







计算机视觉这一学科出现的起初思路就是用电脑程序+摄像头来模拟人类眼睛和大脑。
这一方案的可行性是毋庸置疑的,因为我们每个人都掌握用眼睛看物体,并识别出来所观察物体到底是什么的能力。但是,难点在于到目前为止,我们都不清楚人类的大脑究竟是如何分析理解眼球神经传入的数据的。
a.眼球的分辨率和对焦能力很强
b.眼球不是一帧一帧传给大脑的,而是以感光细胞的为单位的,即时发送的(这点就很牛逼)。
c.不要用像素化思维去套神经传到大脑的信息,人眼都是模拟信号。
d.视网膜看的映像都是倒的,人大脑内部给它转正了。
e.人类的视觉也是2D视觉,大脑用两个眼睛的两张照片合成出3D感觉(不过似乎闭一只眼睛也拥有3D视觉,只能说部分人的代偿能力强,也就是大脑中与生俱来的算法强)
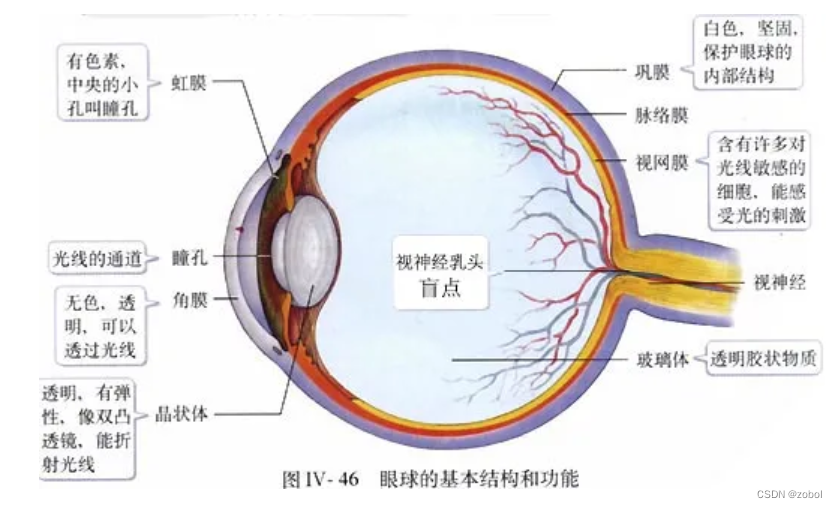
当然也不是一点进展都没有,目前大致的大脑皮层区域是基本搞清楚了。
所以现代计算机视觉的原理跟我们人脑神经的原理是完全不同的。大致上是将其看作成一张像素矩阵,然后利用线性代数,卷积,特征的思路去,寻找0~255的像素二维排列规律。此外还有利用3D相机,获取高度值,从三维点云角度去思考的。当然还有2.5D的深度图思路。
大致上就这三种,从中衍生出了很多解决问题的思路,我们一般初学者,不用就把精力投入到算法的实现原理上,大致能会用就行。一般照着PCL库的demo教程顺一遍就ok。















 4546
4546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









