







1.论文摘要
1.提出利用有标签的合成数据集A和无标签的真实数据集B训练出能泛化到未知场景C的模型。
2.为了实现A+B->C,论文提出了一个新的方法DomainMix
2.DomainMix框架
1.该框架由基于聚类的动态训练数据集生成和域不变的行人再识别特征学习两部分组成。
2.动态训练数据集生成部分,我们设计了三个准则用于筛选聚类结果,由此动态生成可靠的训练集
3.在域不变的行人再识别特征学习部分我们分为训练前和训练时两个阶段。训练前对分类层动态的初始化,可以加速分类损失的收敛;训练时,除了使用常用的损失函数,我们又引入了域平衡损失来学习域不变的特征。

2.1 动态训练数据集生成
在每个训练段,给DomainMix框架的训练数据集是动态产生的。可靠的数据根据 3 个准则被挑选,即:独立性、紧凑性、数量。
对于独立性和紧凑性: 他们来自论文SpCL,用来判断一个聚类是否远离其他的聚类和在同一个聚类里的样本是否有较小的间距。
对于数量: 我们认为一个可靠的聚类应该包含足够多的样本以带来多样性。
在可靠的聚类中的图片被保留下来,打上伪标签,和有标签的虚拟数据集一起训练。
2.2 自适应分类器初始化
因为训练集是在每个训练段动态产生的,所以训练集中类别数不是固定的。于是, 我们无法在全部训练过程中使用同一个分类层,同时,随机初始化会带来不收敛的问题。
所以,我们使用了自适应分类器初始化的方法来加快和保证分类器训练的收敛。一个分类层可以被分为合成部分和真实部分。
分类层用数学公式我们描述为:
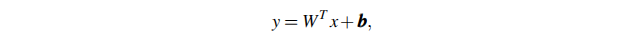
参数详情:

对于合成部分即W1: 因为合成域的类别数在不同的epoch不变化,所以,每到一个新epoch时,w1直接被初始化为上一个epoch的训练结果即可。
对于真实部分W2 as (w1,w2,...wM-N),因为聚类和选择在不断地发生,所以M一直在变化。wi被描述为:
 通过该公式我们可以看出每个小w被初始化为聚类中向量的中心。多个小w构成最后的w作为参数传给分类层。
通过该公式我们可以看出每个小w被初始化为聚类中向量的中心。多个小w构成最后的w作为参数传给分类层。
2.3 域不变和有区分性的特征学习
经过2.1,2.2的探讨知道了训练集的产生方式还知道如何初始化网络,这样我们有了数据集和初始化好的网络就要接下来探讨如何从两个域去学习有区分度、域不变、可以泛化的特征。
为了提取这些特征我们引入域分类器和骨干网络(backbone)
具体来讲,来自合成域和真实域的图片的特征被骨干网络所提取
然后,域分类器被训练来判断提取的特征来自哪一个域。
那么一个是用来提取不变的特征,一个还是分类,如何有效的综合利用它们两个呢? 答案就是交替的使用两者。
对于训练分类器我们采用的是交叉熵损失Lce,因此其域分类损失可以定义为:
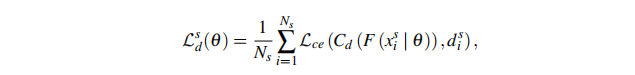
参数详情:
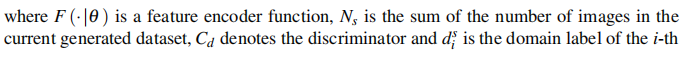
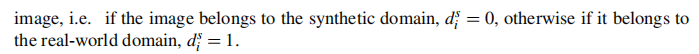
论文鼓励骨干网络去提取域不变的特征,它被训练来迷惑域分类器:
因此,我们提出了一个域平衡损失函数,定义如下:
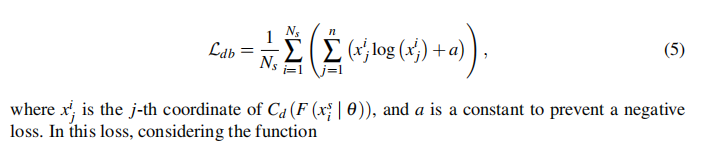
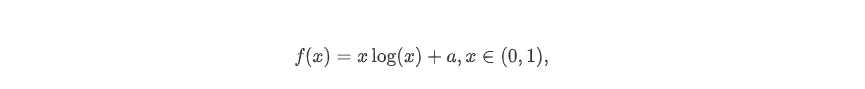
f的二阶导数为
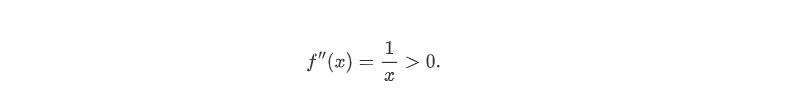
下面完全引入来源博客的一句话来解释损失函数的原理:

通过上述的两个损失函数 一个提取不变特征,一个进行分类,交替使用配合进行最终就能提取有区分度、域不变、可以泛化的特征。















 1124
1124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









