







题目:Attributed Social Network Embedding
作者:lizi liao , Xiangnan He , Hanwang Zhang, and Tat-Seng Chua
来源:TKDE 2018
本文提出了一个结合拓扑结构和任意类型属性的网络表示学习方法
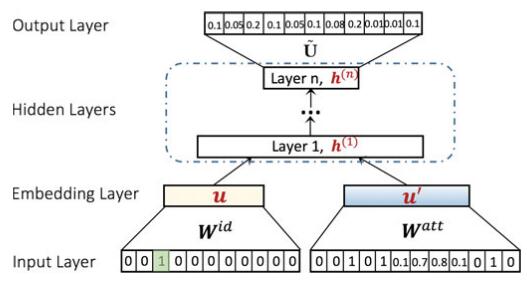
工作流程:
先将拓扑节点的ont-hot和属性分别做一层embedding,然后加权拼接作为DNN的输入;DNN的最后一隐层作为target embedding,隐层到输出层是一个softmax计算每个节点对的概率。
模型
Structure Modeling
用softmax定义条件概率
p
(
u
j
∣
u
i
)
=
exp
(
f
(
u
i
,
u
j
)
)
∑
j
′
=
1
M
exp
(
f
(
u
i
,
u
j
′
)
)
p\left(u_{j} | u_{i}\right)=\frac{\exp \left(f\left(u_{i}, u_{j}\right)\right)}{\sum_{j^{\prime}=1}^{M} \exp \left(f\left(u_{i}, u_{j^{\prime}}\right)\right)}
p(uj∣ui)=∑j′=1Mexp(f(ui,uj′))exp(f(ui,uj))
其中
f
(
u
i
,
,
u
j
′
)
f\left(u_{i,}, u_{j^{\prime}}\right)
f(ui,,uj′) 代表两个节点
u
i
u_i
ui和
u
j
u_j
uj的相似度度量,大多数相关工作都是直接用向量内积计算。文中提出简单地进行embedding向量内积计算相似度,限制了模型的表示能力,会导致很大的ranking loss。为了捕捉复杂的非线性关系,提出采用深度结构建模pairwise节点相似度
f
i
d
(
u
i
,
u
j
)
=
u
~
j
⋅
δ
n
(
W
(
n
)
(
…
δ
1
(
W
(
1
)
u
i
+
b
(
1
)
)
…
)
+
b
(
n
)
)
\begin{array}{l}{f_{i d}\left(u_{i}, u_{j}\right)} \\ {=\tilde{\mathbf{u}}_{j} \cdot \delta_{n}\left(\mathbf{W}^{(n)}\left(\ldots \delta_{1}\left(\mathbf{W}^{(1)} \mathbf{u}_{i}+\mathbf{b}^{(1)}\right) \ldots\right)+\mathbf{b}^{(n)}\right)}\end{array}
fid(ui,uj)=u~j⋅δn(W(n)(…δ1(W(1)ui+b(1))…)+b(n))
(最后还是用的内积,只不过内部是多层神经网络)
Encoding Attributes
将不同类型的属性都统一到同一个向量空间:离散属性,连续属性
ASNE
将拓扑结构和属性结合,最直观的方式是将两个训练完后embedding串联在一起,称为late fusion方式。LINE就是采用这种方法。该方法主要缺点是两种embedding是分别独自训练,在训练完成后简单拼接。
与late fusion相对应,early fusion同时优化所有的参数,结构和属性两部分在训练过程中科紧密结合在一起。本文采用的是late fusion方式。
训练
优化目标
Θ
∗
=
arg
max
Θ
∏
i
=
1
M
∏
j
∈
N
i
p
(
u
j
∣
u
i
)
=
arg
max
Θ
∑
u
i
∈
M
∑
u
j
∈
N
i
log
p
(
u
j
∣
u
i
)
=
arg
max
Θ
∑
u
i
∈
M
∑
u
j
∈
N
i
log
exp
(
u
~
j
⋅
h
i
(
n
)
)
∑
j
′
∈
M
exp
(
u
~
j
⋅
h
i
(
n
)
)
\begin{aligned} \Theta^{*} &=\underset{\Theta}{\arg \max } \prod_{i=1}^{M} \prod_{j \in \mathcal{N}_{i}} p\left(u_{j} | u_{i}\right) \\ &=\underset{\Theta}{\arg \max } \sum_{u_{i} \in M} \sum_{u_{j} \in N_{i}} \log p\left(u_{j} | u_{i}\right) \\ &=\underset{\Theta}{\arg \max } \sum_{u_{i} \in M} \sum_{u_{j} \in \mathcal{N}_{i}} \log \frac{\exp \left(\tilde{\mathbf{u}}_{j} \cdot \mathbf{h}_{i}^{(n)}\right)}{\sum_{j^{\prime} \in M} \exp \left(\tilde{\mathbf{u}}_{j} \cdot \mathbf{h}_{i}^{(n)}\right)} \end{aligned}
