









NeutronStar: Distributed GNN Training with Hybrid Dependency Management
GNN的训练需要解决顶点依赖的问题,即每个顶点表示的更新依赖于其邻居。现有的分布式GNN系统采用依赖项缓存方法或依赖项通信方法。经过深入的实验和分析,发现为最佳性能选择一种方法的决定是由一组因素决定的,包括图输入、模型配置和底层计算集群环境。如果仅由一种方法支持各种GNN训练,性能结果往往是次优的。在执行之前,研究了每个GNN训练的相关因素,以相应地选择最佳匹配方法。本文提出了一种混合依赖处理方法,在运行时自适应地结合两种方法的优点。在此基础上,开发了分布式GNN训练系统NeutronStar,实现了GNN训练的自动化。通过对CPU-GPU计算和数据处理的有效优化,NeutronStar也得到了增强。在16节点的阿里云集群上的实验结果表明,与现有的GNN系统DistDGL和ROC相比,NeutronStar取得了1.81 x -14.25倍的加速比。
一研究背景:
1)在GNN训练中,顶点样本之间的依赖关系由给定的输入图确定。顶点依赖被定义为顶点的直接内近邻。每个顶点收集和聚合来自其近邻的特征向量,并使用聚合向量基于参数化函数(NN模型)生成新的顶点表示。
2)分布式GNN系统设计的一个关键挑战是如何有效地处理NN前向和后向传播期间的顶点依赖关系。
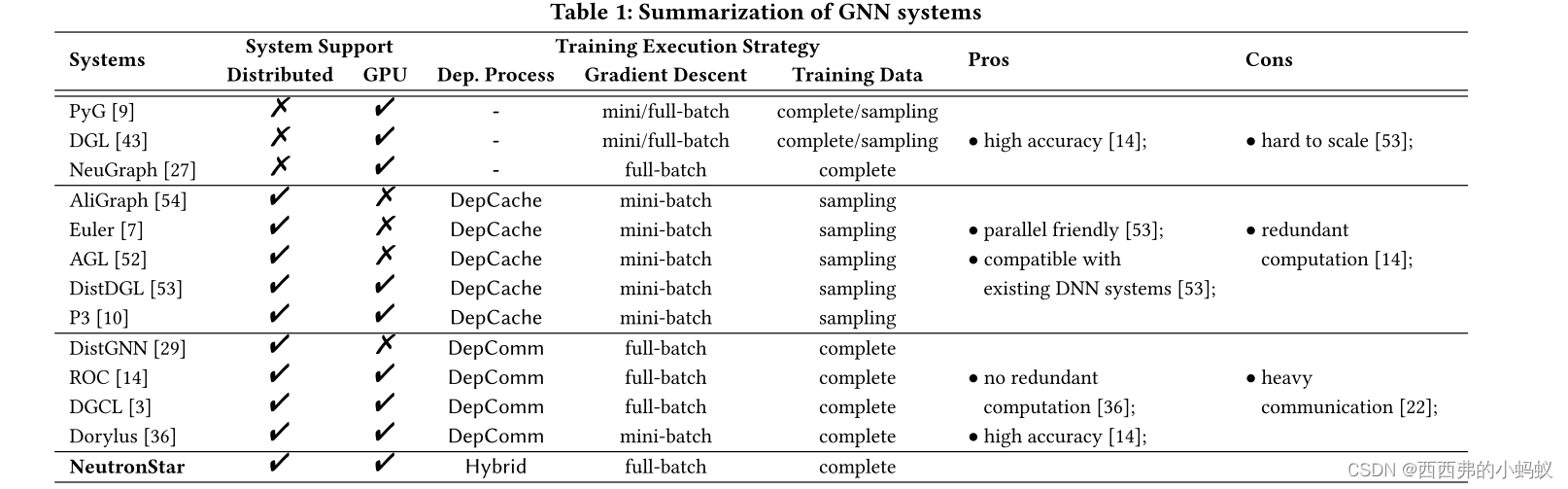
3)近年来,许多分布式GNN系统被提出以支持大规模GNN训练,如AliGraph[54]、Euler[7]、AGL[52]和DistDGL[53]。这些分布式GNN系统是在现有的分布式机器学习系统(如Tensorflow[1]和分布式PyTorch[23])之上设计的,以便高度优化NN执行。它们依赖于依赖缓存(DepCache)方法,与数据并行模型一起用于GNN的训练
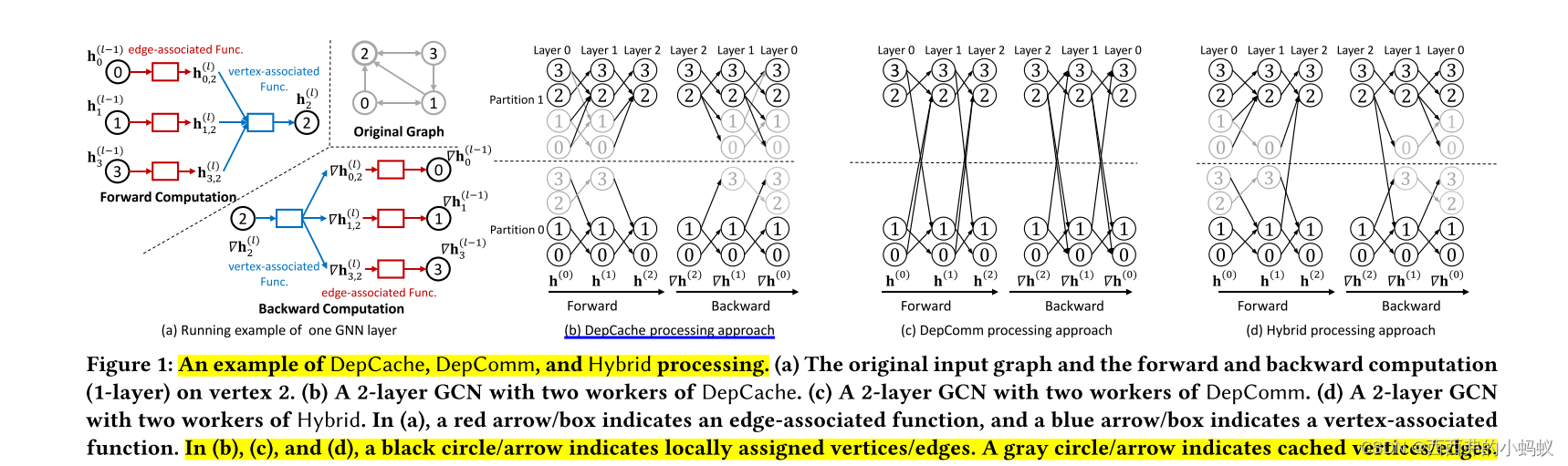
4)如图1(b)所示,图传播和神经网络的前向/后向计算只发生在每个worker中。DepCache方法使worker之间没有表示/梯度交换,符合数据并行模型。这样,就可以借助现有的DNN系统来支持大规模的GNN训练。然而,DepCache方法可能导致严重的冗余计算,从而导致性能下降。
