






系列文章目录
语义分割系列——XMem
语义分割系列——Track Anything: Segment Anything Meets Videos
文章目录
论文:https://arxiv.org/abs/2304.11968
GitHub:https://github.com/gaomingqi/track-anything
1. Prerequisite
cd code
git clone https://github.com/gaomingqi/Track-Anything.git
cd Track-Anything
pip install -r requirements.txt
pip install flask
pip install metaseg
pip install sahi
坑1:(ImportError: cannot import name ‘SahiAutoSegmentation’ from ‘metaseg’)
坑2:(灰度图不支持)
坑3:(Something went wrong Connection errored out. Killed 内存不足)
翻译
Track Anything: Segment Anything Meets Videos
Abstract
Recently, the Segment Anything Model (SAM) gains lots of attention rapidly due to its impressive segmentation performance on images. Regarding its strong ability on image segmentation and high interactivity with different prompts, we found that it performs poorly on consistent segmentation in videos. Therefore, in this report, we propose Track Anything Model (TAM), which achieves high-performance interactive tracking and segmentation in videos. To be detailed, given a video sequence, only with very little human participation, i.e., several clicks, people can track anything they are interested in, and get satisfactory results in one-pass inference. Without additional training, such an interactive design performs impressively on video object tracking and segmentation. All resources are available on https://github.com/gaomingqi/Track-Anything. We hope this work can facilitate related research.
最近,Segment Anything Model (SAM) 由于其令人印象深刻的图像分割性能而迅速受到广泛关注。 关于其强大的图像分割能力和与不同提示的高交互性,我们发现它在视频中的一致性分割方面表现不佳。 因此,在本报告中,我们提出了 Track Anything Model (TAM),它可以在视频中实现高性能的交互式跟踪和分割。 具体来说,给定一个视频序列,只需要很少的人为参与,即点击几下,人们就可以跟踪任何他们感兴趣的东西,并在一次推理中得到满意的结果。 在没有额外训练的情况下,这种交互式设计在视频对象跟踪和分割方面表现出色。 所有资源都可以在 https://github.com/gaomingqi/Track-Anything 上找到。 我们希望这项工作能够促进相关研究。
1. Introduction
Tracking an arbitrary object in generic scenes is important, and Video Object Tracking (VOT) is a fundamental task in computer vision. Similar to VOT, Video Object Segmentation (VOS) aims to separate the target (region of interest) from the background in a video sequence, which can be seen as a kind of more fine-grained object tracking. We notice that current state-of-the-art video trackers/segmenters are trained on large-scale manually annotated datasets and initialized by a bounding box or a segmentation mask. On the one hand, the massive human labor force is hidden behind huge amounts of labeled data. Moreover, current initialization settings, especially the semi-supervised VOS, need specific object mask ground truth for model initialization. How to liberate researchers from labor-expensive annotation and initialization is much of important.
在一般场景中跟踪任意对象很重要,而视频对象跟踪 (VOT) 是计算机视觉中的一项基本任务。 与VOT类似,Video Object Segmentation (VOS)旨在将视频序列中的目标(感兴趣区域)从背景中分离出来,这可以看作是一种更细粒度的对象跟踪。 我们注意到,当前最先进的视频跟踪器/分割器是在大规模手动注释数据集上训练的,并由边界框或分割掩码初始化。 一方面,海量的标签数据背后隐藏着庞大的人力资源。 此外,当前的初始化设置,尤其是半监督 VOS,需要特定的对象掩码基本事实来进行模型初始化。 如何将研究人员从耗费人力的注释和初始化中解放出来是非常重要的。
Recently, Segment-Anything Model (SAM) [5] has been proposed, which is a large foundation model for image segmentation. It supports flexible prompts and computes masks in real-time, thus allowing interactive use. We conclude that SAM has the following advantages that can assist interactive tracking: 1) Strong image segmentation ability. Trained on 11 million images and 1.1 billion masks, SAM can produce high-quality masks and do zero-shot segmentation in generic scenarios. 2) High interactivity with different kinds of prompts. With input user-friendly prompts of points, boxes, or language, SAM can give satisfactory segmentation masks on specific image areas. However, using SAM in videos directly did not give us an impressive performance due to its deficiency in temporal correspondence.
