






目录
2.1 Dynamic Conditional Generation
3.2 Mismatch between Train and Test
概述
本节主要讲的内容是:Generation,Attention,Tips for Generation,Pointer Network这四个部分。第一步是 Generation ,具体来讲,是如何产生一个 structured object 。接下来的部分是 Attention 。提及了图片生成句子等有趣技术。进入 Tips for Generation 部分。提到了许多新技术,或者说容易遇到的问题、偏差,并由此介绍了相应的解决方案。最后,稍微提了一下强化学习。
1. Generation
我们可以生成很多东西,比如生成一句话,一段音乐等等,拿生成句子为例,在我们生成好的RNN model里,我们输入开头,模型可以输出一系列的输出,如下图,我们根据输出得到了床,然后把床作为下一个时间点的输入,得到前,依次类推。当然,这是测试时的一种做法,并不是唯一做法。而在训练RNN模型的时候,并不是拿上一时刻的输出当作下一时刻的输入,而是拿真正的句子序列当作输入的。

如果想生成一张图片,我们可以把图片的每个pixel看成一个character,从而组成一个sentence,比如下图中蓝色pixel就表示blue,红色的pixel表示red,…
接下来就可以用language model来生成图片,最初时间步的输入是特殊字符BOS

对于一般的generation,如下图所示,先根据蓝色pixel生成红色pixel,再根据红色pixel生成黄色pixel,再根据黄色pixel生成灰色pixel,…,并没有考虑pixel之间的位置关系。
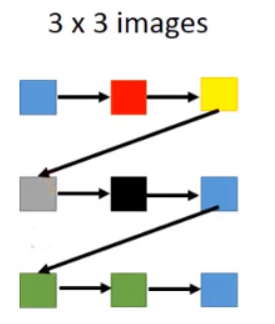
还有另外一个比较理想的生成图像方法,如果考虑了pixel之间的位置关系,如下图所示,黑色pixel由附近的红色和灰色pixel生成。
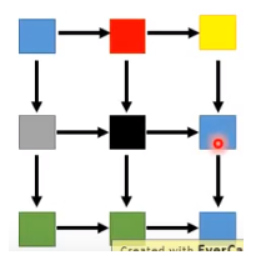
这个东西怎么建模型?
看下图的左上角,该lstm块输入了三组参数,也输出了三组参数,把这些方块叠起来就可以达到右部位置图像的效果


看下完整的图:

1.1 Conditional Generation
有时候,我们不想仅仅是随机生成一些句子,我们希望根据一些情景来生成我们的句子,比如对话系统,根据问题来生成我们的答案,再比如翻译系统,我们要根据给出的句子得到对应的翻译:

如果要对一张图片进行解释,我们先使用一个CNN model将image转化为一个vector(红色方框),先生成了第一个单词"A",在生成第二个单词时,还需要将整个image的vector作为输入,不然RNN可能会忘记image的一些信息。

RNN也可以用来做机器翻译,比如我们想要翻译“机器学习”,就先把这四个字分别输入绿色的RNN里面,最后一个时间节点的输出(红色方框)就包含了整个sentence的information,这个过程称之为Encoder
把encoder的information再作为另外一个rnn的input,再进行output,这个过程称之为Decoder
encoder和decoder是jointly train(联合训练)的,这两者的参数可以是一样的,也可以是不一样的
在做Chat-bot的场景要更加复杂一点,正常的对话是
人说:Hi
机器说:Hi
但是如果有如下场景:
机器说:Hello
人说:Hi
机器说:Hi(这里是错误的,之前已经打过招呼了)
所以需要把前面说过的话要记住,然后考虑到当前的输出。一种方式是使用双层encoder把前面的话的向量表示加入到当前上文表示中,综合考虑:

2. Attention
2.1 Dynamic Conditional Generation
如果需要翻译的文字非常复杂,无法用一个vector来表示,就算可以表示也没办法表示全部的关键信息,这时候如果decoder每次input的都还是同一个vector,就不会得到很好的结果。
在输出machine这个单词的时候,没有必要去考虑输入中的【学习】这个部分,只用考虑【机器】这个部分就好,要把注意力关注到不同的部分。翻译的时候关注的输入不一样(之前的模型都是把整句话的向量丢过去)。因此我们现在先把“机器”作为decoder的第一个输入,这样就可以得到更好的结果。

2.2 Machine Translation
绿色方块为RNN中hidden layer的output;还有一个vector,是可以通过network学出来的;把这两者输入一个match函数,可以得到match分数。
这个match函数可以自己设计,可以有参数,也可以没有参数。