5)其他一些系统[14,29]采用依赖通信(DepComm)方法。这些系统不是在本地缓存依赖关系,而是让每个顶点通过通信从远程工作节点收集其邻居的表示。上游相关顶点的计算结果可以传递给下游相关顶点,并被下游相关顶点共享。没有冗余计算,但有必要进行通信。在配备GPU加速器的高级分布式平台中,通信开销也会严重影响性能
二研究方法:
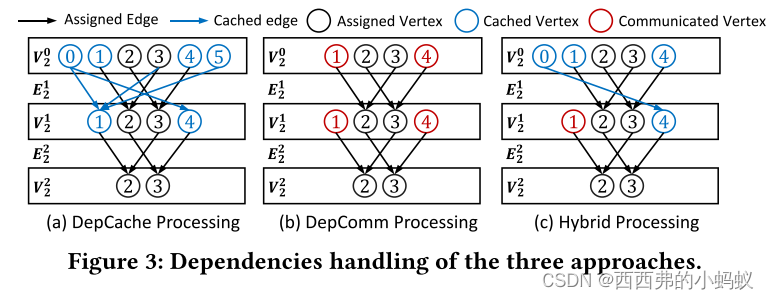
本文提出了一种混合依赖管理方法,如图1(d)所示。与采用DepCache或DepComm的现有分布式GNN系统[7,14,29,37,52-54]不同,NeutronStar将DepCache和DepComm结合起来以实现最大性能。该系统的有效性在于,在给定的图和硬件环境下,估计每个依赖邻居的DepCache开销和DepComm开销,并针对不同的依赖选择性价比最高的处理策略。基于混合依赖管理方法,本文提出了一种支持gpu加速的分布式GNN训练系统NeutronStar。
在NeutronStar中,我们实现了一个灵活的自动区分框架,支持根据链式规则自动计算梯度和跨worker梯度反向传播。本文采用顶点切割的主镜像框架将跨worker的图操作与worker内的NN操作解耦,而不是手动实现跨worker的前向/后向计算操作,从而可以将现有DNN系统的硬件优化的操作实现用于局部NN操作。目前,NeutronStar依赖于PyTorch autograd库[31]中gpu优化的算子实现,并且可以通过使用TensorFlow[1]或MindSpore[20]灵活扩展以与其他硬件优化的算子一起工作。此外,NeutronStar还提供了基于分块的任务划分、基于环的任务调度、通信和计算任务重叠以及无锁并行消息队列等机制,以实现高效的异构CPU-GPU处理和通信。为了便于使用,还提供了高级python api
三具体方法
1. Distributed GNN Training Approaches
GNN训练需要处理顶点依赖关系。在单机器训练系统中,完整的图数据和模型参数可以在本地获取。然而,在分布式环境中,这些数据是分区分布在工作节点之间的,这可能会导致远程依赖。由于远程检索依赖邻居的表示可能导致跨worker的前向/后向传播,设计分布式GNN系统的一个主要问题是如何在运行时有效处理依赖关系。现有的分布式GNN系统主要采用两种训练方法。
1)Dependencies Cached (DepCache). I
2)Dependencies Communicated (DepComm).