最近,Segment-Anything Model (SAM) [5] 被提出,它是图像分割的大型基础模型。 它支持灵活的提示和实时计算掩码,从而允许交互式使用。 我们得出结论,SAM 具有以下可以辅助交互式跟踪的优点:1)强大的图像分割能力。 SAM 在 1100 万张图像和 11 亿个蒙版上进行训练,可以生成高质量的蒙版并在一般场景中进行零镜头分割。 2) 互动性强,多种提示。 通过输入用户友好的点、框或语言提示,SAM 可以在特定图像区域上给出令人满意的分割掩码。 然而,由于时间对应的不足,直接在视频中使用 SAM 并没有给我们带来令人印象深刻的表现。
On the other hand, tracking or segmenting in videos faces challenges from scale variation, target deformation, motion blur, camera motion, similar objects, and so on [4, 8, 10, 7, 9, 6]. Even the state-of-the-art models suffer from complex scenarios in the public datasets [1], not to mention the real-world applications. Therefore, a question is considered by us: can we achieve high-performance tracking/segmentation in videos through the way of interaction?
另一方面,视频中的跟踪或分割面临着来自尺度变化、目标变形、运动模糊、相机运动、相似物体等的挑战[4、8、10、7、9、6]。 即使是最先进的模型也会受到公共数据集 [1] 中复杂场景的影响,更不用说现实世界的应用了。 因此,我们思考一个问题:能否通过交互的方式实现视频中的高性能跟踪/分割?
In this technical report, we introduce our Track-Anything project, which develops an efficient toolkit for high-performance object tracking and segmentation in videos. With a user-friendly interface, the Track Anything Model (TAM) can track and segment any objects in a given video with only one-pass inference. Figure 1 shows the one-pass interactive process in the proposed TAM. In detail, TAM combines SAM [5], a large segmentation model, and XMem [1], an advanced VOS model. As shown, we integrate them in an interactive way. Firstly, users can interactively initialize the SAM, i.e., clicking on the object, to define a target object; then, XMem is used to give a mask prediction of the object in the next frame according to both temporal and spatial correspondence; next, SAM is utilized to give a more precise mask description; during the tracking process, users can pause and correct as soon as they notice tracking failures.
在这份技术报告中,我们介绍了我们的 Track-Anything 项目,该项目开发了一个高效的工具包,用于视频中的高性能对象跟踪和分割。 借助用户友好的界面,Track Anything Model (TAM) 可以仅通过一次推理来跟踪和分割给定视频中的任何对象。 图 1 显示了所提出的 TAM 中的单程交互过程。 详细而言,TAM 结合了大型分割模型 SAM [5] 和高级 VOS 模型 XMem [1]。 如图所示,我们以交互方式集成它们。 首先,用户可以交互式地初始化SAM,即点击对象,定义一个目标对象; 然后,根据时间和空间的对应关系,使用XMem给出下一帧对象的mask预测; 接下来,利用SAM给出更精确的mask描述; 在跟踪过程中,用户可以在发现跟踪失败时立即暂停并纠正。
Our contributions can be concluded as follows:
我们的贡献可以总结如下:
-
We promote the SAM applications to the video level to achieve interactive video object tracking and segmentation. Rather than separately using SAM per frame, we integrate SAM into the process of temporal correspondence construction.
1)我们将 SAM 应用推广到视频级别,以实现交互式视频对象跟踪和分割。 我们不是每帧单独使用 SAM,而是将 SAM 集成到时间对应构建过程中。 -
We propose one-pass interactive tracking and segmentation for efficient annotation and a user-friendly tracking interface, which uses very small amounts of human participation to solve extreme difficulties in video object perception.
2)我们提出了用于高效注释的一次性交互式跟踪和分割和用户友好的跟踪界面,它使用非常少量的人类参与来解决视频对象感知中的极端困难。 -
Our proposed method shows superior performance and high usability in complex scenes and has many potential applications.
3)我们提出的方法在复杂场景中表现出优越的性能和高可用性,具有许多潜在的应用。
2. Track Anything Task
Inspired by the Segment Anything task [5], we propose the Track Anything task, which aims to flexible object tracking in arbitrary videos. Here we define that the target objects can be flexibly selected, added, or removed in any way according to the users’ interests. Also, the video length and types can be arbitrary rather than limited to trimmed or natural videos. With such settings, diverse downstream tasks can be achieved, including single/multiple object tracking, short-/long-term object tracking, unsupervised VOS, semi-supervised VOS, referring VOS, interactive VOS, long-term VOS, and so on.
