






二、模型量化
之前我们已经完成了模型的剪枝工作,现在继续对这个剪枝后的模型进行量化。
使用的代码还是参考了https://github.com/midasklr/yolov5prune/tree/v6.0,量化的代码在export.py中。选择输出模型的格式为tflite,以便部署在安卓上。TensorFlow Lite 是 TensorFlow 在移动和 IoT 等边缘设备端的解决方案,提供了 Java、Python 和 C++ API 库,可以运行在 Android、iOS 和 Raspberry Pi 等设备上。
量化选择动态量化,动态量化的过程发生在模型训练后,针对模型权重采取量化,之后会在模型预测过程中,再决定是否针对激活值采取量化,因此称作动态量化(在预测时可能发生量化)。关于动态量化的官方指南:
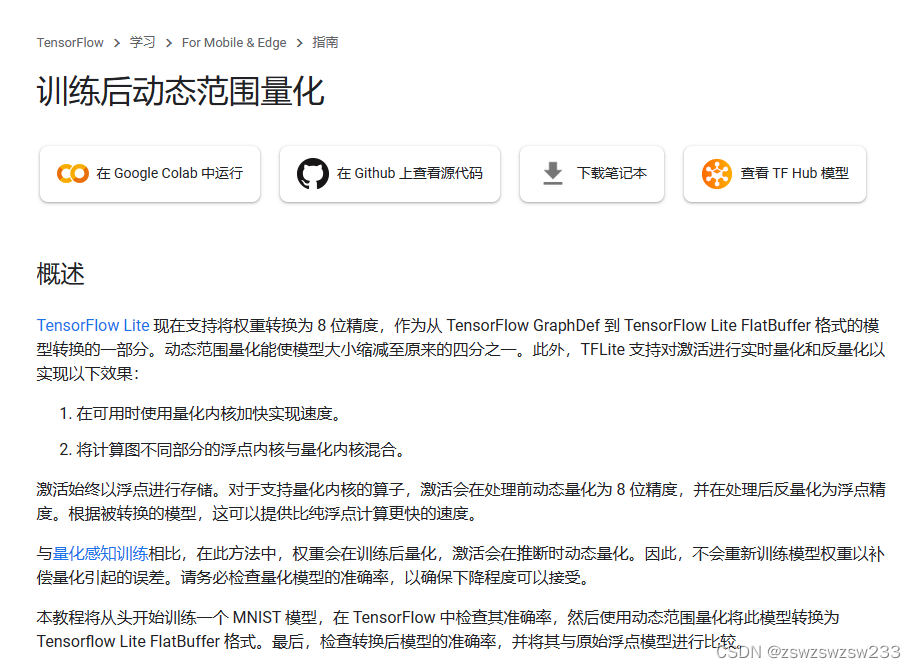
为了实现动态量化,需要注释掉export.py中export_tflite的这一句:
converter.target_spec.supported_types = [tf.float16]export_tflite函数代码如下,int8参数是false,所以if的内容不执行(如果int8为true是全整型量化):
def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
# YOLOv5 TensorFlow Lite export
try:
import tensorflow as tf
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
batch_size, ch, *imgsz = list(im.shape) # BCHW
f = str(file).replace('.pt', '-fp16.tflite')
#读取keras模型
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
#使用TensorFlow Lite内置操作转换模型
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
#指定模型量化类型为int16
# converter.target_spec.supported_types = [tf.float16]
#指定优化器
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
from models.tf import representative_dataset_gen
dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
#指定输入和输出类型是int8
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = False
f = str(file).replace('.pt', '-int8.tflite')
tflite_model = converter.convert()
open(f, "wb").write(tflite_model)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')export.py中的参数设置如下,模型文件是剪枝后的last.pt,为了降低运算量,输入图片尺寸改成了320,--include处default改成tflite。
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default=ROOT / 'Traffic_Lights_Dataset_Domestic/Traffic_Lights_Dataset_Domestic/Traffic_Lights_Dataset_Domestic.yaml', help='dataset.yaml path')
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'last.pt', help='model.pt path(s)')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[320, 320], help='image (h, w)')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
parser.add_argument('--include', nargs='+',
default=['tflite'],
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
opt = parser.parse_args()
