







函数光滑化杂谈:不可导函数的可导逼近 - 科学空间|Scientific Spaces
关于人体姿态估计是one-hot解析:我一开始不是很理解人体姿态估计到底哪个部分是被看成是onehot形式,其实是在预测的过程,当我们训练完成,形成热图后,我们需要推理阶段预测热图最大位置作为我们最终的坐标点,就是这里是onehot形式,每一个热图是一个关键点的特征概率图谱,我们需要找到最大概率值得位置,比如最大位置是在[65,64],那么经过onehot后将最大位置变成1,其余位置是0.
1.首先了解什么是函数光滑化
不可导函数的可导逼近
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到argmaxargmax等操作),所以没法直接用。
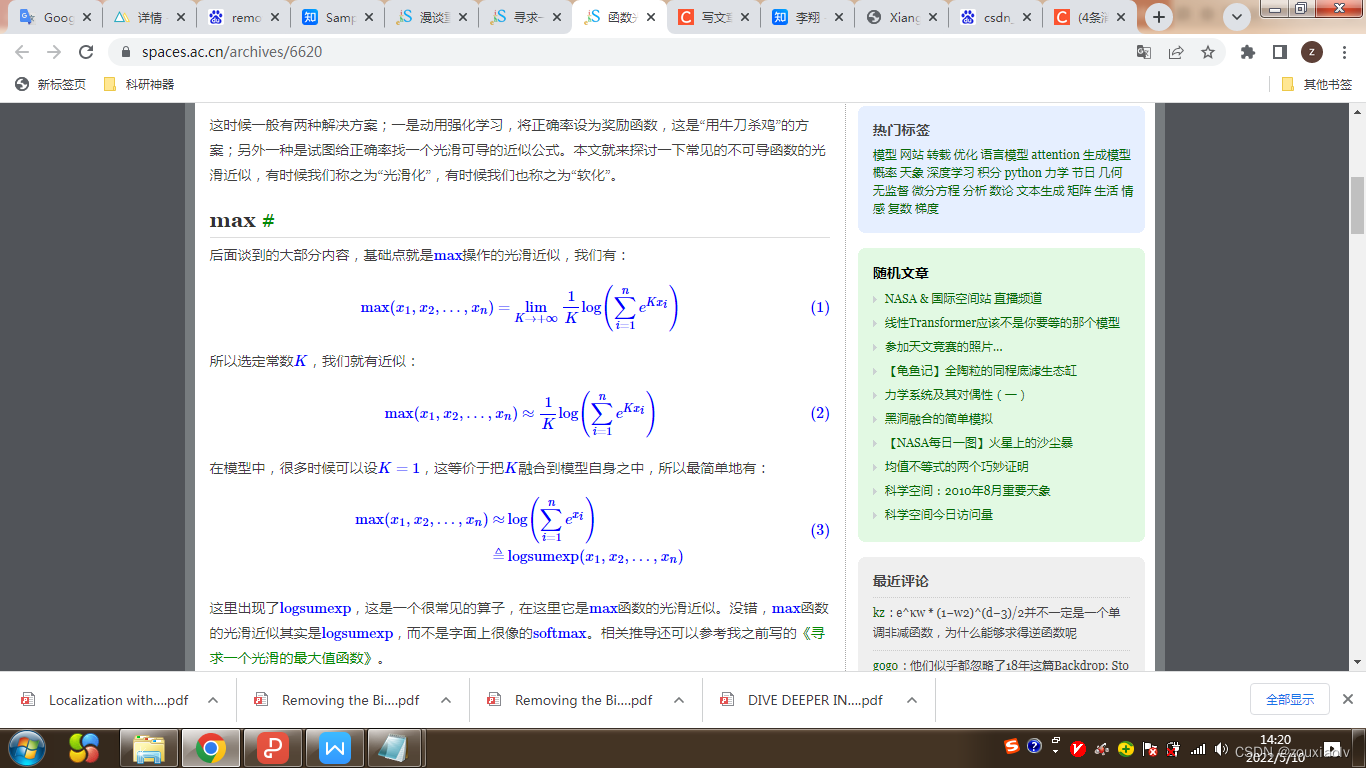
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max#
后面谈到的大部分内容,基础点就是max操作的光滑近似,我们有:
softmax #
刚才说softmax不是max的光滑近似,那它是谁的光滑近似呢?它事实上是onehot(argmax(x))的光滑近似,即先求出最大值所在的位置,然后生成一个等长的向量,最大值那一位置1,其它位置都置0,比如:
[2,1,4,5,3]------->[0,0,0,1,0]我们可以简单地给出一个从logsumexp到softmax的推导过程。考虑向量x=[x1,x2,…,xn],然后考虑
(4)
这样做的目的是让最大处的位置用0 表示,其他位置是负数,那么就会联想到e函数,在0的位置是1,负数位置的值是接近于0,那么就和上面公式(4)表示的一致。
因此,
(5)
将公示(3)代入公式(5)得:
onehot(argmax())=softmax(x)
这样就得到离散的onehot软化成softmax软化的公式,可以将不可到的公式转化成可导的。应用的地方:人体姿态估计中的heatmap在推理过程中经常会用到argmax函数,导致训练与推理是分开的,非端到端的。采用这个就可以将训练与预测联合训练。















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