受 Segment Anything 任务 [5] 的启发,我们提出了 Track Anything 任务,旨在灵活地跟踪任意视频中的对象。 这里我们定义目标对象可以根据用户的兴趣以任何方式灵活地选择、添加或删除。 此外,视频长度和类型可以是任意的,而不限于修剪或自然视频。 通过这样的设置,可以实现多样化的下游任务,包括单/多目标跟踪、短期/长期目标跟踪、无监督 VOS、半监督 VOS、参考 VOS、交互式 VOS、长期 VOS 等。
3. Methodology
3.1 Preliminaries
Segment Anything Model [5]. Very recently, the Segment Anything Model (SAM) has been proposed by Meta AI Research and gets numerous attentions. As a foundation model for image segmentation, SAM is based on ViT [3] and trained on the large-scale dataset SA-1B [5]. Obviously, SAM shows promising segmentation ability on images, especially on zero-shot segmentation tasks. Unfortunately, SAM only shows superior performance on image segmentation, while it cannot deal with complex video segmentation.
Segment Anything Model [5]。 最近,Meta AI Research 提出的 Segment Anything Model (SAM) 受到了广泛关注。 作为图像分割的基础模型,SAM 基于 ViT [3] 并在大规模数据集 SA-1B [5] 上进行训练。 显然,SAM 在图像上显示出很有前途的分割能力,尤其是在零镜头分割任务上。 不幸的是,SAM 仅在图像分割方面表现出优越的性能,而无法处理复杂的视频分割。
XMem [1]. Given the mask description of the target object at the first frame, XMem can track the object and generate corresponding masks in the subsequent frames. Inspired by the Atkinson-Shiffrin memory model, it aims to solve the difficulties in long-term videos with unified feature memory stores. The drawbacks of XMem are also obvious: 1) as a semi-supervised VOS model, it requires a precise mask to initialize; 2) for long videos, it is difficult for XMem to recover from tracking or segmentation failure. In this paper, we solve both difficulties by importing interactive tracking with SAM.
XMem [1]。 给定第一帧目标对象的掩码描述,XMem 可以跟踪对象并在后续帧中生成相应的掩码。 受 Atkinson-Shiffrin 记忆模型的启发,它旨在解决具有统一特征记忆存储的长期视频中的困难。 XMem的缺点也很明显:1)作为半监督的VOS模型,需要精确的mask来初始化; 2)对于长视频,XMem 很难从跟踪或分割失败中恢复。 在本文中,我们通过使用 SAM 导入交互式跟踪来解决这两个困难。
Interactive Video Object Segmentation. Interactive VOS [2] takes user interactions as inputs, e.g., scribbles. Then, users can iteratively refine the segmentation results until they are satisfied with them. Interactive VOS gains lots of attention as it is much easier to provide scribbles than to specify every pixel for an object mask. However, we found that current interactive VOS methods require multiple rounds to refine the results, which impedes their efficiency in real-world applications.
交互式视频对象分割。 交互式 VOS [2] 将用户交互作为输入,例如涂鸦。 然后,用户可以迭代地细化分割结果,直到他们对它们满意为止。 交互式 VOS 获得了很多关注,因为提供涂鸦比指定对象掩码的每个像素要容易得多。 然而,我们发现当前的交互式 VOS 方法需要多轮来改进结果,这阻碍了它们在实际应用中的效率。
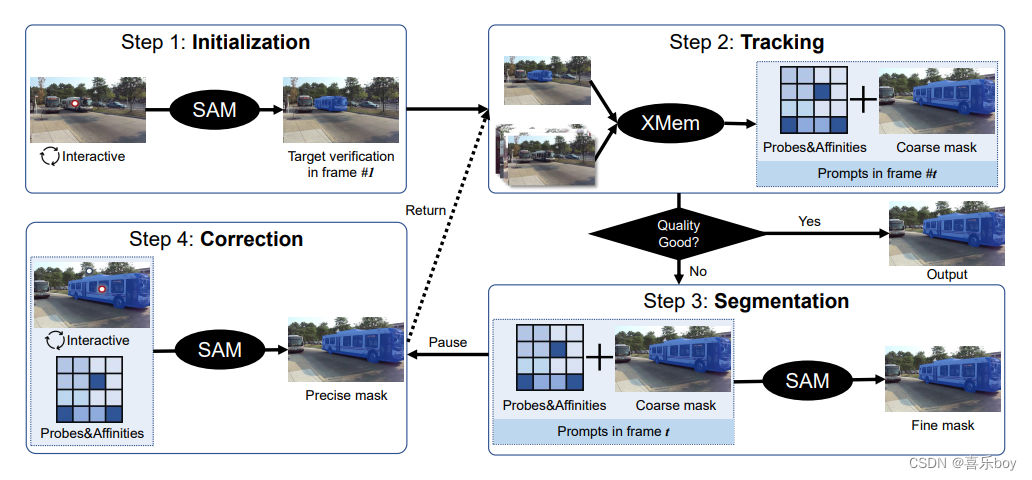
Figure 1: Pipeline of our proposed Track Anything Model (TAM). Only within one round of inference can the TAM obtain impressive tracking and segmentation performance on the human-selected target.
