







Transformer是谷歌在17年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响。 每一位从事NLP研发的同仁都应该透彻搞明白Transformer,它的重要性毫无疑问,尤其是你在看完我这篇文章之后,我相信你的紧迫感会更迫切,我就是这么一位善于制造焦虑的能手。不过这里没打算重点介绍它,想要入门Transformer的可以参考以下三篇文章:一个是Jay Alammar可视化地介绍Transformer的博客文章The Illustrated Transformer ,非常容易理解整个机制,建议先从这篇看起, 这是中文翻译版本;第二篇是 Calvo的博客:Dissecting BERT Part 1: The Encoder ,尽管说是解析Bert,但是因为Bert的Encoder就是Transformer,所以其实它是在解析Transformer,里面举的例子很好;再然后可以进阶一下,参考哈佛大学NLP研究组写的“The Annotated Transformer. ”,代码原理双管齐下,讲得也很清楚。
下面只说跟本文主题有关的内容。
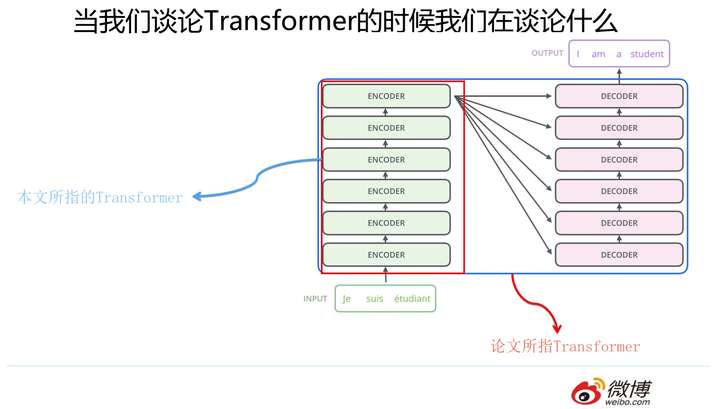
这里要澄清一下,本文所说的Transformer特征抽取器并非原始论文所指。我们知道,“Attention is all you need”论文中说的的Transformer指的是完整的Encoder-Decoder框架,而我这里是从特征提取器角度来说的,你可以简单理解为论文中的Encoder部分。因为Encoder部分目的比较单纯,就是从原始句子中提取特征,而Decoder部分则功能相对比较多,除了特征提取功能外,还包含语言模型功能,以及用attention机制表达的翻译模型功能。所以这里请注意,避免后续理解概念产生混淆。
Transformer的Encoder部分(不是上图一个一个的标为encoder的模块,而是红框内的整体,上图来自The Illustrated Transformer,Jay Alammar把每个Block称为Encoder不太符合常规叫法)是由若干个相同的Transformer Block堆叠成的。 这个Transformer Block其实才是Transformer最关键的地方,核心配方就在这里。那么它长什么样子呢?
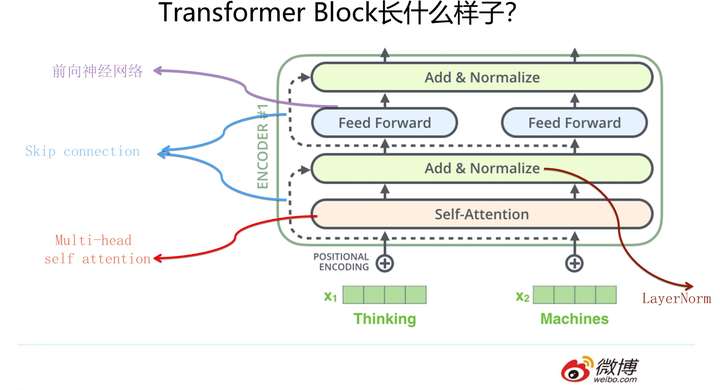
它的照片见上图,看上去是不是很可爱,有点像安卓机器人是吧?这里需要强调一下,尽管Transformer原始论文一直重点在说Self Attention,但是目前来看,能让Transformer效果好的,不仅仅是Self attention,这个Block里所有元素,包括Multi-head self attention,Skip connection,LayerNorm,FF一起在发挥作用。为什么这么说?你看到后面会体会到这一点。