Θ∗=Θargmaxi=1∏Mj∈Ni∏p(uj∣ui)=Θargmaxui∈M∑uj∈Ni∑logp(uj∣ui)=Θargmaxui∈M∑uj∈Ni∑log∑j′∈Mexp(u~j⋅hi(n))exp(u~j⋅hi(n))
其中分母还是采用了负采样
∇
log
p
(
u
j
∣
u
i
)
=
∇
f
(
u
i
,
u
j
)
−
∑
j
′
∈
M
p
(
u
j
′
∣
u
i
)
∇
f
(
u
i
,
u
j
′
)
\nabla \log p\left(u_{j} | u_{i}\right)=\nabla f\left(u_{i}, u_{j}\right)-\sum_{j^{\prime} \in M} p\left(u_{j^{\prime}} | u_{i}\right) \nabla f\left(u_{i}, u_{j^{\prime}}\right)
∇logp(uj∣ui)=∇f(ui,uj)−j′∈M∑p(uj′∣ui)∇f(ui,uj′)
实现细节
优化器采用Adam。为了解决internal covariate shift问题,在多层神经网络中采用了batch normalization,每一层还添加了dropout防止过拟合。最后使用 h ( n ) + u ~ \mathbf{h}^{(n)}+\tilde{\mathbf{u}} h(n)+u~ 作为最终的表示。
实验
baseline
structure-based:node2vec,LINE,sSNE( λ = 0 \lambda = 0 λ=0只用拓扑部分)
early fusion:node2vec+attr,LINE+attr
attrubute+structure:TriDNR,AANE,ASNE
RQ1 ASNE效果是否比其他方法好
λ \lambda λ 的影响
λ = 0 \lambda = 0 λ=0是纯拓扑模型, λ \lambda λ值很大时是纯属性模型。各个数据集的最佳参数都在当 λ \lambda λ 处于 [0,1] 区间内得到。在该区间内,性能随着 λ \lambda λ 的增加而提升。
RQ2 ASNE效果好的原因
node2vec > LINE:在社交网络中存在大量的高阶关系,node2vec通过随机游走可以捕捉高阶关系,而LINE只能建模一阶和二阶关系。
node2vec+attr > node2vec,LINE+attr > LINE:说明属性可以带来性能提升,尤其是在链接稀疏的网络,纯靠拓扑的方案性能差。而简单的early fusion方式将两种embedding拼接带来的提升也比较有限。
attrubute+structure > early fusion > structure-based:合适的结合方式 > 简单拼接 > 纯拓扑方法
ASNE > TriDNR,AANE:尽管TriDNR是一个利用属性和拓扑的模型,但是拓扑和属性是分别训练的;AANE通过计算余弦相似度,将余弦相似度投影成pair-wiseregularizer,将属性压缩到一个固定的相似度矩阵。这样很难捕捉细粒度的属性交互以及高阶结构相似性。
RQ3 更深的网络是否有效
有效;ASNE当 λ = 0 \lambda = 0 λ=0, 只采用拓扑作为输入,其实模型已经退化为node2vec,只不过中间多了几层网络。其性能略优于node2vec,说明更深的网络能带来泛化能力的提升。
更深的网络能带来性能提升,但是太深的网络会难以训练,带来过拟合问题等导致性能下降。
Q&A
-
使用early fusion方法结合不同属性的相关工作
Deep crossing [46] and Neural Factorization Machines [47]
-
文中提出简单地进行embedding向量内积计算相似度,限制了模型的表示能力,会导致很大的ranking loss?文中使用DNN是怎么解决的?
-
拓扑的输入是one-hot的形式,是否可以换成邻接矩阵作为输入,理论上邻接矩阵向量相似的节点其最终表示也相似。















 8263
8263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