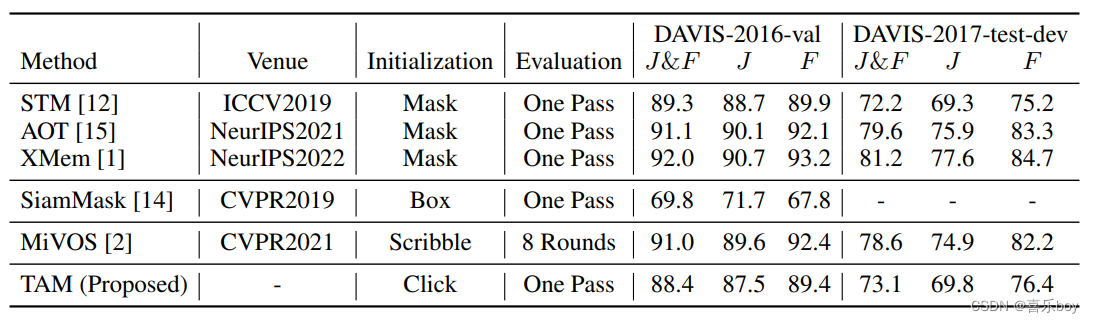
Table 1: Results on DAVIS-2016-val and DAVIS-2017-test-dev datasets [13].
3.2 Implementation
Inspired by SAM, we consider tracking anything in videos. We aim to define this task with high interactivity and ease of use. It leads to ease of use and is able to obtain high performance with very little human interaction effort. Figure 1 shows the pipeline of our Track Anything Model (TAM). As shown, we divide our Track-Anything process into the following four steps:
受 SAM 的启发,我们考虑跟踪视频中的任何内容。 我们的目标是定义具有高交互性和易用性的任务。 它易于使用,并且能够以极少的人机交互工作获得高性能。 图 1 显示了我们的 Track Anything Model (TAM) 的管道。 如图所示,我们将 Track-Anything 过程分为以下四个步骤:
Step 1: Initialization with SAM [5]. As SAM provides us an opportunity to segment a region of interest with weak prompts, e.g., points, and bounding boxes, we use it to give an initial mask of the target object. Following SAM, users can get a mask description of the interested object by a click or modify the object mask with several clicks to get a satisfactory initialization.
第 1 步:使用 SAM [5] 进行初始化。 由于 SAM 为我们提供了使用弱提示(例如点和边界框)分割感兴趣区域的机会,我们使用它来提供目标对象的初始掩码。 按照 SAM,用户可以通过单击获得感兴趣对象的掩码描述,或者通过多次单击修改对象掩码以获得满意的初始化。
Step 2: Tracking with XMem [1]. Given the initialized mask, XMem performs semi-supervised VOS on the following frames. Since XMem is an advanced VOS method that can output satisfactory results on simple scenarios, we output the predicted masks of XMem on most occasions. When the mask quality is not such good, we save the XMem predictions and corresponding intermediate parameters, i.e., probes and affinities, and skip to step 3.
