







Constructing and Analyzing the LSM Compaction Design Space
日志结构合并(LSM)树通过附加传入数据提供了高效的摄入,因此被广泛用作生产NoSQL数据存储的存储层。为了实现有竞争力的读性能,lsm树定期地重新组织数据,通过迭代紧实形成容量指数级增长的树。紧凑从根本上影响lsm引擎的性能,包括写放大、写吞吐量、点和范围查找性能、空间放大和删除性能。因此,选择合适的压实策略是至关重要的,与此同时,lsm压实设计空间很大,很大程度上未被探索,在文献中还没有正式定义。因此,大多数基于lsm的引擎使用固定的压缩策略,通常由工程师亲自挑选,由工程师决定如何以及何时压缩数据。
本文提出了LSM-compactions的设计空间,并在关键性能指标方面评估了最先进的合并策略。朝着这个目标,我们的第一个贡献是引入了一组4个可以正式定义任何合并策略的设计原语:(i)合并触发器,(ii)数据布局,(iii)合并粒度,以及(iv)数据移动策略。在一起,这些原语可以合成现有的和全新的合并策略。我们的第二个贡献是实验分析了10种压缩策略。我们提出了12个观察和7个高层次的收获消息,展示了LSM系统如何在压缩设计空间中导航。
缺点:1)LSM的压缩空间严重依赖人的设计

我们将压缩策略定义为一个设计原语的集合,它表示关于物理数据布局和数据(重新)组织策略的基本决策。每个原语回答一个基本的设计问题

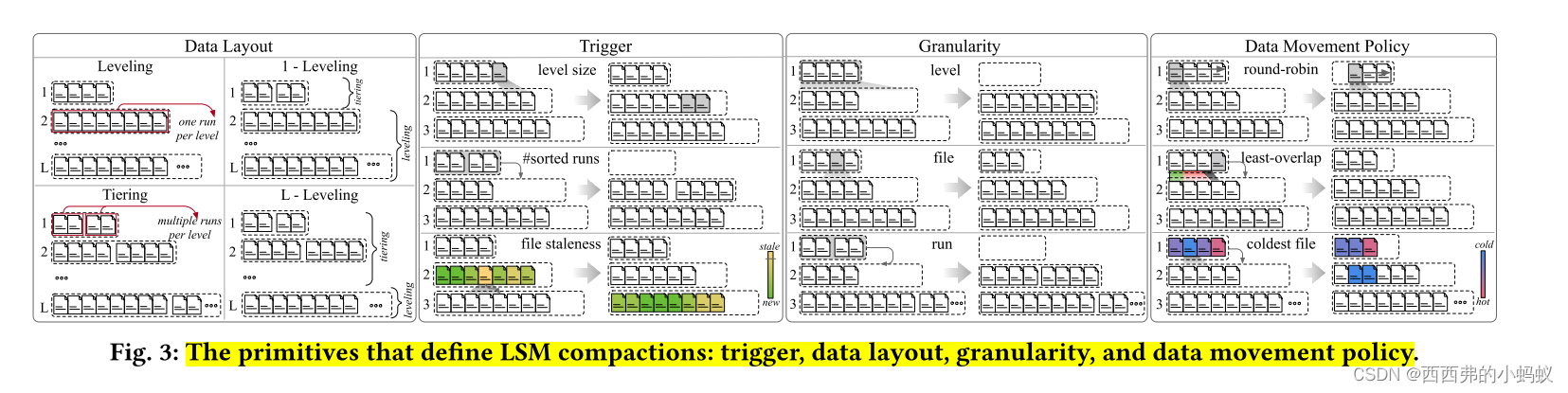
Compaction Trigger
Data layout.

Compaction Granularity.
 Data Movement Policy
Data Movement Policy

结论:
基于lsm的引擎提供了高效的数据采集和具有竞争力的读取性能,同时能够管理各种优化目标,如写入和空间放大。lsm树工作的一个关键内部操作是合并过程,它定期重新组织磁盘上的数据。
本文提出LSM压缩设计空间,它使用4个原语来定义压缩:(i)压缩触发器,(ii)数据布局,(iii)压缩粒度和(iv)数据移动策略。将现有方法映射到这个设计空间中,并选择几个有代表性的策略来研究和分析它们对性能和其他指标的影响,包括写/空间放大和删除延迟。本文提出了广泛的观察结果,为LSM系统奠定了基础,该系统可以更灵活地导航压缩的设计空间。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









