







 本文介绍了Track-Anything模型,一种基于SAM和XMem的交互式工具,通过在视频中实现高效的人工参与,显著提升了视频对象跟踪和分割的性能。模型通过结合SAM的分割能力和XMem的跟踪功能,解决了视频中尺度变化等复杂挑战。
本文介绍了Track-Anything模型,一种基于SAM和XMem的交互式工具,通过在视频中实现高效的人工参与,显著提升了视频对象跟踪和分割的性能。模型通过结合SAM的分割能力和XMem的跟踪功能,解决了视频中尺度变化等复杂挑战。
现已总结SAM多方面相关的论文解读,具体请参考该专栏的置顶目录篇
一、总结
1. 简介
发表时间:2023年4月28日
论文:
[2304.11968] Track Anything: Segment Anything Meets Videos (arxiv.org) https://arxiv.org/abs/2304.11968代码:
https://arxiv.org/abs/2304.11968代码:
gaomingqi/Track-Anything: Track-Anything is a flexible and interactive tool for video object tracking and segmentation, based on Segment Anything, XMem, and E2FGVI. (github.com)https://github.com/gaomingqi/Track-Anything
2. 摘要
SAM图像分割能力强,与不同提示的交互性高,但它在视频的一致性分割方面表现不佳。因此,作者提出了跟踪任何模型TAM,它实现了视频中的高性能交互式跟踪和分割。具体来说,给定一个视频序列,只需很少的人为参与,即几次点击,人们就可以跟踪他们感兴趣的任何东西,并在一次推理中获得满意的结果。无需额外的训练,这种交互设计在视频对象跟踪和分割方面表现令人印象深刻。
3.前言
与视频目标跟踪(VOT)类似,视频对象分割(VOS)的目的是将视频序列中的目标从背景中分离出来,可以看作是一种更细粒度的目标跟踪。当前最先进的视频跟踪器/分割器是在大规模手动注释的数据集上训练的,并通过边界框或分割掩码进行初始化。一方面,海量的标签数据背后隐藏着庞大的人类劳动力。另一方面,当前的初始化设置,特别是半监督VOS,需要特定的对象掩码ground truth进行模型初始化。如何将研究人员从耗费人力的注释和初始化中解放出来是非常重要的。
最近提出的SAM是一种大型的图像分割基础模型。它支持灵活的提示和实时计算掩码,拥有强大的图像分割能力,从而允许交互式使用。然而,直接在视频中使用SAM,在时间对应方面存在缺陷。另一方面,视频中的跟踪或分割面临着尺度变化、目标变形、运动模糊、摄像机运动、相似物体等方面的挑战。即使是最先进的模型也会受到公共数据集中复杂场景的影响。因此,我们思考了一个问题:能否通过交互的方式在视频中实现高性能的跟踪/分割?
因此我们提出了Track Anything任务,其目的是在任意视频中灵活地跟踪对象。这里我们定义目标对象可以根据用户的兴趣以任何方式灵活选择、添加或删除。此外,视频的长度和类型可以是任意的,而不是局限于修剪或自然的视频。通过这样的设置,可以实现多种下游任务,包括单/多目标跟踪、短期/长期目标跟踪、无监督VOS、半监督VOS、参考VOS、交互式VOS、长期VOS等。
4. 贡献