第 2 步:使用 XMem [1] 进行跟踪。 给定初始化的掩码,XMem 对后续帧执行半监督 VOS。 由于 XMem 是一种高级的 VOS 方法,可以在简单场景上输出令人满意的结果,因此我们在大多数情况下输出 XMem 的预测掩码。 当掩码质量不是很好时,我们保存 XMem 预测和相应的中间参数,即探针和亲和力,并跳到步骤 3。
Step 3: Refinement with SAM [5]. We notice that during the inference of VOS models, keep predicting consistent and precise masks are challenging. In fact, most state-of-the-art VOS models tend to segment more and more coarsely over time during inference. Therefore, we utilize SAM to refine the masks predicted by XMem when its quality assessment is not satisfactory. Specifically, we project the probes and affinities to be point prompts for SAM, and the predicted mask from Step 2 is used as a mask prompt for SAM. Then, with these prompts, SAM is able to produce a refined segmentation mask. Such refined masks will also be added to the temporal correspondence of XMem to refine all subsequent object discrimination.
第 3 步:使用 SAM [5] 进行细化。 我们注意到,在 VOS 模型的推理过程中,保持预测一致和精确的掩模具有挑战性。 事实上,大多数最先进的 VOS 模型在推理过程中随着时间的推移倾向于分割得越来越粗。 因此,当 XMem 的质量评估不令人满意时,我们利用 SAM 来改进 XMem 预测的掩码。 具体来说,我们将探针和亲和力投影为 SAM 的点提示,并将步骤 2 中预测的掩码用作 SAM 的掩码提示。 然后,根据这些提示,SAM 能够生成精细的分割掩码。 这种细化的掩码也将被添加到 XMem 的时间对应中,以细化所有后续的对象辨别。

Figure 2: Qualitative results on video sequences from DAVIS-16 and DAVIS-17 datasets [13].

Figure 3: Failed cases.
Step 4: Correction with human participation. After the above three steps, the TAM can now successfully solve some common challenges and predict egmentation masks. However, we notice that it is still difficult to accurately distinguish the objects in some extremely challenging scenarios, especially when processing long videos. Therefore, we propose to add human correction during inference, which can bring a qualitative leap in performance with only very small human efforts. In detail, users can compulsively stop the TAM process and correct the mask of the current frame with positive and negative clicks.
第 4 步:人工参与校正。 经过以上三个步骤,TAM 现在可以成功解决一些常见的挑战并预测分割掩码。 然而,我们注意到,在一些极具挑战性的场景中,尤其是在处理长视频时,准确区分对象仍然很困难。 因此,我们建议在推理过程中加入人工校正,仅需极少的人力即可带来性能的质的飞跃。 具体来说,用户可以强制停止 TAM 过程,并通过正负点击来纠正当前帧的掩码。
4. Experiments
4.1 Quantitative Results
To evaluate TAM, we utilize the validation set of DAVIS-2016 and test-development set of DAVIS-2017 [13]. Then, we execute the proposed TAM as demonstrated in Section 3.2. The results are given in Table 1. As shown, our TAM obtains J&F scores of 88.4 and 73.1 on DAVIS-2016-val and DAVIS-2017-test-dev datasets, respectively. Note that TAM is initialized by clicks and evaluated in one pass. Notably, we found that TAM performs well when against difficult and complex scenarios.
为了评估 TAM,我们利用 DAVIS-2016 的验证集和 DAVIS-2017 的测试开发集 [13]。 然后,我们执行建议的 TAM,如第 3.2 节所示。 结果如表 1 所示。如图所示,我们的 TAM 在 DAVIS-2016-val 和 DAVIS-2017-test-dev 数据集上分别获得了 88.4 和 73.1 的 J&F 分数。 请注意,TAM 通过点击进行初始化,并在一次通过中进行评估。 值得注意的是,我们发现 TAM 在应对困难和复杂的场景时表现良好。
4.2 Qualitative Results
We also give some qualitative results in Figure 2. As shown, TAM can handle multi-object separation, target deformation, scale change, and camera motion well, which demonstrates its superior tracking and segmentation abilities within only click initialization and one-round inference.
我们还在图 2 中给出了一些定性结果。如图所示,TAM 可以很好地处理多目标分离、目标变形、尺度变化和相机运动,这证明了其仅在点击初始化和一轮推理中的卓越跟踪和分割能力。

Figure 4: Raw frames, object masks, and inpainted results from the movie Captain America: Civil War (2016).
