









题目:Deepwalk: Online learning of social representations
作者:Perozzi, Bryan and Al-Rfou, Rami and Skiena, Steven
来源:KDD 2014
模型
short random walks = sentence
word2vec在训练词向量时,以文本语料作为输入数据;网络表示学习以复杂信息网络作为数据输入。在训练过程中词语出现的频次与根据原始网络结构进行随机游走时顶点被访问到的次数两者均服从幂律分布。
DeepWalk方法很简单,就是以某一特定点为起始点,做随机游走得到点的序列,然后得到的序列视其为句子,用word2vec来学习,得到该点的表示向量。
| 类比 | word2vec | deepwalk |
|---|---|---|
| 输入数据 | 语料库 | 短的随机游走序列集合 |
| 输入数据 | 词汇表 | 节点集合 |
| 词语出现的频次服从幂律分布 | 随机游走时顶点被访问到的次数服从幂律分布 | |
| 不考虑窗口中上下文节点到中心节点的距离的影响, 只关心与中心节点是否同时出现。 |
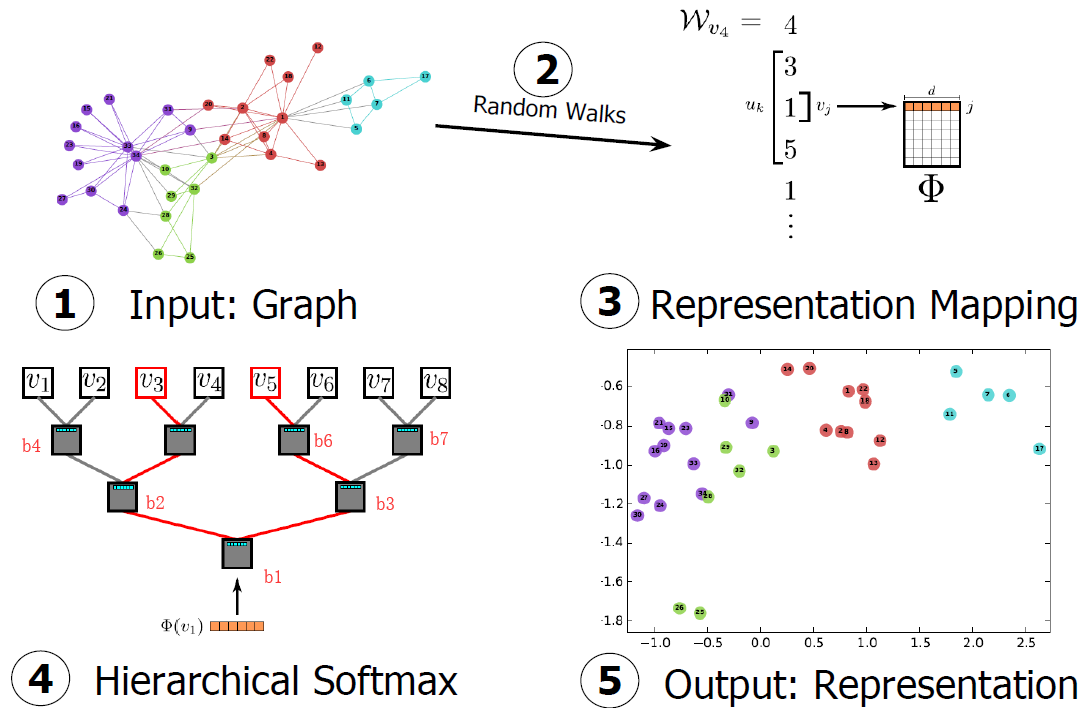
Random Walks
对于每个节点产生 y个游走(相当于 γ \gamma γ 个epoch);每一轮游走中所有节点都进行一次随机游走。对于每个节点 v i v_i vi, 产生长度为 t t t 的随机游走 W v i W_{v_i} Wvi来更新表示。使用SkipGram算法更新。
Hierarchical Softmax
计算
P
(
v
3
∣
Φ
(
v
1
)
)
P(v_3 | \Phi(v_1))
P(v3∣Φ(v1)) 复杂度为
O
(
∣
V
∣
)
O(|V|)
O(∣V∣) ,太耗时。考虑将图节点作为二叉树的叶子节点,最大化
P
(
v
3
∣
Φ
(
v
1
)
)
P(v_3 | \Phi(v_1))
P(v3∣Φ(v1)) 等价于最大化从根节点到节点
v
3
v_3
v3 的路径的概率。如上图中从根节点到
v
3
v_3
v3 节点的路径为
b
1
,
b
2
,
b
5
b1,b2,b5
b1,b2,b5,将这些节点对应的概率乘积算出
P
(
v
3
∣
Φ
(
v
i
)
)
=
1
(
1
+
e
−
Φ
(
v
1
)
∗
Ψ
(
b
1
)
)
(
1
+
e
Φ
(
v
1
)
∗
Ψ
(
b
2
)
)
(
1
+
e
−
Φ
(
v
1
)
∗
Ψ
(
b
5
)
)
P(v_3|\Phi(v_i)) = \frac{1}{(1+ e^{-\Phi(v_1) * \Psi(b1)}) (1+ e^{\Phi(v_1) * \Psi(b2)}) (1+ e^{-\Phi(v_1) * \Psi(b5)})}
P(v3∣Φ(vi))=(1+e−Φ(v1)∗Ψ(b1))(1+eΦ(v1)∗Ψ(b2))(1+e−Φ(v1)∗Ψ(b5))1
假设从左边是正例,从右边是负例;
Ψ
(
b
1
)
\Psi(b1)
Ψ(b1) 是
b
1
b1
b1的隐含表示;原式复杂度降为
O
(
l
o
g
∣
V
∣
)
O(log|V|)
O(log∣V∣)
为什么计算 P ( v 3 ∣ Φ ( v 1 ) ) P(v_3 | \Phi(v_1)) P(v3∣Φ(v1)) 复杂度为 O ( ∣ V ∣ ) O(|V|) O(∣V∣)
计算 P ( v 3 ∣ Φ ( v 1 ) ) P(v_3 | \Phi(v_1)) P(v3∣Φ(v1))使用多项逻辑斯蒂回归需要所有节点参与复杂度为O(|V|)
训练过程
学习参数
- 节点表示
- 树的二分类器的权重
步骤
- 随机初始化表示
- 对于二叉树每个非叶子结点计算loss函数
- 使用随机梯度下降法同时更新二分类器的权重和节点表示
实现
作者的代码实现中只对图进行随机游走生成语料库,作为输入给word2vec
算法
算法由两部分组成:(1)随机游走生成器(2)更新步骤

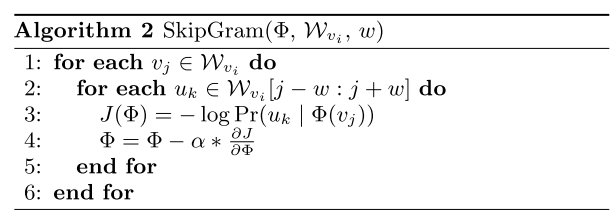
外循环:对于每个节点产生 y个游走
内循环:对于每个节点 v i v_i vi, 产生长度为 t t t 的随机游走 W v i W_{v_i} Wvi来更新表示。使用SkipGram算法更新。
t t t 为每次随机游走的长度,这样后续构造出来的所有序列都是等长的。
γ \gamma γ 为每个点作为随机游走序列起点的次数
问题
- 为什么说明图的随机游走节点访问频率与语言模型中单词频率都符合幂律分布就说明二者近似?
- 对于新加入节点,怎么得到其表示?
- 参数设置:窗口大小等















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