这两种方法的主要区别在于分布式前向和后向传播中处理大规模顶点依赖的方式。我们在图1中展示了一个例子。对于2层的GCN模型,图1(b)和图1(c)分别说明了DepCache和DepComm的前向和后向计算。通过在DepCache中本地缓存多跳依赖关系,训练过程可以轻松适应现有的分布式DNN训练系统,如TensorFlow[1]。但多个worker在缓存的顶点和边上存在冗余计算。相反,基于以顶点为中心的图处理框架,DepComm可以消除冗余计算,但以通信开销为代价。因此,depcache的冗余计算开销和depcomm的通信开销是系统设计中必须考虑的一个重要问题。
3)Existing GNN Systems Review

THE NEUTRONSTAR
我们设计并实现了一个分布式gpu加速GNN训练系统NeutronStar。图4展示了整体结构。
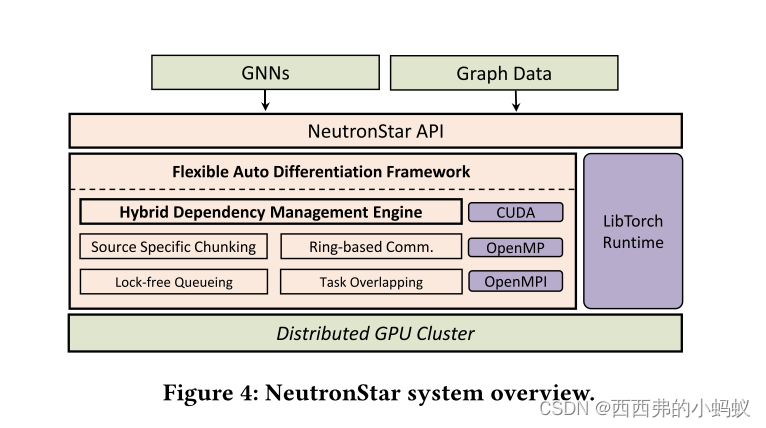
1. Flexible Auto Differentiation Framework
为了实现混合依赖管理,NeutronStar必须首先实现DepCache和DepComm处理,然后才能在顶点上切换DepCache和DepComm。现有的分布式GNN训练系统可以直接使用较低级别的DNN库来实现DepCache,因为所有依赖项都已经在本地缓存。
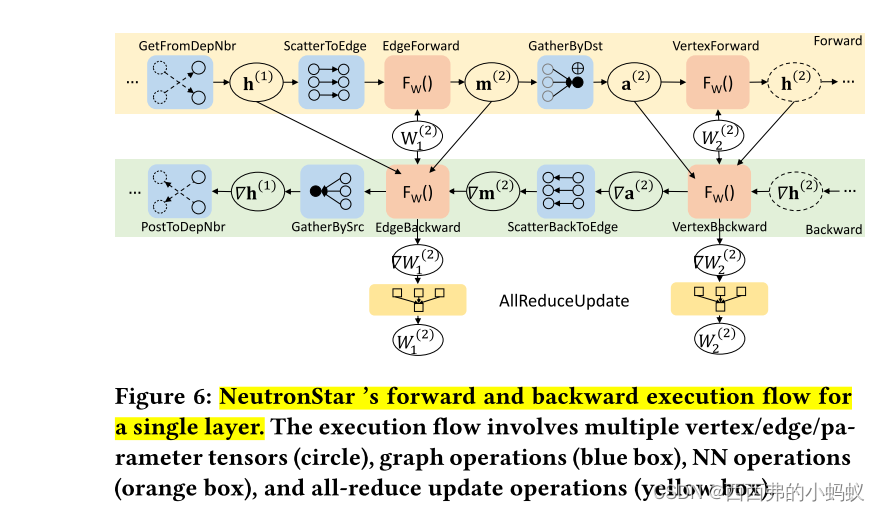
2. Graph Chunking and Task Scheduling
每个worker负责一个顶点子集以及它们的in-edge,以便并行处理。考虑到高维节点特征的大图数据,我们不假设所有需要的数据都能存储到GPU设备内存中。在每个工作节点中,被分配用于DepComm处理的顶点的In -edge根据其源节点被分割成块。















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