得出的结果再输入softmax函数,并且计算c0,
c0和起始向量表示得到第一个output

然后根据z1再算注意力和output

一直重复这个过程,只到全部翻译完成

2.3 Image Caption Generation
image可以分成多个region,每个region可以用一个vector来表示,计算这些vector和z0之间match的分数,为0.7、0.1…,再进行weighted sum,得到红色方框的结果,再输入RNN,得到Word1,此时hidden layer的输出为z1z。

再计算z1和vector之间的match分数,把分数作为RNN的input,从而得出Word 2

这里是一些具体的例子(attention可视化):

2.4 Memory Network
在Memory上做attention,最早是用在阅读理解上,给机器看一篇文章Document,然后让它回答Answer与文章相关的问题Query。Document可以分为N个句子,每个句子可以表示为一个向量:x1,x2....xn。Query也可以表示为一个向量q,然后用q和Document中的每个句子算match score(相似度)得到a1,a2....an,然后用match score和句向量做加权和。这一系列操作就是算注意力的标准操作,意思就是我们计算了与Query有关的句子,然后把Query和注意力的结果丢到DNN里面,得到Answer

这个模型还有一个更加复杂的版本,就是计算相似度和抽取句向量两部分分开,相当于把句子用不同的参数变成两组不同的向量h和x

注意上面还有一个Hopping,相当于机器算出来注意力之后,再返回去算Match score,相当于不断的思考的过程。
3.Tips for Generation
3.1 Attention的正则化
attention是可以调节的,有时会出现一些bad attention,在产生第二个word(women)时,focus到第二个component,在产生第四个word时,也focus到第二个component上,也是women,多次attent在同一个frame上,就会产生一些很奇怪的结果。

可以使用上述公式的正则化,其中i表示每一个部分(component),t表示每一个迭代。
3.2 Mismatch between Train and Test

在训练阶段,我们在生成第一个A的时候考虑的是开始标签和条件(粉色块),输出第二个B的时候,考虑的是之前的标签A和条件,输出第三个B的时候,考虑的是之前的标签B和条件,整个模型要使得所有生成结果与标签之间的交叉熵的差异越小越好。
在生成阶段,我们不知道具体的标签,所以我们只能把RNN生成的结果接过来。在生成结果的时候应该是生成一个分布,然后从这个分布里面进行sample得到生成结果。

发现两个阶段的不同就是参考不一样,一个是看的参考答案,一个是凭感觉。
这个现象叫:Exposure Bias(曝光偏差)。这两个setting不一致会导致误差累积(error accumulate)。误差累积是因为,你在测试的时候,如果前面单元的输出已经是错的,那么你把这个错的输出作为下一单元的输入,那么理所当然就是“一错再错”,造成错误的累积。
正常的应该这样:
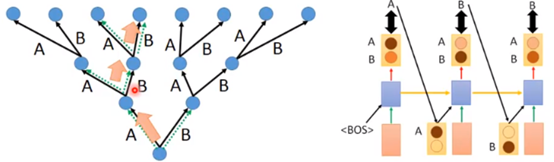
训练出错是这样:

生成的时候出错直接一步错,步步错:GG。

3.2.1 solution
针对上面的这种问题,我们也有如下几种解决方案如:Modifying Training Process、Scheduled Sampling、Beam Search等。下面以Scheduled Sampling为例:
由于使用Modifying Training Process很难train,现在我们就使用Scheduled Sampling,对于到底是model里的ouput,还是reference来作为input,我们可以给一个几率;铜板是正面,就使用model的output,如果是反面,就用reference。右上角的图,纵轴表示from reference的几率,一开始只看reference,reference的几率不断变小,model的几率不断增加。

总结和展望
这次课Conditional Generation by RNN & Attention:
1.从那个聊天知道了条件生成的目的和解决方法,因为需要把前面说过的话要记住,然后考虑到当前的输出,可以使用双层encoder把前面的话的向量表示加入到当前上文表示中,综合考虑。
2.Attention原理差不多知道什么意思了,说到底是一种资源分配模型,在某个特定时刻,你的注意力总是集中在画面中的某个焦点部分,而对其它部分视而不见。
3.在Generation会遇到问题,如Exposure Bias(曝光偏差),可以使用Scheduled Sampling和Beam Search等方法来解决,Scheduled Sampling就是train到后面,不用reference用model来train,可以防止出现没有的数据集;Beam Search就是为每个路径赋予一定的值,但是不可能遍历完,所以选最大的两个;强化学习提了一下,编程实现估计不简单。















 1173
1173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