我们针对NLP任务的特点来说下Transformer的对应解决方案。首先,自然语言一般是个不定长的句子,那么这个不定长问题怎么解决呢?Transformer做法跟CNN是类似的,一般设定输入的最大长度,如果句子没那么长,则用Padding填充,这样整个模型输入起码看起来是定长的了。另外,NLP句子中单词之间的相对位置是包含很多信息的,上面提过,RNN因为结构就是线性序列的,所以天然会将位置信息编码进模型;而CNN的卷积层其实也是保留了位置相对信息的,所以什么也不做问题也不大。但是对于Transformer来说,为了能够保留输入句子单词之间的相对位置信息,必须要做点什么。为啥它必须要做点什么呢?因为输入的第一层网络是Muli-head self attention层,我们知道,Self attention会让当前输入单词和句子中任意单词发生关系,然后集成到一个embedding向量里,但是当所有信息到了embedding后,位置信息并没有被编码进去。所以,Transformer不像RNN或CNN,必须明确的在输入端将Positon信息编码,Transformer是用位置函数来进行位置编码的,而Bert等模型则给每个单词一个Position embedding,将单词embedding和单词对应的position embedding加起来形成单词的输入embedding,类似上文讲的ConvS2S的做法。而关于NLP句子中长距离依赖特征的问题,Self attention天然就能解决这个问题,因为在集成信息的时候,当前单词和句子中任意单词都发生了联系,所以一步到位就把这个事情做掉了。不像RNN需要通过隐层节点序列往后传,也不像CNN需要通过增加网络深度来捕获远距离特征,Transformer在这点上明显方案是相对简单直观的。说这些是为了单独介绍下Transformer是怎样解决NLP任务几个关键点的。
Transformer有两个版本:Transformer base和Transformer Big。两者结构其实是一样的,主要区别是包含的Transformer Block数量不同,Transformer base包含12个Block叠加,而Transformer Big则扩张一倍,包含24个Block。无疑Transformer Big在网络深度,参数量以及计算量相对Transformer base翻倍,所以是相对重的一个模型,但是效果也最好。
Transformer的效果相对原生RNN和CNN来说有比较明显的优势,那么是否意味着我们可以放弃RNN和CNN了呢?事实倒也并未如此。我们聪明的科研人员想到了一个巧妙的改造方法,我把它叫做“寄居蟹”策略(就是上文说的“变性”的一种带有海洋文明气息的文雅说法)。什么意思呢?我们知道Transformer Block其实不是只有一个构件,而是由multi-head attention/skip connection/Layer Norm/Feed forward network等几个构件组成的一个小系统,如果我们把RNN或者CNN塞到Transformer Block里会发生什么事情呢?这就是寄居蟹策略的基本思路。
那么怎么把RNN和CNN塞到Transformer Block的肚子里,让它们背上重重的壳,从而能够实现寄居策略呢?
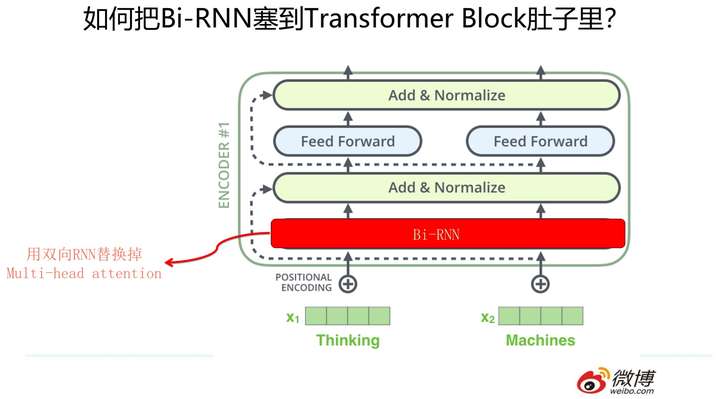
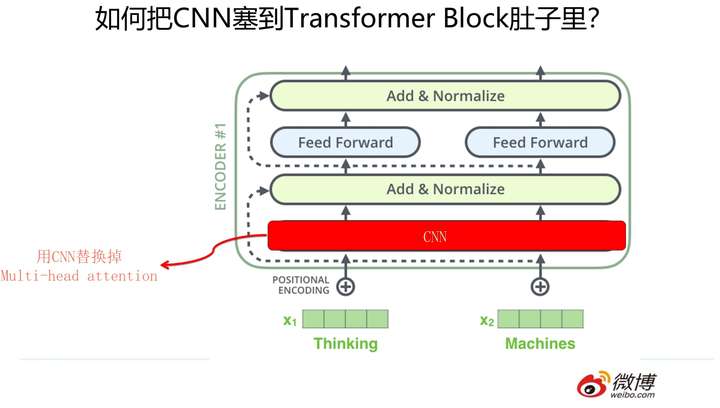