4.3 Failed Cases
We here also analyze the failed cases, as shown in Figure 3. Overall, we notice that the failed cases typically appear on the following two occasions. 1) Current VOS models are mostly designed for short videos, which focus more on maintaining short-term memory rather than long-term memory. This leads to mask shrinkage or lacking refinement in long-term videos, as shown in seq (a). Essentially, we aim to solve them in step 3 by the refinement ability of SAM, while its effectiveness is lower than expected in realistic applications. It indicates that the ability of SAM refinement based on multiple prompts can be further improved in the future. On the other hand, human participation/interaction in TAM can be an approach to solving such difficulties, while too much interaction will also result in low efficiency. Thus, the mechanism of long-term memory preserving, and transient memory updating is still important. 2) When the object structure is complex, e.g., the bicycle wheels in seq (b) contain many cavities in ground truth masks. We found it very difficult to get a fine-grained initialized mask by propagating the clicks. Thus, the coarse initialized masks may have side effects on the subsequent frames and lead to poor predictions. This also inspires us that SAM is still struggling with complex and precision structures.
我们在这里也分析了失败的案例,如图3所示。总体而言,我们注意到失败的案例通常出现在以下两种情况。 1)目前的VOS模型大多是为短视频设计的,短视频更注重维持短期记忆而不是长期记忆。 这导致长期视频中的蒙版收缩或缺乏细化,如 seq (a) 所示。 本质上,我们的目标是通过 SAM 的细化能力在步骤 3 中解决它们,而其有效性低于实际应用中的预期。 这表明未来基于多提示的 SAM 细化能力可以进一步提高。 另一方面,TAM 中的人类参与/交互可以成为解决此类困难的一种方法,但过多的交互也会导致效率低下。 因此,长期记忆保存和瞬时记忆更新的机制仍然很重要。 2)当对象结构复杂时,例如,seq (b) 中的自行车车轮在 ground truth masks 中包含许多空腔。 我们发现很难通过传播点击来获得细粒度的初始化掩码。 因此,粗略初始化的掩码可能会对后续帧产生副作用并导致较差的预测。 这也启发我们,SAM 仍在与复杂和精密的结构作斗争。
5. Applications
The proposed Track Anything Model (TAM) provides many possibilities for flexible tracking and segmentation in videos. Here, we demonstrate several applications enabled by our proposed method. In such an interactive way, diverse downstream tasks can be easily achieved.
拟议的 Track Anything Model (TAM) 为视频中的灵活跟踪和分割提供了许多可能性。 在这里,我们展示了我们提出的方法启用的几个应用程序。 通过这种交互方式,可以轻松完成各种下游任务。
Efficient video annotation. TAM has the ability to segment the regions of interest in videos and flexibly choose the objects users want to track. Thus, it can be used for video annotation for tasks like video object tracking and video object segmentation. On the other hand, click-based interaction makes it easy to use, and the annotation process is of high efficiency.
高效的视频注释。 TAM 能够对视频中的感兴趣区域进行分割,灵活选择用户想要跟踪的对象。 因此,它可以用于视频对象跟踪和视频对象分割等任务的视频注释。 另一方面,基于点击的交互使其易于使用,标注过程效率高。
Long-term object tracking. The study of long-term tracking is gaining more and more attention because it is much closer to practical applications. Current long-term object tracking task requires the tracker to have the ability to handle target disappearance and reappearance while it is still limited in the scope of trimmed videos. Our TAM is more advanced in real-world applications which can handle the shot changes in long videos.
长期对象跟踪。 长期跟踪的研究越来越受到关注,因为它更接近实际应用。 当前的长期目标跟踪任务要求跟踪器具有处理目标消失和重新出现的能力,而它仍然局限于修剪视频的范围。 我们的 TAM 在实际应用中更先进,可以处理长视频中的镜头变化。
User-friendly video editing. Track Anything Model provides us the opportunities to segment objects With the object segmentation masks provided by TAM, we are then able to remove or alter any of the existing objects in a given video. Here we combine E2FGVI [11] to evaluate its application value.
用户友好的视频编辑。 Track Anything Model 为我们提供了分割对象的机会使用 TAM 提供的对象分割掩码,我们然后能够删除或更改给定视频中的任何现有对象。 这里我们结合 E2FGVI [11] 来评估其应用价值。
Visualized development toolkit for video tasks. For ease of use, we also provide visualized interfaces for multiple video tasks, e.g., VOS, VOT, video inpainting, and so on. With the provided toolkit, users can apply their models on real-world videos and visualize the results instantaneously. Corresponding demos are available in Hugging Face3.