print_args(FILE.stem, opt)
return opt运行export.py,报错😵,'NoneType' object has no attribute 'call':
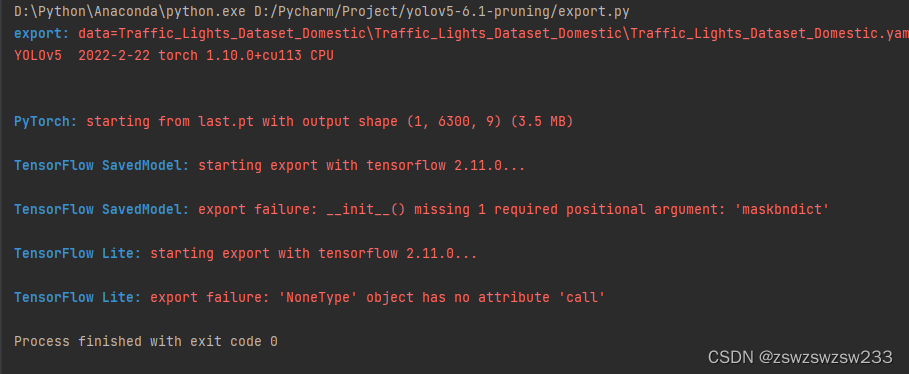
经过多次调试,终于定位到错误的地方export.py->run->export_saved_model->tf_model=TFModel处,TFModel是定义在tf.py中,出错的函数是parse_model。已经大概知道为什么报错了,tf.py中的parse_model作用是通过yaml解析模型,并转换成keras模型(注意和yolo.py中的parse_model函数不同,那里输出的是pytorch模型),在此基础上输出为tflite。这里原代码解析的是原始的模型而不是经过我们剪枝后的模型,所以不能直接使用原来的parse_model函数。经过进一步调试,终于发现了错误的根本原因:
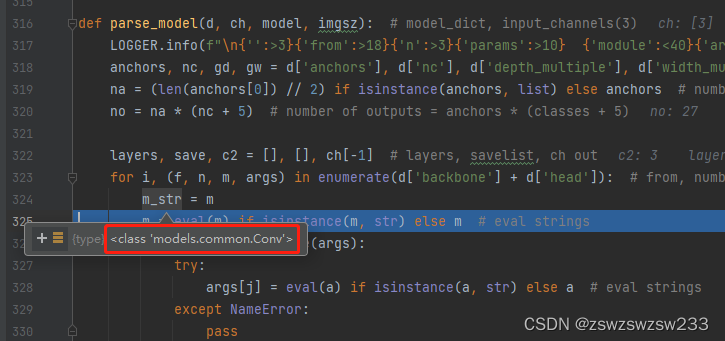
这里m_str正常应该是遍历到的当前模块的名称,应该是一个字符串类型,使用剪枝后的模型量化调试到这里发现m_str格式居然是一个class类。出错在下面这一句,功能是去掉m_str中的'nn.'关键字,加上TF转换成tensorflow模块:
tf_m = eval('TF' + m_str.replace('nn.', ''))因为这里m_str都不是一个字符串,所以replace会出错。之所以m_str格式不对,是因为在剪枝时重新生成yaml时各个模块是定义的类而不是字符串:
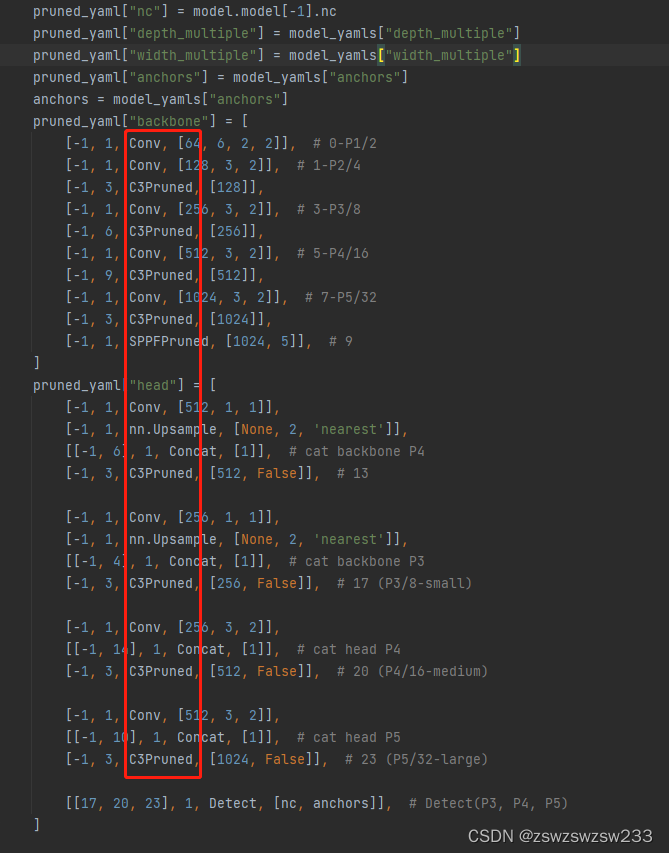
解决方法:
不能使用原来的parse_model函数进行模型解析了,好在剪枝时定义ModelPruned这个类时使用了parse_pruned_model这个函数,可以解析剪枝后的模型。经过一些修改后放在tf.py中:
def parse_pruned_model(maskbndict, d, ch, model, imgsz): # model_dict, input_channels(3)
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
ch = [3]
fromlayer = [] # last module bn layer name
from_to_map = {}
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
named_m_base = "model.{}".format(i)
if m in [Conv]:
named_m_bn = named_m_base + ".bn"
bnc = int(maskbndict[named_m_bn].sum())
c1, c2 = ch[f], bnc
args = [c1, c2, *args[1:]]
layertmp = named_m_bn
if i>0:
from_to_map[layertmp] = fromlayer[f]
fromlayer.append(named_m_bn)
m_str = 'Conv'#手动设置m_str
elif m in [C3Pruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
named_m_cv3_bn = named_m_base + ".cv3.bn"
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = fromlayer[f]
fromlayer.append(named_m_cv3_bn)
cv1in = ch[f]
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
cv3out = int(maskbndict[named_m_cv3_bn].sum())
args = [cv1in, cv1out, cv2out, cv3out, n, args[-1]]
bottle_args = []
chin = [cv1out]
c3fromlayer = [named_m_cv1_bn]
for p in range(n):
named_m_bottle_cv1_bn = named_m_base + ".m.{}.cv1.bn".format(p)
named_m_bottle_cv2_bn = named_m_base + ".m.{}.cv2.bn".format(p)
bottle_cv1in = chin[-1]
bottle_cv1out = int(maskbndict[named_m_bottle_cv1_bn].sum())
