







GBDT可以看做是由多棵回归树组成的,所以要理解GBDT,就要先理解回归树。回归树也是为了做预测,只是将特征空间划分成了若干个区域,在每个区域里进行预测,举个简单例子。
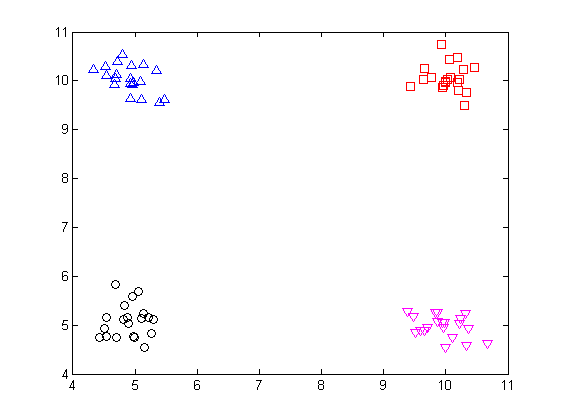
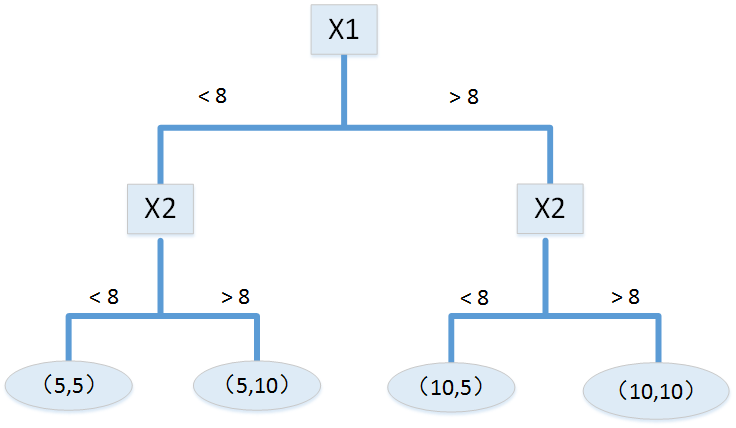
图中的数据有两个特征: x1 、 x2 ,根据这两个特征可以很容易地把数据分为左下角、左上角、右上角、右下角四个区域,这四个区域各有一个中心点(5,5)、(5,10)、(10,10)、(10,5),在对新数据做预测时,该数据落在哪个区域,就把该区域的中心点作为它的预测值。那么如何判断新数据将落在哪个区域呢?这时候“树”就派上用场了。树的根节点以 x1 做划分,小于8的划分到左子树,大于8的划分到右子树,在划分好的左右子树上再以 x2 做进一步的划分,小于8的划分为左叶子,大于8的划分为右叶子,如下图所示:
可以看到,回归树也相当于一个映射,一个函数,即根据输入
x1
、
x2
来求得输出
y
,表达式如下:
其中, Rj 就是一个个的区域,如第一张图中的“左下角”、“左上角”等,如果 x 属于
GBDT
在很多情况下,一棵回归树的预测是不太准确的,我们可以尝试采用多棵回归树去预测,第
m
棵回归树可以表示为如下数学形式:
假设共有 M 棵回归树,那么最终的预测结果为:
表达成递归形式则为:
最完美的GBDT(就训练集而言,不考虑测试集)就是预测值 y 与目标值
GBDT也是从第一棵回归树开始的,不管效果怎么样,先建第一棵回归树,有了第一棵树,就可以通过上面的递归表达式建立第二棵,直到第 M 棵树,那么我们先看一下第二棵树怎么建立。对上面的递归式做个变形,即:
注意到 hM(x) 就是我们要建立的第2 ( M=2 )棵树,已有的是第一棵树,第一棵树一经建成就不变了,相当于一个已知的函数,那么 (t−FM−1(x)) 实际上就是我们在建第 M 棵树时想要得到的预测值。所以在建第二棵树时,我们将目标值
注意到,GBDT的建树过程不是并行的,而是串行的,所以速度较慢,但所有的树一旦建好,用它来预测时是并行的,最终的预测值就是所有树的预测值之和。
拓展
GBDT实际上是由两部分组成:GB 和 DT,DT 意味着每个basic learner (weaker learner)是“树”的形式,而GB则是建树过程中依据的准则。DT 可以不变,而 GB 有多种形式,上述的残差只是其中的一种形式。注意到损失函数可以表示为:
该损失函数关于 F(x) 的导数(梯度)为:
该损失函数在 FM−1(x) 处的导数(梯度)为:
所以在建立第 M 棵树时,新的目标值正好就是损失函数在
举例
本例仅用于说明大意,实际结果肯能不同,比如数据有两个feature:
x1
、
x2
,对应的目标值为
t=sin(x1)+sin(x2)
,如下图所示:
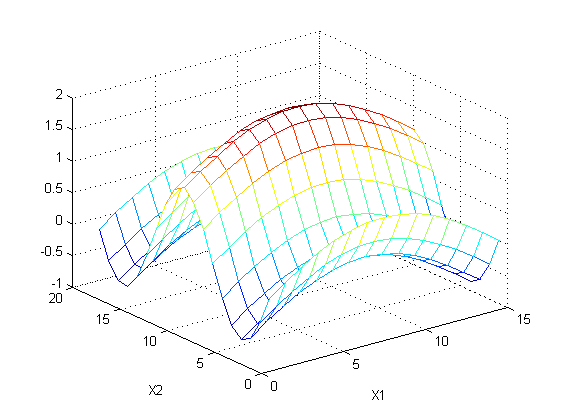
根据feature1可以建立一个回归树,预测结果如下:
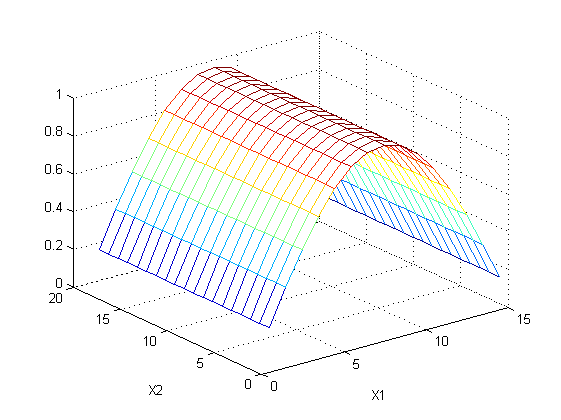
这两张图的差值用于建立第二棵回归树,这次选择了feature2,预测结果如下:
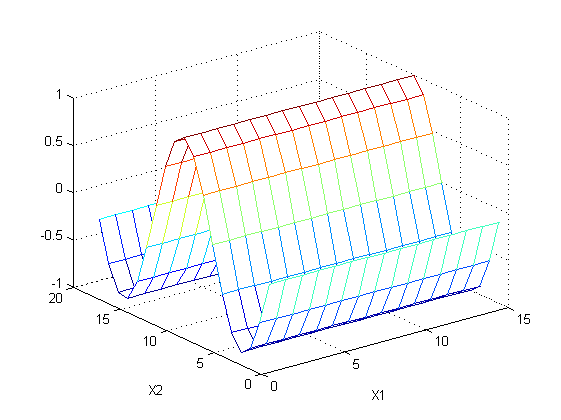
上述两棵树的和就是正确的预测值。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









