







一、距离:
1.1 明可夫斯基距离(Minkowski Distance)
公式:
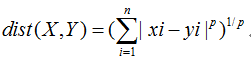
其中p是一个变量,下面的所有距离都是这个公式的特例;
p=1就是曼哈顿距离, P=2就是欧式距离,P=无穷时,就是切比雪夫距离.
1.2 欧几里得距离(Euclidean Distance)
最常见的欧式距离就是平面上两点间的距离D=sqrt(x^2+y^2);
通用的公式为:
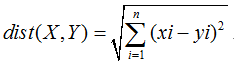
1.3 曼哈顿距离(Manhattan Distance)
曼哈顿距离来源于城市区块距离,是将多个维度上的距离进行求和后的结果
公式:
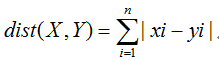
假设下面就是曼哈顿街区,两个顶点之间的距离,无论怎么走,最近的方法都是2+3=5;
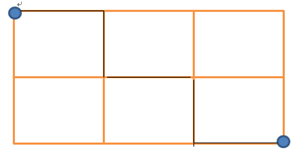
1.4 切比雪夫距离(Chebyshev Distance)
切比雪夫距离起源于国际象棋中国王的走法,我们知道国际象棋国王每次只能往周围的8格中走一步,那么如果要从棋盘中A格(x1, y1)走到B格(x2, y2)最少需要走几步?
公式:

假设下面是棋盘的一小块,国王要从A到B,只能横,竖,斜地走.那么无论怎么走,最短距离始终是7=max(4,7);

Bregman 散度距离
(BregmanDivergence)
形式如下:
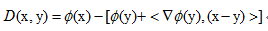
其中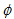
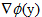
我们把y=x^2作为
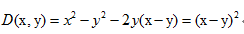
即得到欧式距离。
Bregman距离的数学性质及推导不知,wiki上说,其为许多常见距离的一个通式。
wiki http://en.wikipedia.org/wiki/Bregman_divergence
其中包括欧式距离,曼哈顿距离,KL距离等等。水平有限,只能引用到此。
mahalanobis距离
马氏距离:
首先考虑欧式距离,欧式距离有两点明显的缺点:
1.把不同量纲级别的属性同等看待
比如一个特征向量包含人的年龄,收入,那么收入得到的点乘会远远大于年龄,使得年龄没有作用。
一般的做法是归一化属性值。
2.属性间相关性
一个人的体重很多时候正比于身高。如果作为特征中的两个属性,就会重复计算这个值,得到冗余信息。
一种做法是做去相关,降维,特征选择等等。
不同与欧式距离,马氏距离考虑了量纲即属性间相关性。如下:
M(x,y)=(x-y)sigm(x-y)T
其中sigm表示整体特征向量的协方差矩阵。
马氏距离的最大缺点就是计算复杂度要高出很多,具体运用时要考虑这个因素。
补充
补充之前距离没写到的一些信息:
转换 transformation
有时候,我们得到了距离,进而可以用这个距离求相似性。如:
s表示相关性,d表示距离,则有:
s = -d
s=1/(1+d) 这种方法把距离映射到(0-1)的相似性空间中
s=e^-d 这种方法为非线性映射
s = 1-(d-mind)/(maxd-mind) 也是一种把距离映射到(0-1)上的方法,不过这种是线性的。
小结:任意一种递减的函数都可以把d映射为s度量
归一化normalization
像cosine这种,本身就是(-1,1)的数据,可以直接使用。不过很多情况下,如欧式距离,range都无从控制。归一化是必须的。
度量(metric)
满足以下几种性质的量,可以成为度量(metric):
非负性
(a)d(x,y)>=0
(b)d(x,y)=0 if x==y
对称性
d(x,y) = d(y,x) for all x,y
三角性
d(x,z)<= d(x,y) + d(y,z)
metrics对于许多算法是必须的,不过很多情况下,不必满足metrics也可以作为距离度量。
有再看到类似的再更新。
二、相关性度量
相关性是统计学上的概念.在机器学习中,经常要衡量两个变量的相关性,比如K-mean聚类算法等.这里做一个简单的小结。
补充
我们可以从距离直接得到相似性,如:
s表示相关性,d表示距离,则有:
s = -d
s=1/(1+d) 这种方法把距离映射到(0-1)的相似性空间中
s=e^-d 这种方法为非线性映射
s = 1-(d-mind)/(maxd-mind) 也是一种把距离映射到(0-1)范围上的方法,不过这种是线性的。
小结:任意一种递减的函数都可以把d映射为s度量
2.1 向量空间余弦相似度
指的是两个向量夹角余弦值,体现的更多是两个向量在方向上的差异.