bottle_cv2out = int(maskbndict[named_m_bottle_cv2_bn].sum())
chin.append(bottle_cv2out)
bottle_args.append([bottle_cv1in, bottle_cv1out, bottle_cv2out])
from_to_map[named_m_bottle_cv1_bn] = c3fromlayer[p]
from_to_map[named_m_bottle_cv2_bn] = named_m_bottle_cv1_bn
c3fromlayer.append(named_m_bottle_cv2_bn)
args.insert(4, bottle_args)
c2 = cv3out
n = 1
from_to_map[named_m_cv3_bn] = [c3fromlayer[-1], named_m_cv2_bn]
m_str='C3Pruned'#手动设置m_str
elif m in [SPPFPruned]:
named_m_cv1_bn = named_m_base + ".cv1.bn"
named_m_cv2_bn = named_m_base + ".cv2.bn"
cv1in = ch[f]
from_to_map[named_m_cv1_bn] = fromlayer[f]
from_to_map[named_m_cv2_bn] = [named_m_cv1_bn]*4
fromlayer.append(named_m_cv2_bn)
cv1out = int(maskbndict[named_m_cv1_bn].sum())
cv2out = int(maskbndict[named_m_cv2_bn].sum())
args = [cv1in, cv1out, cv2out, *args[1:]]
c2 = cv2out
m_str='SPPFPruned'#手动设置m_str
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
inputtmp = [fromlayer[x] for x in f]
fromlayer.append(inputtmp)
m_str='Concat'#手动设置m_str
elif m is Detect:
from_to_map[named_m_base + ".m.0"] = fromlayer[f[0]]
from_to_map[named_m_base + ".m.1"] = fromlayer[f[1]]
from_to_map[named_m_base + ".m.2"] = fromlayer[f[2]]
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
args.append(imgsz)
m_str='Detect'#手动设置m_str
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
fromtmp = fromlayer[-1]
fromlayer.append(fromtmp)
m_str='Upsample'#手动设置m_str
tf_m = eval('TF' + m_str.replace('nn.', ''))
m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
else tf_m(*args, w=model.model[i]) # module
torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in torch_m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return keras.Sequential(layers), sorted(save), from_to_map由于当前模块m是一个类而不是字符串,所以选择在每种情况下手动设置m_str,以便最后成功转换成tensorflow模型。
接着我们需要在tf.py中把剪枝后的C3Pruned、SPPFPruned和BottleneckPruned模块分别写一个tensorflow版本,命名为TFC3Pruned、TFSPPFPruned和TFBottleneckPruned:
class TFBottleneckPruned(keras.layers.Layer):
# Pruned bottleneck
def __init__(self, cv1in, cv1out, cv2out, shortcut=True, g=1, w=None): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