视频任务可视化开发工具包。 为了便于使用,我们还为多个视频任务提供了可视化界面,例如 VOS、VOT、视频修复等。 使用提供的工具包,用户可以将他们的模型应用到真实世界的视频中,并即时可视化结果。 Hugging Face3 中提供了相应的演示。
To show the effectiveness, we give a comprehensive test by applying TAM on the movie Captain America: Civil War (2016). Some representative results are given in Figure 4. As shown, TAM can present multiple object tracking precisely in videos with lots of shot changes and can further be helpful in video inpainting.
为了展示有效性,我们通过在电影美国队长:内战 (2016) 中应用 TAM 来进行综合测试。 图 4 中给出了一些具有代表性的结果。如图所示,TAM 可以在具有大量镜头变化的视频中精确呈现多个对象跟踪,并且可以进一步有助于视频修复。
References
[1] Ho Kei Cheng and Alexander G. Schwing. Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model. In ECCV (28), volume 13688 of Lecture Notes in Computer Science, pages 640–658. Springer, 2022.
[2] Ho Kei Cheng, Yu-Wing Tai, and Chi-Keung Tang. Modular interactive video object segmentation: Interaction-to-mask, propagation and difference-aware fusion. In CVPR, pages 5559–5568. Computer Vision Foundation / IEEE, 2021.
[3] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR. OpenReview.net, 2021.
[4] Mingqi Gao, Feng Zheng, James J. Q. Yu, Caifeng Shan, Guiguang Ding, and Jungong Han. Deep learning for video object segmentation: a review. Artif. Intell. Rev., 56(1):457–531, 2023.
[5] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
[6] Matej Kristan, Aleš Leonardis, Jiˇrí Matas, Michael Felsberg, Roman Pflugfelder, Joni-Kristian Kämäräinen, Hyung Jin Chang, Martin Danelljan, Luka Cehovin Zajc, Alan Lukeži ˇ c, et al. The tenth visual object tracking vot2022 challenge results. In Computer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VIII, pages 431–460. Springer, 2023.
[7] Matej Kristan, Aleš Leonardis, Jiˇrí Matas, Michael Felsberg, Roman Pflugfelder, Joni-Kristian Kämäräinen, Martin Danelljan, Luka Cehovin Zajc, Alan Lukeži ˇ c, Ondrej Drbohlav, et al. The eighth visual object tracking vot2020 challenge results. In European Conference on Computer Vision, pages 547–601. Springer, 2020.
[8] Matej Kristan, Ales Leonardis, Jiri Matas, Michael Felsberg, Roman Pflugfelder, Luka ˇCehovin Zajc, Tomas Vojir, Goutam Bhat, Alan Lukezic, Abdelrahman Eldesokey, et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018.
[9] Matej Kristan, Jiˇrí Matas, Aleš Leonardis, Michael Felsberg, Roman Pflugfelder, Joni-Kristian Kämäräinen, Hyung Jin Chang, Martin Danelljan, Luka Cehovin, Alan Lukežic, et al. The ninth visual object tracking vot2021 challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2711–2738, 2021.
[10] Matej Kristan, Jiri Matas, Ales Leonardis, Michael Felsberg, Roman Pflugfelder, Joni-Kristian Kamarainen, Luka ˇCehovin Zajc, Ondrej Drbohlav, Alan Lukezic, Amanda Berg, et al. The seventh visual object tracking vot2019 challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019.
[11] Zhen Li, Chengze Lu, Jianhua Qin, Chun-Le Guo, and Ming-Ming Cheng. Towards an end-to-end framework for flow-guided video inpainting. In CVPR, pages 17541–17550. IEEE, 2022.
[12] Seoung Wug Oh, Joon-Young Lee, Ning Xu, and Seon Joo Kim. Video object segmentation using space-time memory networks. In ICCV, pages 9225–9234. IEEE, 2019.
[13] Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbelaez, Alexander Sorkine-Hornung, and Luc Van Gool. The 2017 DAVIS challenge on video object segmentation. CoRR, abs/1704.00675, 2017.
[14] Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, and Philip H. S. Torr. Fast online object tracking and segmentation: A unifying approach. In CVPR, pages 1328–1338. Computer Vision Foundation / IEEE, 2019.
[15] Zongxin Yang, Yunchao Wei, and Yi Yang. Associating objects with transformers for video object segmentation. In NeurIPS, pages 2491–2502, 2021.















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









