







HashMap的内部存储结构
Java中数据存储方式最底层的两种结构:数组和链表。数组的特点:连续空间、寻址迅速,但是在增删的时候需要较大幅度的移动,所以查询快、增删慢,链表与之相反,空间不连续、寻址困难,增删的时候只需修改前后指针即可,所以查询慢,增删快。那么有没有一种数据结构能够综合数组和链表的优点呢,答案是肯定的,就是哈希表。哈希表具有较快的(常量级)查询速度,和相对较快的增删速度,所以很适合在海量数据的环境中使用。一般采用“拉链法”实现哈希表,我们可以理解为链表的数组。如下图,
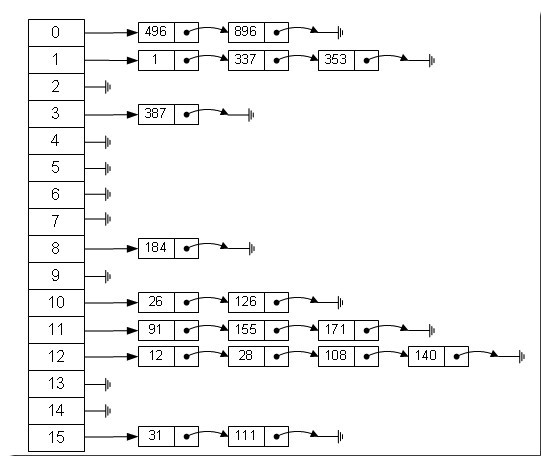
从上图中我们可以看到哈希表是由数组+链表组成的,一个长度为16的数组,每个元素中存的链表的头节点,那么这些元素是按照什么规则存储到数组中的呢?一般通过key的hash值对数组长度取摸得到,也就是hash(key)%len,它的内部其实是用一个Entry[]数组来实现的。
1 初始化
先看三个常量
static final int DEFAULT_INITIAL_CAPACITY = 16; //初始容量:16
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量:2的30次方:1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f; //装载因子














 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