self.cv1 = TFConv(cv1in, cv1out, 1, 1, w=w.cv1)
self.cv2 = TFConv(cv1out, cv2out, 3, 1, g=g, w=w.cv2)
self.add = shortcut and cv1in == cv2out
def call(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class TFC3Pruned(keras.layers.Layer):
# CSP Bottleneck with 3 convolutions
def __init__(self, cv1in, cv1out, cv2out, cv3out, bottle_args, n=1, shortcut=True, g=1, w=None):
super().__init__()
cv3in = bottle_args[-1][-1]
self.cv1 = TFConv(cv1in, cv1out, 1, 1, w=w.cv1)
self.cv2 = TFConv(cv1in, cv2out, 1, 1, w=w.cv2)
self.cv3 = TFConv(cv3in+cv2out, cv3out, 1, w=w.cv3)
self.m = keras.Sequential([TFBottleneckPruned(*bottle_args[k], shortcut, g, w=w.m[k]) for k in range(n)])
def call(self, inputs):
return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
class TFSPPFPruned(keras.layers.Layer):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, cv1in, cv1out, cv2out, k=5, w=None):
super().__init__()
self.cv1 = TFConv(cv1in, cv1out, 1, 1, w=w.cv1)
self.cv2 = TFConv(cv1out * 4, cv2out, 1, 1, w=w.cv2)
self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
def call(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))TFModel这个类的初始化需要修改,参数需要多一个maskbndict,就是之前存放剪枝mask的字典,同时调用我们修改后的parse_pruned_model函数。
class TFModel:
def __init__(self,maskbndict, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
super().__init__()
self.maskbndict = maskbndict
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
# self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
self.model, self.savelist, self.from_to_map = parse_pruned_model(self.maskbndict, deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
#后面的代码省略回到export.py中,在函数export_saved_model中新增一个参数maskbndict,创建TFModel类时也要新建参数maskbndict。
def export_saved_model(maskbndict, model, im, file, dynamic,
tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
conf_thres=0.25, keras=False, prefix=colorstr('TensorFlow SavedModel:')):
# YOLOv5 TensorFlow SavedModel export
try:
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
from models.tf import TFDetect, TFModel
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