我们看下面这幅图,他表征了余弦相似与欧式距离的差异.余弦更注重线性方向,而欧式距离则注重绝对距离.

补充:对于稀疏的非二进制属性,cosine距离是比较好的选择。
2.2 person相关系数
X和Y基于自身总体标准化后计算空间向量的余弦夹角
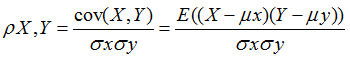
皮尔森相关系数表示两个变量分布的线性关系.
如果Y=kX+b,那么X完全由Y线性决定,皮尔森系数为+1,-1;
如果Y=X^2,虽然X完全由Y决定,但不是线性的;皮尔森系数为0;
假设X,Y两个变量,他们的分布在二维平面上表示如下.通过下图观察他们的线性相关性.

第二行的图明显都有Y=kX+b;相关系数为1或-1;
第三行虽然图像很漂亮,不过应该都是非线性的相关,皮尔森系数为0;
余弦夹角与皮尔森相关系数的联系与区别:
我们把皮尔森相关系数用向量的形式展开,得到:
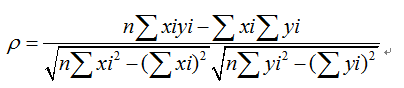
对比余弦夹角,我们可以看出,皮尔森相关系数分子分母都有与余弦夹角相同的项,只不过都减去了一个均值。
于是我们得出:皮尔森相关系数=中心化之后的余弦夹角。
如wiki上的一个实例:
例如,有5个国家的国民生产总值分别为 10, 20, 30, 50 和 80 亿美元。 假设这5个国家 (顺序相同) 的贫困百分比分别为 11%, 12%, 13%, 15%, and 18%。 令 x 和 y 分别为包含上述5个数据的向量: x = (1, 2, 3, 5, 8) 和 y = (0.11, 0.12, 0.13,0.15, 0.18)。
利用通常的方法计算两个向量之间的夹角, 未中心化 的相关系数是:
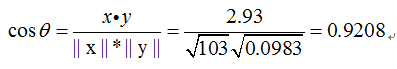
我们发现以上的数据特意选定为完全相关: y = 0.10 + 0.01 x。 于是,皮尔逊相关系数应该等于1。将数据中心化(通过E(x) = 3.8移动 x 和通过 E(y) = 0.138 移动 y ) 得到 x = (−2.8, −1.8, −0.8, 1.2,4.2) 和 y = (−0.028, −0.018,−0.008, 0.012, 0.042), 从中,
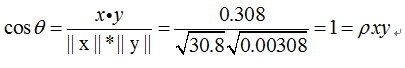
2.3 spearman秩相关系数
又称等级相关系数,或顺序相关系数,是将两样本值按数据的大小顺序排列位次.
再以排序后的位置替换原来的元素 ,即用rank进行皮尔森相关系数计算.
下面式子中x,y分别表示排序后的等级rank.
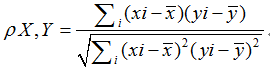
斯皮尔曼相关系数指示的是两个变量是否单调相关,无论是否线性.如下图:
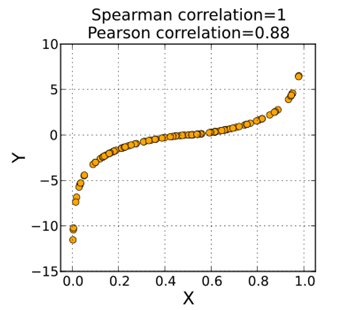
X,Y是单调上升相关的,虽然非线性,斯皮尔曼系数为1;
比如我们统计经济是否随着人口增加而增加,通过计算它们的斯皮尔曼相关系数就能得到.
2.4 Jaccard相似系数(Jaccard Coefficient)
Jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只关心个体间共同具有的特征是否一致这个问题。如果比较X与Y的Jaccard相似系数,只比较xn和yn中相同的个数,公式如下:

