之一。然而,由于需要计算所有数据点对的相似度,它的计算成本是数据点数量的二次函数。使用t-SNE的一种实际方法是基于随机游走的t-SNE。该方法通过在数据点邻域图上的随机游走,将用户指定的地标点之间的相似性可视化。它提供了两种计算相似度的方法:直接方法和分析方法。直接方法通过显式地计算图中的随机游走近似地计算相似度。不幸的是,它需要执行多次随机漫步才能获得足够的计算精度。该分析方法对图拉普拉斯算子进行Cholesky分解,并使用分解后的图拉普拉斯算子计算精确相似度。然而,这在执行Cholesky分解时带来了很高的计算成本。提出的F-tSNE通过计算图拉普拉斯的LDL分解来降低基于随机游走的t-SNE的计算成本,其思想有两个:(1)通过使用重排矩阵减少LDL分解中的非零元素;(2)在计算相似度时利用图的稀疏结构。理论上,该方法保证产生精确的相似性。实验结果表明,该方法的运行速度是现有方法的88.4倍
背景:
能够完全自动化索引推荐和实现是一个重大的增值。生产系统的自动化索引实现的一个关键要求是创建或删除索引不会导致显著的查询性能下降。这种回归,即更改索引后查询的执行成本增加,是全自动索引的主要障碍[24,52],因为用户希望强制执行无查询回归约束。
方法:
本文提出一种最先进的索引调节器[2,19,72]的设计和实现,以有效利用机器学习(ML)技术来提高索引推荐质量,即利用人工智能(AI)来改进自动索引(AI)。通过将问题表述为回归任务,通常使用执行历史来训练ML模型来预测执行成本[5,27,31,49]然后,索引调优器可以使用ML模型的预测成本,而不是查询优化器的估计成本。然而,由于查询、数据分布、物理操作符类型和索引类型的巨大多样性,这个回归问题具有挑战性。
1)我们的第一个关键见解是,比较两个计划的执行成本可以表述为ML中的分类任务。训练分类器来决定一对计划中哪个计划的执行成本更低,这比使用(学习或分析的)成本模型来比较成本的准确率更高。
2)我们的第二个关键见解是,与优化器“同步”只需要调优器使用优化器将选择的计划。我们基于文献中描述的概念,在Azure SQL数据库的索引调优器原型中实现了我们的技术

2.3 Architecture
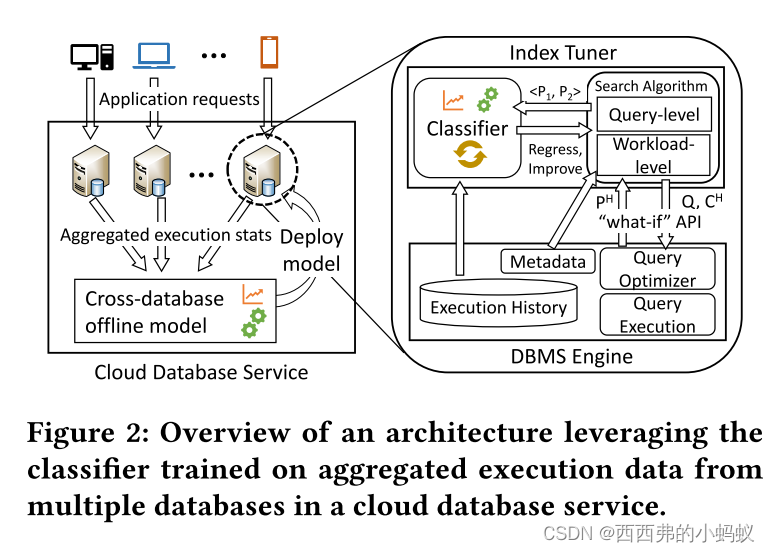
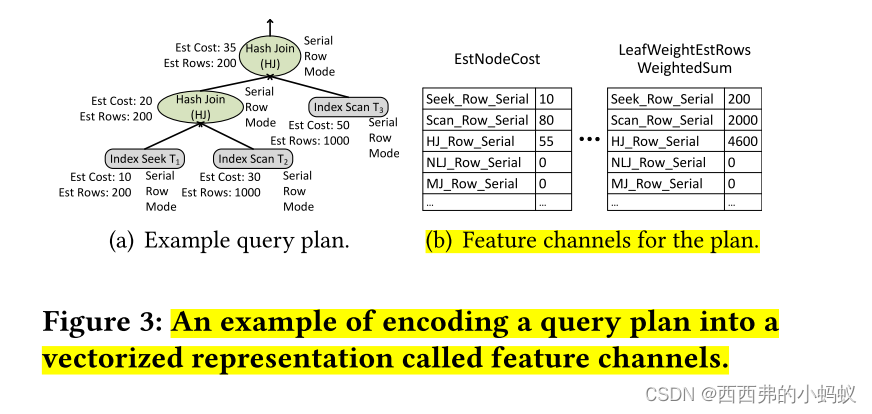


5 INTEGRATION WITH INDEX TUNER

6 DESIGN ALTERNATIVES
















 4100
4100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









