







DEFA: Efficient Deformable Attention Acceleration via Pruning-Assisted Grid-Sampling and Multi-Scale Parallel Processing论文解读
这是一篇2024年3月发布在arxiv上面的论文,算是为数不多的对可变形注意力机制进行加速的论文。
论文地址:点击跳转https://arxiv.org/abs/2403.10913
摘要:这篇论文针对可变形注意力进行加速,提出了一种专用的算法架构协同设计,称为DEFA,这是msformattn加速的首个同类方法。在算法层面,DEFA对特征映射和采样点分别采用频率加权剪枝和概率感知剪枝,减少了80%以上的内存占用。在架构层面,它探索了多尺度并行性来显著提高吞吐量,并通过细粒度层融合和特征映射重用进一步减少内存访问。在代表性基准测试中进行了广泛评估,与强大的gpu相比,DEFA实现了10.1-31.9倍的加速提升和20.3-37.7倍的能效提升。它还可以与相关加速器竞争2.2-3.7倍的能效提升,同时为MSDeformAttn提供开创性的支持。
文章在引言的末尾提到:文章总共有4个贡献:
(1)全面表征了MSDeformAttn在可变形变压器中的性能瓶颈,找出了部署效率低下的根本原因。
(2)算法方面提出了频率加权fmap修剪(FWP)和概率感知点修剪(PAP)
(3)在硬件层面,设计了一个高效的msformattn架构,同时充分利用了算法级优化带来的性能收益。
(4)在硬件上实现,取得了提速。
论文 算法层面
3.1 PWP:文中提到采样中每个像素的访问概率差异较大,因此作者对像素的采样次数进行统计,然后将采样频率低的像素根据位置进行掩码,从而达到减少内存的目的。
3.2 PAP:设置了一个阈值来过滤掉接近于零的注意概率,它们构成了主导比例(在可变形的DETR中超过80%)。由它们加权的抽样值对聚合结果和检测延迟的贡献很小。因此,对接近于零的注意概率进行修剪,并将点掩码建立为位掩码,以消除对当前MSDeformAttn块中产生零加权采样值的采样点的后续处理。
高吞吐量的Deformble Attention架构的硬件设计
4.1数据流
DEFA重新组织了MSDeformAttn中的操作符,来启用FWP和PAP,减少了计算和内存访问。
首先,计算注意概率,更新点掩码;
然后,在可重构PE阵列中以MM模式生成经点掩码剪枝的掩码采样点,即公式1中的ΔP = QW𝑆。
接下来,掩码fmap的线性投影(V = XW Eq.1)被最后一个msformattn块的fmap掩码修剪,并在PE数组中执行。
最后,DEFA以BA模式用可重构PE阵列处理融合的MSGS和聚合操作符。
同时,fmap掩码生成器接收BI中的采样地址,并对下一个块执行FWP。
4.2 多尺度并行处理
在MSGS的biliner中,在没有bank冲突的情况下,并行计算四个采样点。这需要在一个周期内从16个SRAM组访问16个fmap像素,每个采样点有四个相邻像素。如果DEFA在一层多尺度fmap中处理4个采样点,即在如下图所示进行层内并行处理,则边界范围内的所有像素都以参考点为中心被存储在SRAM中。
 当多个采样像素存储在同一个库中时,这可能导致库冲突。为了防止这一问题,文章提出了基于采样点只与参考点位于多比例尺fmap的同一层的观察的层间并行处理,利用这一点来限制其层内的采样范围。
当多个采样像素存储在同一个库中时,这可能导致库冲突。为了防止这一问题,文章提出了基于采样点只与参考点位于多比例尺fmap的同一层的观察的层间并行处理,利用这一点来限制其层内的采样范围。