如集合A={1,2,3,4};B={3,4,5,6};
那么他们的J(X,Y)=1{3,4}/1{1,2,3,4,5,6}=1/3;
补充:Jaccard距离的非二进制补充是tonimoto距离
KL距离
虽然写的是距离,但个人觉得放在相关性这里比较适合.
KL距离也叫做相对熵,是基于统计学与信息论的相关系数,是两个概率分布P和Q差别的非对称性的度量.
公式:
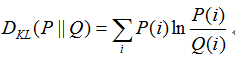
更进一步的,互信息为P(X,Y)与P(X)P(Y)的KL距离.
KL距离具有不对称性,即P到Q的KL距离,不等于Q到P的KL距离。
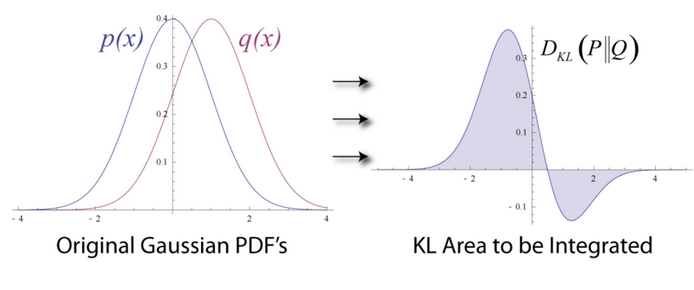
由于KL距离的不对称性,Kullback and Leibler定义了一种对称的距离:D(P||Q)+D(Q||P),这个公式经常被用于分类中的特征选择,P和Q为特征在两个class中的分布.
关于KL距离,具体可见blog:
http://blog.csdn.net/ice110956/article/details/17120461
2.5 Tanimoto 系数
Tanimoto系数由Jaccard系数扩展而来。首先引入Jaccard系数。
Jaccard系数
两个特征向量A,B,如果其值都是0,1的二值数据,那么有一个简单的判定相似性的方法:
F00 = A中为0并且B中也为0的个数
F10 = A1 B0的个数
F01 = A0 B1的个数
F11 = A1 B1 的个数
那么可以定义这么一个similarity:
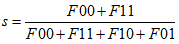
这叫做(simplematch coefficient)SMC,简单匹配系数。
很多情况下,两个向量中,0的个数会大大多于1的个数,也就很稀疏,类不平衡。这时候不同向量之间的SMC会因为过多出现的0而没有效果。
那么我们可以只考虑F11,得到:
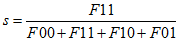
这也就是Jaccard距离。
如果把两个向量看作两个集合,0为此元素不存在,1为此元素存在,那么Jaccard距离就是很好地比较两个集合相似性的度量方法。在集合的相似度计算中,Jaccard距离可以写成:
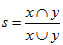
扩张Jaccard
如果这个时候,还是很稀疏,但是值是非二值的,该怎么办?
一种简单的方法就是用cosine距离:
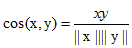
cosine距离是处理稀疏非二值特征的很好的选择。
但是,我们还想以Jaccard距离的思维来做又要如何?如下:
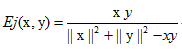
如果我们的x,y都是二值向量,那么如上公式就会得到Jaccard距离。
分子项,只有两个均非0才会有非0的有用结果,类似于F11,不过这里不是简单的计数,而是用数乘来表示。
分母项,2范数表示大小,也只有非0的项才有贡献,再减去xy即共同的,这个类似
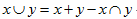
以上是通过观察得出的结论,具体推导不知。
SMC距离在一般的非不平衡二值问题上计算应该比较方便。
Jaccard在文本分类等不平衡二值问题上有所作为
Tanimoto的话,没用过,效果不知道有没有cosine好。应该会得到一个类似cosine的结果。
补充
度量空间(metrics)需要满足一下三个要求:
非负性
(a)d(x,y)>=0
(b)d(x,y)=0 if x==y
对称性
d(x,y) = d(y,x) for all x,y
三角性
d(x,z)<= d(x,y) + d(y,z)
metrics对于许多算法是必须的,不过很多情况下,不必满足metrics也可以作为距离度量。
Reference:
http://blog.csdn.net/ice110956/article/details/14143991















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









