









图自监督学习因其能够学习具有表现力的节点表示而受到越来越多的关注。许多前置任务或损失函数是从不同的角度设计的。不同的前置任务在不同数据集上对下游任务的影响不同,这表明对前置任务的搜索对图自监督学习至关重要。与现有工作侧重于设计单一的前置任务不同,本文旨在研究如何自动有效地利用多个前置任务。然而,在不直接访问地面真值标签的情况下,评估从多个伪装任务中获得的表示使这个问题具有挑战性。为解决这一障碍,本文利用许多现实世界图的一个关键原则,即同质性,或"同类吸引同类"的原则,作为指导,来有效搜索各种自监督伪装任务。本文提供了理论理解和经验证据,以证明同质性在这一搜索任务中的灵活性。提出AUTOSSL框架来自动搜索各种自监督任务的组合。通过在8个真实数据集上评估该框架,实验结果表明,与单个任务下的训练相比,AUTOSSL可以显著提高节点聚类和节点分类等下游任务的性能。
总结:
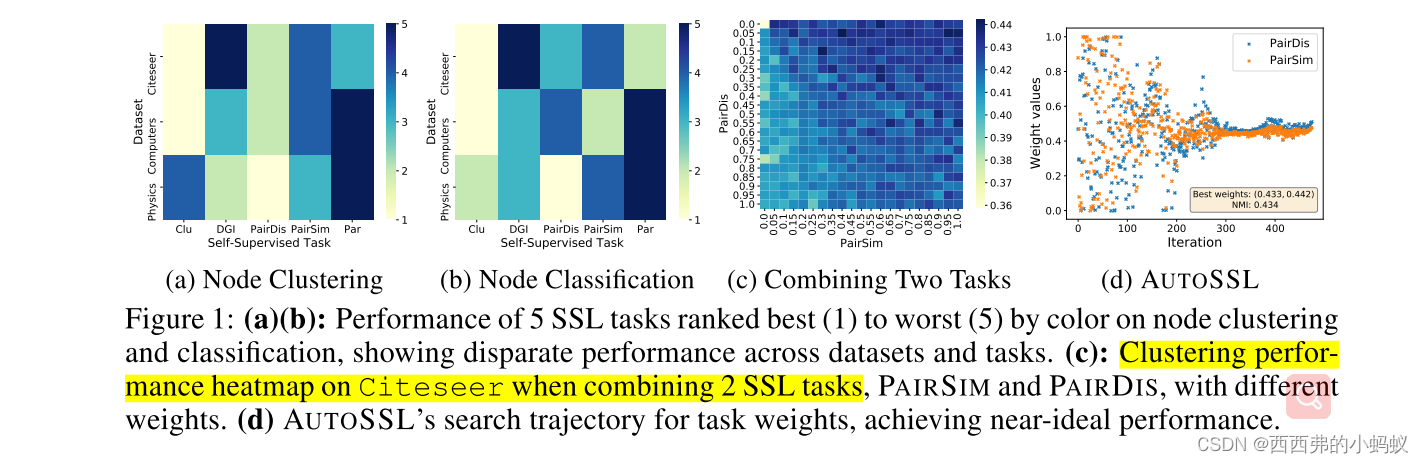
组合多个SSL任务来联合编码多个信息源并产生更一般化的表示,为不同的下游任务服务。我们利用图同质性并提出伪同质性来衡量SSL任务组合的质量。















 2722
2722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