f = str(file).replace('.pt', '_saved_model')
batch_size, ch, *imgsz = list(im.shape) # BCHW
# tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
tf_model = TFModel(maskbndict,cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
#后面的代码省略再回到一开始的run函数,这里调用export_saved_model函数也是一样加入maskbndict。
#前面的代码省略
# TensorFlow Exports
if any((saved_model, pb, tflite, edgetpu, tfjs)):
if int8 or edgetpu: # TFLite --int8 bug https://github.com/ultralytics/yolov5/issues/5707
check_requirements(('flatbuffers==1.12',)) # required before `import tensorflow`
assert not (tflite and tfjs), 'TFLite and TF.js models must be exported separately, please pass only one type.'
# model, f[5] = export_saved_model(model, im, file, dynamic, tf_nms=nms or agnostic_nms or tfjs,
# agnostic_nms=agnostic_nms or tfjs, topk_per_class=topk_per_class,
# topk_all=topk_all, conf_thres=conf_thres, iou_thres=iou_thres) # keras model
model, f[5] = export_saved_model(maskbndict, model, im, file, dynamic, tf_nms=nms or agnostic_nms or tfjs,
agnostic_nms=agnostic_nms or tfjs, topk_per_class=topk_per_class,
topk_all=topk_all, conf_thres=conf_thres, iou_thres=iou_thres) # keras model
#后面的代码省略
这里读入Pytorch模型后加入两句,得到maskbndict:
#前面的代码省略
# Load PyTorch model
device = select_device(device)
assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
model = attempt_load(weights, map_location=device, inplace=True, fuse=True) # load FP32 model
ckpt = torch.load(weights, map_location=device) # load checkpoint
maskbndict = ckpt['model'].maskbndict
#后面的代码省略至此所有地方修改完毕,运行export.py,可以看到模型终于解析成功,并且得到了tflite模型last-fp16.tflite。
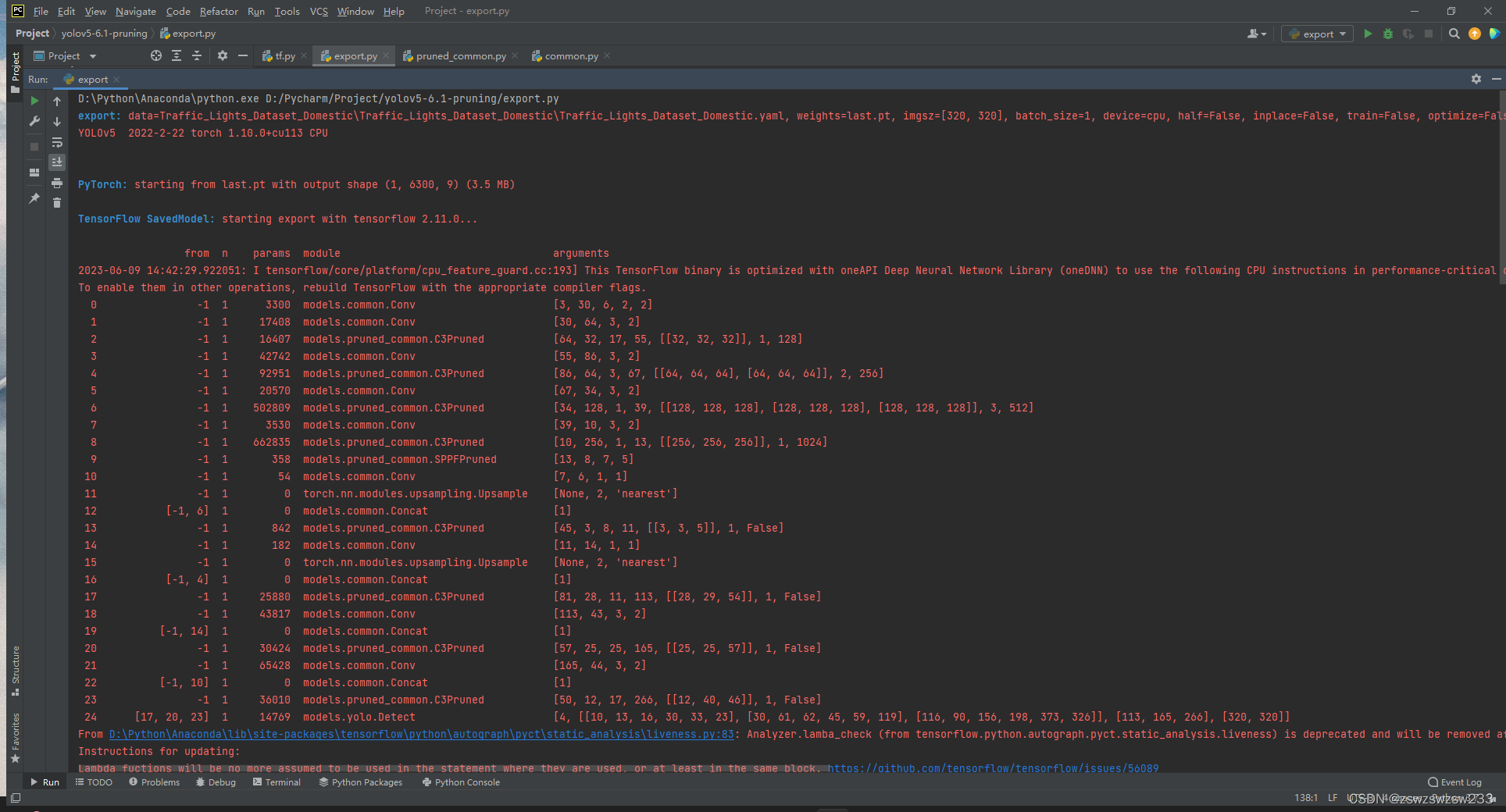
模型参数如下:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(1, 320, 320, 3)] 0 []
tf_conv (TFConv) (1, 160, 160, 30) 3360 ['input_1[0][0]']
tf_conv_1 (TFConv) (1, 80, 80, 64) 17536 ['tf_conv[0][0]']
tfc3_pruned (TFC3Pruned) (1, 80, 80, 55) 16743 ['tf_conv_1[0][0]']
tf_conv_7 (TFConv) (1, 40, 40, 86) 42914 ['tfc3_pruned[0][0]']
tfc3_pruned_1 (TFC3Pruned) (1, 40, 40, 67) 93731 ['tf_conv_7[0][0]']
tf_conv_15 (TFConv) (1, 20, 20, 34) 20638 ['tfc3_pruned_1[0][0]']
