







机器学习,特别是聚类算法,可以用来确定哪些地理区域经常被一个用户访问和签到而哪些区域不是。这样的地理分析使多种服务成为可能,比如基于地理位置的推荐系统,先进的安全系统,或更通常来说,提供更个性化的用户体验。
在这篇文章中,我会确定对每个人来说特定的地理活动区域,讨论如何从大量的定位事件中(比如在餐厅或咖啡馆的签到)获取用户的活动区域来构建基于位置的服务。举例来说,这种系统可以识别一个用户经常外出吃晚饭的区域。
使用DBSCAN聚类算法
首先,我们需要选择一种适用于定位数据的聚类算法,可以基于提供的数据点的局部密度确定用户的活动区域。DBSCAN算法是一个不错的选择,因为它自下而上地选择一个点并在一个给定的距离寻找更多的点。然后通过重复这个过程扩展寻找新的点来扩展类簇,直到无法再扩大为止。
这个算法可以通过两个参数进行调试: ε,用来确定离给定的点多远来搜索;和minPoints,即为了类簇扩展,决定一个给定的点的邻域附近最少有多少点。通过寻找邻近点,本地类簇开始出现,各种形状的类簇逐渐可以被识别(请参见图1的简化描述)。过于孤立的点和离其他点太远的点则会被分配到一个特殊的异常值集群。这些独特的属性使DBSCAN算法适合对地理定位事件进行聚类。
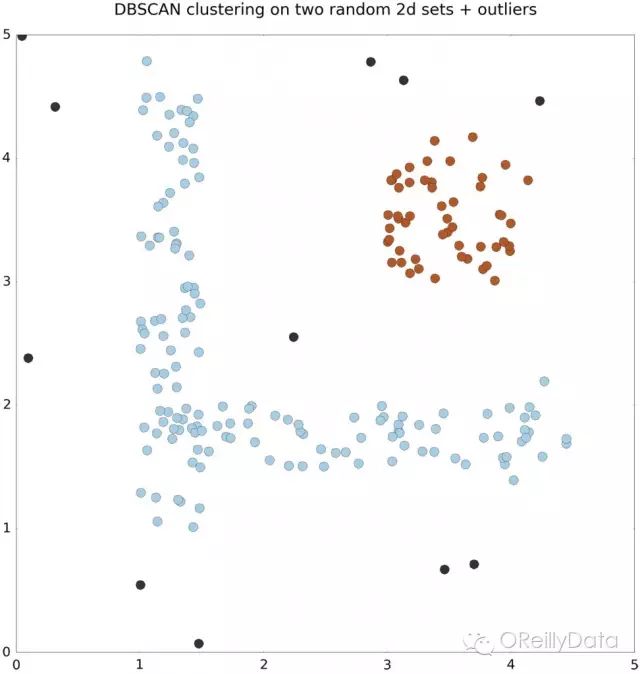
图1:两由DBSCAN算法(ε= 0.5和minPoints = 5)聚类得出的两个类簇。一个是L型,另一个是圆形。互相靠近的点被分配到相同的类簇。黑色的孤立点被视为“异常点”。图片来自Natalino Busa。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