(1)将SAM应用提升到视频层面,实现交互式视频对象跟踪和分割。我们将SAM整合到时间对应构建过程中,而不是每帧单独使用SAM。
(2)我们提出了一遍交互式跟踪和分割,以实现高效的注释和用户友好的跟踪界面,使用很少的人工参与来解决视频对象感知的极端困难。
(3)该方法在复杂场景下表现出优异的性能和高可用性,具有广泛的应用前景。
二、模型结构
我们的Track-Anything项目开发了一个高效的工具包,TAM以交互的方式结合了大型分割模型SAM和先进的VOS模型XMem。通过用户友好的界面,TAM可以跟踪和分割给定视频中的任何对象,仅通过一次推理,TAM就能在人类选择的目标上获得令人印象深刻的跟踪和分割性能。
1. SAM
作为图像分割的基础模型,SAM基于ViT,在大规模数据集SA-1B上进行训练。显然,SAM在图像分割上表现出了很好的分割能力,特别是在零镜头分割任务上。遗憾的是,SAM仅在图像分割方面表现出优越的性能,而不能处理复杂的视频分割。
2. XMem
给定第一帧目标对象的掩码描述,XMem可以跟踪该对象,并在随后的帧中生成相应的掩码。该模型旨在通过统一的特征记忆存储来解决长期视频的困难。XMem的缺点也很明显:1)作为半监督VOS模型,需要精确的掩码进行初始化;2)对于长视频,XMem很难从跟踪或分割失败中恢复。在本文中,我们通过引入SAM的交互式跟踪来解决这两个问题。
3. 交互式视频对象分割
交互式VOS将用户交互作为输入,例如涂鸦。然后,用户可以迭代地改进分割结果,直到他们满意为止。交互式VOS获得了很多关注,因为提供涂鸦比为对象掩码指定每个像素要容易得多。然而,我们发现目前的交互式VOS方法需要多轮来改进结果,这阻碍了它们在实际应用中的效率。
4. TAM
受SAM的启发,我们考虑跟踪视频中的任何东西。我们的目标是定义具有高交互性和易用性的任务,它易于使用,并且能够以很少的人工交互工作获得高性能。如下图所示,我们将Track-Anything过程分为以下四个步骤:
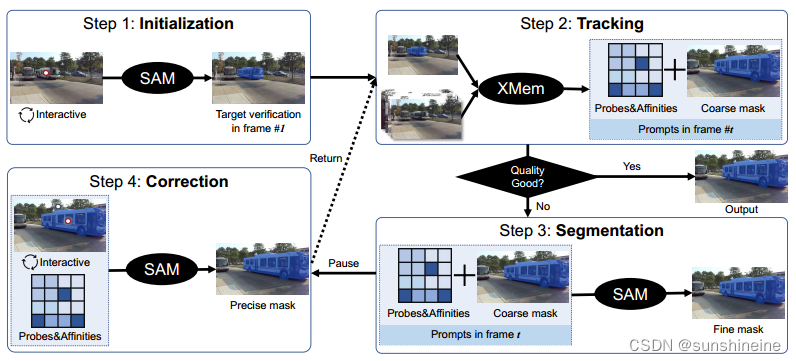
步骤1:使用SAM进行初始化
由于SAM为我们提供了一个使用弱提示(例如,点和边界框)分割感兴趣区域的机会,因此我们使用它来给出目标对象的初始掩码。根据SAM,用户可以通过单击获得感兴趣对象的掩码描述,或者通过多次单击修改对象掩码以获得满意的初始化。
步骤2:使用XMem进行跟踪
给定初始化的掩码,根据时间和空间对应关系,利用XMem对下一帧目标进行掩模预测,大多数情况下可直接输出XMem的预测掩码。当掩码质量不是很好时,我们保存XMem预测和相应的中间参数,即探针和亲和度,并跳转到步骤3。
步骤3:使用SAM进行细化
我们注意到,在VOS模型的推理过程中,保持预测一致和精确的掩模是一个挑战。事实上,随着时间的推移,大多数最先进的VOS模型倾向于在推理过程中进行越来越粗的分割。因此,当XMem预测的掩模质量评价不理想时,我们利用SAM对其进行细化。具体来说,我们将探针和亲和力投影为SAM的点提示,并使用步骤2预测的掩码作为SAM的掩码提示。然后,有了这些提示,SAM就能够生成一个精细的分割掩码。这种改进的掩码也将被添加到XMem的时间对应中,以改进所有后续的对象识别。
步骤4:有人类参与的纠正