其实很简单,参考上面两张PPT,简而言之,大的方向就是把self attention 模块用双向RNN或者CNN替换掉,Transformer Block的其它构件依然健在。当然这只是说明一个大方向,具体的策略可能有些差异,但是基本思想八九不离十。
那么如果RNN和CNN采取这种寄居策略,效果如何呢?他们还爬的动吗?其实这种改造方法有奇效,能够极大提升RNN和CNN的效果。而且目前来看,RNN或者CNN想要赶上Transformer的效果,可能还真只有这个办法了。

我们看看RNN寄居到Transformer后,效果是如何的。上图展示了对原生RNN不断进行整容手术,逐步加入Transformer的各个构件后的效果。我们从上面的逐步变身过程可以看到,原生RNN的效果在不断稳定提升。但是与土生土长的Transformer相比,性能仍然有差距。
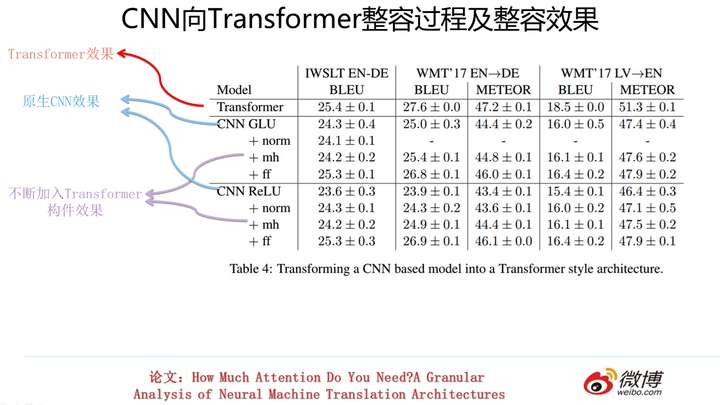
类似的,上图展示了对CNN进行不断改造的过程以及其对应效果。同样的,性能也有不同幅度的提升。但是也与土家Transformer性能存在一些差距。
这说明什么?我个人意见是:这说明Transformer之所以能够效果这么好,不仅仅multi-head attention在发生作用,而是几乎所有构件都在共同发挥作用,是一个小小的系统工程。
但是从上面结果看,变性版本CNN好像距离Transformer真身性能还是比不上,有些数据集合差距甚至还很大,那么是否意味着这条路也未必走的通呢?Lightweight convolution和Dynamic convolutions给人们带来一丝曙光,在论文“Pay Less Attention With LightweightI and Dynamic Convolutions”里提出了上面两种方法,效果方面基本能够和Transformer真身相当。那它做了什么能够达成这一点呢?也是寄居策略。就是用Lightweight convolution和Dynamic convolutions替换掉Transformer中的Multi-head attention模块,其它构件复用了Transformer的东西。和原生CNN的最主要区别是采用了Depth-wise separable CNN以及softmax-normalization等优化的CNN模型。
而这又说明了什么呢?我觉得这说明了一点:RNN和CNN的大的出路在于寄生到Transformer Block里,这个原则没问题,看起来也是他俩的唯一出路。但是,要想效果足够好,在塞进去的RNN和CNN上值得花些功夫,需要一些新型的RNN和CNN模型,以此来配合Transformer的其它构件,共同发挥作用。如果走这条路,那么RNN和CNN翻身的一天也许还会到来。
尽管如此,我觉得RNN这条路仍然不好走,为什么呢,你要记得RNN并行计算能力差这个天生缺陷,即使把它塞到Transformer Block里,别说现在效果还不行,就算哪天真改出了一个效果好的,但是因为它的并行能力,会整体拖慢Transformer的运行效率。所以我综合判断RNN这条路将来也走不太通。















 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









