









应用机器学习的建议
构建一个机器学习系统,一开始,系统总不能那么尽如人意,那么如何让一个“槽糕”的机器学习系统“好起来”,性能评估、解决方案是我们的着手点。
1 学习算法评估
1.1 决定下一步做什么
在使用机器学习的算法中,选择一条最合适、最正确的道路,为的是改善机器学习系统的性能。改善的方法包含
- 收集过多的信息(在增加数据量意义不大的情况不适用)
- 调整、获取更少(多)的特征(或者多项式特征)
- 调整学习参数,例如增加或减少正则化参数 λ
这些方法同样可以用于机器学习诊断(Diagnostic),这些方法有用却不一定好用。
1.2 评估假设函数
评估函数是为了避免欠拟合与过拟合。
在这里巧用数据,将数据划分为训练集(Train)与测试集(Test),一般比例为7:3。
以线性逻辑回归为例,
Train: minJ(θ)
Test: Jtest(θ)=−1mtest∑i=1mtesty(i)testloghθ(x(i)test)+(1−y(i)test)loghθ(x(i)test)
统计错误分类:
err(hθ(x),y)={10hθ(x)≥0.5,y=0;hθ(x)<0.5,y=1otherwiseTest⋅error=1mtest∑i=1mtesterr(hθ(x),y(i))
1.3 模型选择与训练集、验证集与测试集
训练集、验证集与测试集划分的比例一般采用60% : 20% : 20%
- 模型选择
hθ(x)→θ|mintrainJ(θ)→Jtest(θ) 假设评估:训练集、(交叉)验证集、测试集
3 种误差: Jtrain(θ),JCV(θ),Jtest(θ)
hθ(x)−→−−−−−−minJtrain(θ)θ→JCV(θ)−→−−−−−minJCV(θ)Jtest(θ)
2 偏差还是方差
通过研究机器学习系统中有关偏差与方差的问题,改善系统性能。
2.1 偏差与方差的诊断
记欠拟合与过拟合的偏差 error。
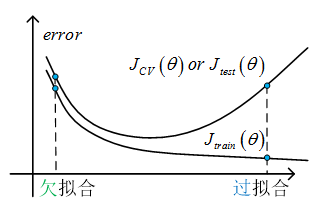
欠拟合
Jtrain(θ)高
JCV(θ)≈Jtrain(θ)过拟合
Jtrain(θ)低
JCV(θ)≫Jtrain(θ)
2.2 正则化与偏差/方差关系
研究正则化参数
λ
与偏差或方差的关系,以选择合适的