经过以上三个步骤,TAM现在可以成功地解决一些常见的挑战并预测分割掩码。然而,我们注意到,在一些极具挑战性的场景中,特别是在处理长视频时,仍然很难准确区分物体。因此,我们建议在推理过程中加入人为校正,这可以带来性能上的质的飞跃,只需要很少的人为努力。具体来说,在跟踪过程中,用户在发现跟踪失败后可以强制停止TAM进程,并通过正负点击来纠正当前帧的掩码。
三、实验
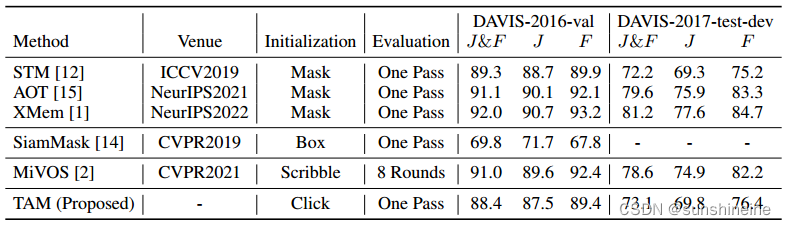
1. 定量结果
为了评估TAM,我们使用了DAVIS-2016的验证集和DAVIS2017的测试开发集执行TAM,结果如下表所示。TAM在两个数据集上分别获得了88.4和73.1的J&F分数。注意,TAM是通过单击初始化的,并在一次传递中求值。值得注意的是,我们发现TAM在处理困难和复杂的场景时表现良好。
2. 定性结果
下图展示了TAM在DAVIS-16和DAVIS-17两个数据集视频序列的定性结果。TAM可以很好地处理多目标分离、目标变形、尺度变化和摄像机运动等问题,这表明TAM在只需点击初始化和一轮推理的情况下,具有优越的跟踪和分割能力。

3. 失败情况
我们还分析了失败的案例,如下图所示。总的来说,我们注意到失败案例通常出现在以下两种情况。1)目前的VOS机型多为短视频设计,更注重维持短期记忆,而不是长期记忆。这导致了长期视频的掩膜收缩或缺乏精细化,如seq (a)所示。本质上,我们的目标是在步骤3中通过SAM的精细化能力来解决这些问题,而其在实际应用中的有效性低于预期。这表明基于多个提示的SAM细化能力在未来还可以进一步提高。另一方面,TAM中的人的参与/交互可以解决这些困难,但过多的交互也会导致效率低下。因此,长期记忆的保存和短暂记忆的更新机制仍然是重要的。2)当目标结构比较复杂时,例如seq(b)中的自行车车轮在ground truth mask中含有许多空腔。我们发现很难通过传播点击来获得细粒度的初始化掩码。因此,粗初始化掩码可能会对后续帧产生副作用,并导致较差的预测。这也启发了我们,SAM仍然在复杂和精确的结构中挣扎。

四、应用
TAM为视频中的灵活跟踪和分割提供了许多可能性。在这里,我们将演示由我们提出的方法启用的几个应用程序。通过这种交互方式,可以轻松实现各种下游任务。
高效的视频注释:TAM能够对视频中感兴趣的区域进行分割,并灵活选择用户想要跟踪的对象。因此,它可以用于视频对象跟踪和视频对象分割等任务的视频注释。另一方面,基于点击的交互使其易于使用,并且注释过程效率高。
长期目标跟踪:长期跟踪的研究越来越受到重视,因为它更接近实际应用。当前的长期目标跟踪任务要求跟踪器具有处理目标消失和再现的能力,但它仍然局限于修剪视频的范围。我们的TAM在实际应用中更先进,可以处理长视频中的镜头变化。
用户友好的视频编辑:跟踪任何模型为我们提供了分割对象的机会,使用TAM提供的对象分割掩码,我们就能够删除或改变给定视频中的任何现有对象。我们结合E2FGVI[11]来评价其应用价值。
用于视频任务的可视化开发工具包:为了方便使用,我们还提供了多个视频任务的可视化界面,例如VOS, VOT,视频绘制等。使用提供的工具包,用户可以将他们的模型应用于真实世界的视频,并立即将结果可视化。
为了证明其有效性,我们将TAM应用于电影《美国队长3:内战》进行了全面的测试。如下图所示,TAM可以在大量镜头变化的视频中精确地呈现多目标跟踪,并可以进一步帮助视频绘制。



















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









