






论文名称: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文下载链接:https://arxiv.org/abs/2010.11929
原论文对应源码:https://github.com/google-research/vision_transformer
Pytorch实现代码: pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
B站视频链接:ViT论文逐段精读【论文精读】_哔哩哔哩_bilibili
ViT主要应用于图像分类问题,视觉的其他问题(检测,分割等)效果没有CNN效果好,因为没有平移不变形局部连接等其他特性。
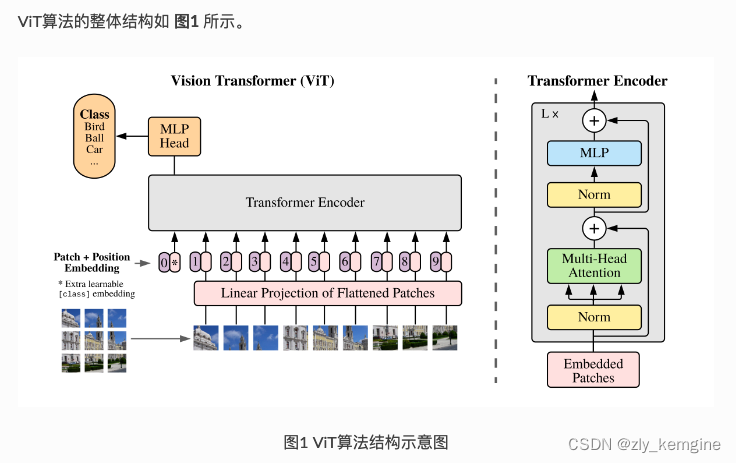
ViT中的具体实现方式为:将 𝐻×𝑊×𝐶𝐻×𝑊×𝐶 的图像,变为一个 𝑁×(𝑃2∗𝐶)𝑁×(𝑃2∗𝐶) 的序列。这个序列可以看作是一系列展平的图像块,也就是将图像切分成小块后,再将其展平。该序列中一共包含了 𝑁=𝐻𝑊/𝑃2𝑁=𝐻𝑊/𝑃2 个图像块,每个图像块的维度则是 (𝑃2∗𝐶)(𝑃2∗𝐶)。其中 𝑃𝑃 是图像块的大小,𝐶𝐶 是通道数量。经过如上变换,就可以将 𝑁𝑁 视为sequence的长度了。
但是,此时每个图像块的维度是 (𝑃2∗𝐶)(𝑃2∗𝐶),而我们实际需要的向量维度是 𝐷𝐷,因此我们还需要对图像块进行 Embedding。这里 Embedding 的方式非常简单,只需要对每个 (𝑃2∗𝐶)(𝑃2∗𝐶) 的图像块做一个线性变换,将维度压缩为 𝐷 即可。
-
Class Token
假设我们将原始图像切分成 3×33×3 共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢?
我们可以想象,如果没有这个向量,也就是将 𝑁=9𝑁=9 个向量输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?因此,ViT算法提出了一个可学习的嵌入向量 Class Token,将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。
其实这里也可以理解为:ViT 其实只用到了 Transformer 中的 Encoder,而并没有用到 Decoder,而 Class Token 的作用就是寻找其他9个输入向量对应的类别。
另外“将前n个token做平均作为要分类的特征是否可行呢”,这也是一种全局特征聚合的方式,但它相较于采用attention机制来做全局特征聚合而言表达能力较弱。因为采用attention机制来做特征聚合,能够根据query和key之间的关系来自适应地调整特征聚合的权重,而采用求平均的方式则是对所有的key给了相同的权重,这限制了模型的表达能力。
-
Positional Encoding
按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 𝑠𝑖𝑛𝑐𝑜𝑠𝑠𝑖𝑛𝑐𝑜𝑠 编码,而是直接设置为可学习的 Positional Encoding。
















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