2.3 学习曲线
学习曲线可以用来判断一个机器学习算法的偏差、方差的状况,特别注意的是,此处的代价函数中的正则化参数 λ 为 0。如下我们给出了学习曲线的示意图。
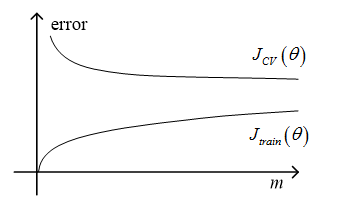
其中,训练集与验证集的代价计算方程为
针对高偏差与高方差的情况,我们给出了如下的示意图。
高偏差的示意图
高方差的示意图
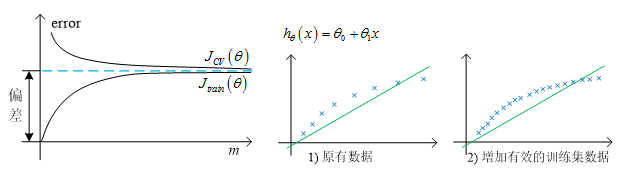
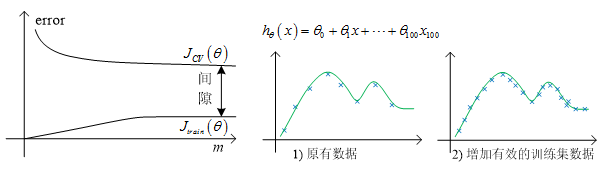
2.4 决定下一步做什么
选择了模型后,分析系统的偏差与方差,如发现高偏差或者高方差的问题,则需要采用诊断或者调试的方法对系统进行改进。
2.4.1 算法调试
调试的方法有 6 种,其中 1-3 种可校正高方差,4-6 种可校正高偏差,其中 λ 为正则化参数。
- 增加训练数据
- 减少特征量
- 增加
λ - 增加特征量
- 增加多项式特征
- 减少 λ
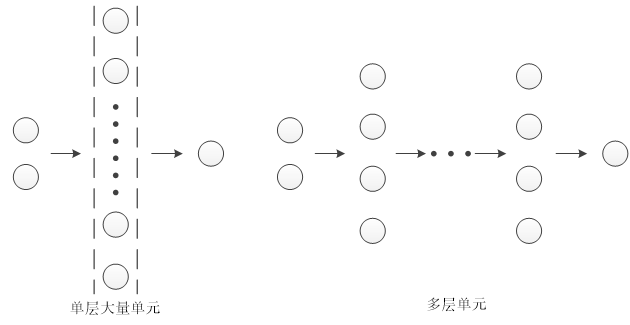
2.4.2 神经网络与过拟合
较小的神经网络:
1) 参数少
2) 可能引发欠拟合
3) 计算量少
大型神经网络:
1) 参数多
2) 可能引发过拟合,可用正则化校正
3) 计算量非常大
机器学习系统设计
优化机器学习系统的第一步,是了解能大大改善系统性能的问题所在。
当一个系统包含多个部分时,如何理解机器学习系统的性能;如何处理有偏斜(异常)的数据。这些将加快系统设计的效率与鲁棒性。
1 构建垃圾邮件分类器
1.1 优先工作
垃圾邮件分类器:监督学习
x= 邮件特征
y=0;1 : 非垃圾;垃圾减少分类错误的方法:
a) 增加数据量:(类似“honeypot” project)
b) 设计基于邮件来源信息的相对复杂的特征
c) 设计基于邮件正文单词拼写或标点的复杂特征
d) 设计复杂的算法用于监测拼写错误但是,要知道这些方法中,哪一种更合适呢?可以用误差分析来评价多种方法哪一个更合适。
1.2 误差分析
1.2.1 一种快速的开发模式
值得推荐的方法,也同样式快速的开发模式:
- 采用一种简单的算法,快速地,让它在交叉验证数据上测试。
- 绘制学习曲线来确认增加数据或者特征是有利的。
- 误差分析,通过针对案例的检查来寻找算法出错的地方,去发现系统在哪类案例上,更容易出错,然后去校正它。
针对方法 ‘3.’ 的例子可以是这样的:
100 error 中包含 12 pharma, 53 steal, 4 fake, 31 other; 53 steal 中包含 5 misspelling, 16 unusual routing, 32 unusual punctuation. 从而先解决 steal,进一步,先处理 steal 中的 unusual punctuation.
1.2.2 数值评估的重要性
量化的评估,能帮助决策,即取哪一种方法改善效果更佳,这是一种直观的评估方法。
例如,在邮件分类中(是否为垃圾邮件),我们可能会得到类似的评估信息:- 采用词干提取:3% error
- 区分大小写:3.2% error
- 不采用词干提取:5% error
一般而言(经验见解),处理系统的问题,不在于算法,而在于数据与特征。
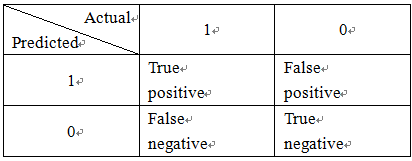
2 处理偏斜类的数据
2.1 偏斜类数据的误差量
针对低错误率(error 小于 1.0%),分类模型的准确度这一指标难以说明结论是否提升。
查准率(Precision)和召回率(Recall)两个指标作为一种新的评估指标,可以用于判断的性能。查准率
召回率
我们可以发现,针对偏斜类数据对预测结果的影响,查准率和召回率越高,预测效果越好,即算法表现越好。尤其要注意的是,一般定义数量少的一类为1,例如在癌症判别中,定义得癌症为1。
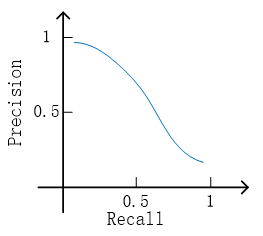
2.2 权衡查准率和召回率
在系统引用中,定义 F1 值使得查准率和召回率相对平衡,其计算方法为
F1=2P⋅RP+R
其中 P 为Precision,即查准率;R 为Recall,即召回率。
值得注意的是,查准率与召回率,或准确度都是基于交叉验证数据集。
一般来讲,查准率高则召回率低,两者呈反比。而调整阈值可能是一种改善查准率与召回率的方法。在逻辑回归中,
{10ifhθ(x)⩾thresholdifhθ(x)<thresholds.t.0⩽hθ(x)⩽1- 增加 threshold(阈值),则提高查准率
- 减少 threshold,则提高召回率
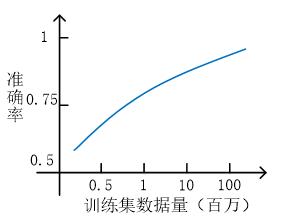
3 使用大数据
3.1 机器学习的数据
在一定条件下,采用某种方法,利用大量的数据进行学习,会得到一种较好的结论或模型。
大数据结果的根本原因(Large data rationale):- 假定(前提)
特征 包含足够的信息,
可以用于预测 y。 - 算法
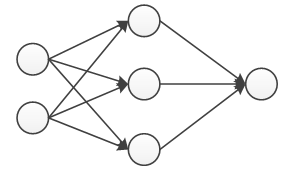
采用多参数的学习算法,相对于多特征;例如使用大量隐藏单元的神经
网络,已保证低偏差。 - 训练
大数据量作为训练集,以避免过拟合,即避免高方差。
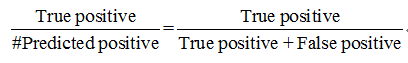
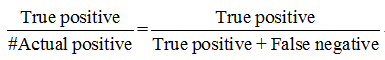















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