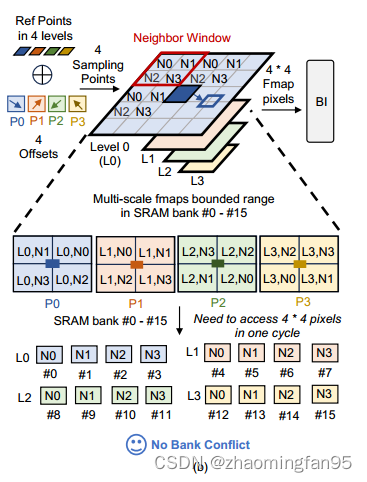
如上图所示,级内并行处理相比,DEFA处理从多比尺fmap的四个级别的参考点延伸出来的四个采样点。此外,每层限定范围内的像素被存储在整个16个SRAM组的每四个组中。有界范围被平铺到几个邻居窗口中,每个邻居窗口中的四个像素被映射到四个SRAM bank。这种方法允许在不同的bank中访问采样像素,而没有任何bank冲突。
4.3 细粒度算子融合与可重构PE阵列
提出了细粒度算子融合MSGS和aggregation,消除了采样值的片外转移。为了在PE阵列有限的计算资源下支持该过程,我们对BI进行了转换,并设计了一个可在BA模式和MM模式之间交替使用的可重构PE阵列,
Bi的的实现如下:
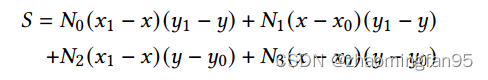
作者将利用 to = y - y0 和 t1 = x - x0,将上式替换为如下:
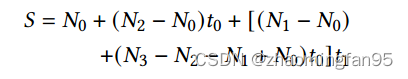
𝑡0和𝑡1的计算在其他单元进行。因此,图3中的BI操作符部分只使用了3个乘数和7个加法器。AG算子部分对注意概率和𝑆进行乘法运算。此外,MM模式下的PE阵列在输出静止数据流中的16元素向量(𝑄)和16 × 16贴图(𝑊)之间进行MM。
5 评估
5.1 实验方法
基准。 论文在Deformable DETR (De DETR)[1]、DN-DETR[4]和DINO[5]编码器中的MSDeformAttn层上评估DEFA。评估任务是在COCO 2017数据集上进行目标检测[15]。作者使用PyTorch在参考官方实现的基准测试上进行实验。通过第3节中的软件方法对修正后的模型进行微调以恢复精度。在推理过程中,模型编码器层中的msformattn模块被量化为12位。作者将DEFA与NVIDIA RTX 2080Ti和3090Ti gpu以及SOTA注意力加速器进行了比较[11,10,12]。
硬件实现。DEFA在SystemVerilog中描述,并使用Synopsys Design Compiler在400MHz时钟频率下进行合成,以估计40nm技术下的面积和功耗。我们实现了一个周期精确模拟器来模拟计算和内存访问,并评估了DEFA的性能。我们使用CACTI获得SRAM的面积和能耗[16],外部存储系统采用中等的256GB/s HBM2,数据访问消耗1.2pJ/b[17]。
5.2 算法评估
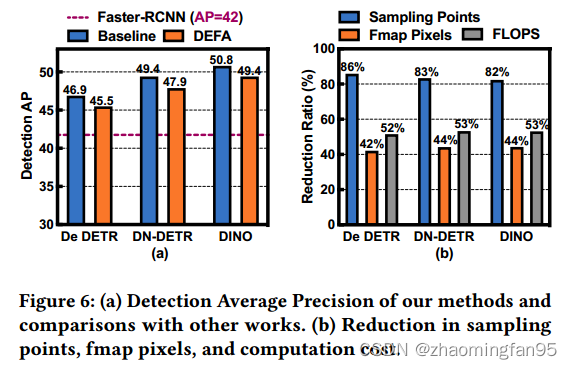
图6 (a)给出了我们的方法的标准平均精度(AP),以及与基准基准和Faster R-CNN的比较[9]。FWP、PAP、水平范围缩小和INT12量化的处理分别导致基准上平均下降0.8、0.3、0.26和0.07 AP。与INT12量化相比,没有采用INT8量化,因为它会导致基准测试平均下降9.7 AP,这是一个不可接受的精度下降。 DEFA保持了相对较高的检测精度,AP损失可以忽略不计,比Faster R-CNN高出3.5-7.4 AP。图6 (b)显示了我们的剪枝算法在采样点、fmap像素和计算成本上的减少比例。FWP和PAP平均减少43%的fmap像素和84%的采样点,并且消除了不重要的fmap像素和采样点的计算成本,占整体计算的50%以上。对于逐级范围缩小,我们在每个级别调整采样偏移的有界范围,以实现精度和SRAM大小之间的权衡。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