tfc3_pruned_2 (TFC3Pruned) (1, 20, 20, 39) 504681 ['tf_conv_15[0][0]']
tf_conv_25 (TFConv) (1, 10, 10, 10) 3550 ['tfc3_pruned_2[0][0]']
tfc3_pruned_3 (TFC3Pruned) (1, 10, 10, 13) 664399 ['tf_conv_25[0][0]']
tfsppf_pruned (TFSPPFPruned) (1, 10, 10, 7) 388 ['tfc3_pruned_3[0][0]']
tf_conv_33 (TFConv) (1, 10, 10, 6) 66 ['tfsppf_pruned[0][0]']
tf_upsample (TFUpsample) (1, 20, 20, 6) 0 ['tf_conv_33[0][0]']
tf_concat (TFConcat) (1, 20, 20, 45) 0 ['tf_upsample[0][0]',
'tfc3_pruned_2[0][0]']
tfc3_pruned_4 (TFC3Pruned) (1, 20, 20, 11) 902 ['tf_concat[0][0]']
tf_conv_39 (TFConv) (1, 20, 20, 14) 210 ['tfc3_pruned_4[0][0]']
tf_upsample_1 (TFUpsample) (1, 40, 40, 14) 0 ['tf_conv_39[0][0]']
tf_concat_1 (TFConcat) (1, 40, 40, 81) 0 ['tf_upsample_1[0][0]',
'tfc3_pruned_1[0][0]']
tfc3_pruned_5 (TFC3Pruned) (1, 40, 40, 113) 26350 ['tf_concat_1[0][0]']
tf_conv_45 (TFConv) (1, 20, 20, 43) 43903 ['tfc3_pruned_5[0][0]']
tf_concat_2 (TFConcat) (1, 20, 20, 57) 0 ['tf_conv_45[0][0]',
'tf_conv_39[0][0]']
tfc3_pruned_6 (TFC3Pruned) (1, 20, 20, 165) 31018 ['tf_concat_2[0][0]']
tf_conv_51 (TFConv) (1, 10, 10, 44) 65516 ['tfc3_pruned_6[0][0]']
tf_concat_3 (TFConcat) (1, 10, 10, 50) 0 ['tf_conv_51[0][0]',
'tf_conv_33[0][0]']
tfc3_pruned_7 (TFC3Pruned) (1, 10, 10, 266) 36772 ['tf_concat_3[0][0]']
tf_detect (TFDetect) ((1, 6300, 9), 14769 ['tfc3_pruned_5[0][0]',
[(1, 3, 1600, 9), 'tfc3_pruned_6[0][0]',
(1, 3, 400, 9), 'tfc3_pruned_7[0][0]']
(1, 3, 100, 9)])
==================================================================================================
Total params: 1,587,446
Trainable params: 0
Non-trainable params: 1,587,446
__________________________________________________________________________________________________最后模型大小为1.65MB:
可以运行detect_pruned.py这个脚本使用量化后模型做推理,这里使用了几张图片实验一下。使用的是CPU推理:
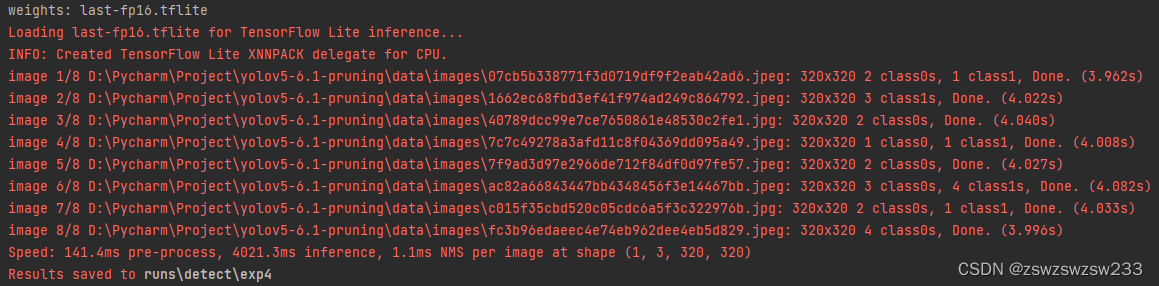
测试效果:








至此,实现了对剪枝后的模型进行动态量化。
参考资料:
1.https://blog.csdn.net/qq_41128383/article/details/107112387
2.https://tensorflow.google.cn/lite/performance/post_training_quant?hl=zh-cn

















 2326
2326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









