







一、函数栈帧
1.认识相关寄存器
eax:通用寄存器,保留临时数据,常用于返回值
ebx:通用寄存器,保留临时数据
ebp:栈底寄存器
esp:栈顶寄存器
eip:指令寄存器,保存当前指令的下一条指令的地址
2.认识相关汇编命令
mov:数据转移指令
push:数据入栈,同时esp栈顶寄存器也要发生改变
pop:数据弹出至指定位置,同时esp栈顶寄存器也要发生改变
sub:减法命令
add:加法命令
call:函数调用,1. 压入返回地址 2. 转入目标函数
jump:通过修改eip,转入目标函数,进行调用
ret:恢复返回地址,将返回地址pop至eip寄存器
3.起步(执行call指令之前)
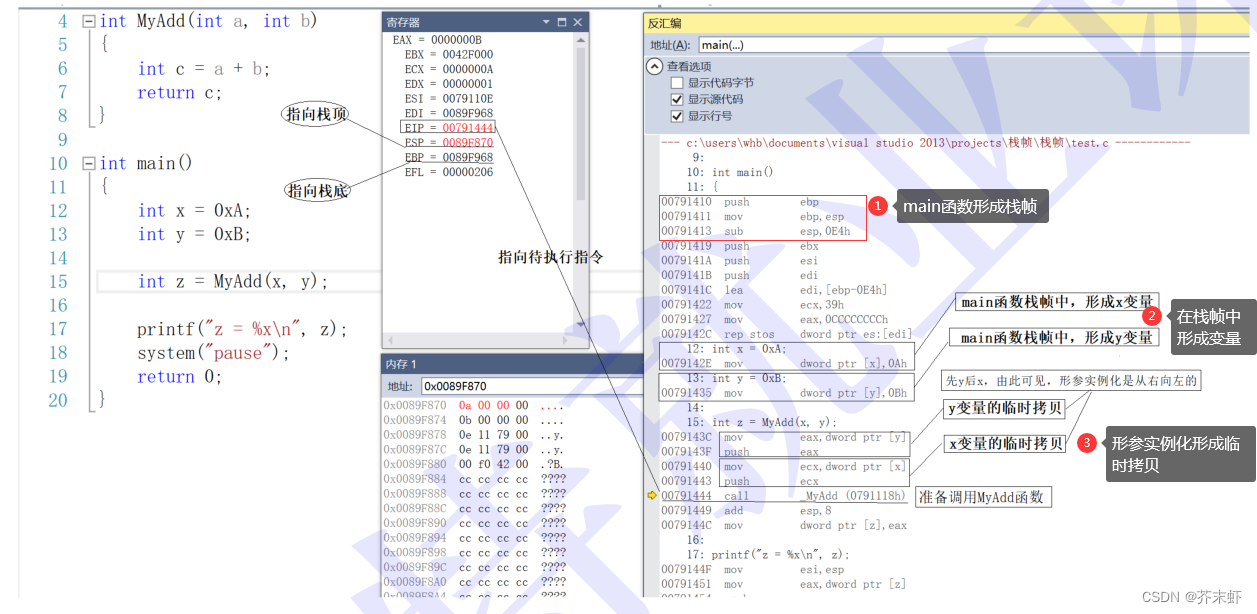

1.局部变量空间的开辟,是在对应函数栈帧内部开辟的。
2.临时变量具有临时性的本质是:栈帧具有临时性
3.函数形参实例化形成临时拷贝是在函数被正式调用(执行call指令)之前。
4.形参实例化(函数形参压栈)的顺序是从右向左的
5.函数形参(实参的临时拷贝)的内存空间是相邻的,也就数说可以通过其中一个形参的地址和形参变量的类型访问其他形参变量(可变参数列表的工作原理)。
6.main函数也要被调用,main函数的调用也会形成栈帧结构。
4.开始调用(执行call指令)


call指令:
1.压入返回地址(函数调用完毕后,需要返回调用处的下一条命令)
2.转入目标函数
5.形成栈帧


1.函数的栈帧空间由esp保存的栈顶指针和ebp保存栈底指针所标定。
2.调用函数会形成函数栈帧,esp寄存器保存的栈顶指针减多少栈区空间就有多大。而这个sub的数值由编译器决定。编译器会在程序的编译阶段通过函数体中定义的变量即其类型确定栈区空间的大小。
6.执行MyAdd函数
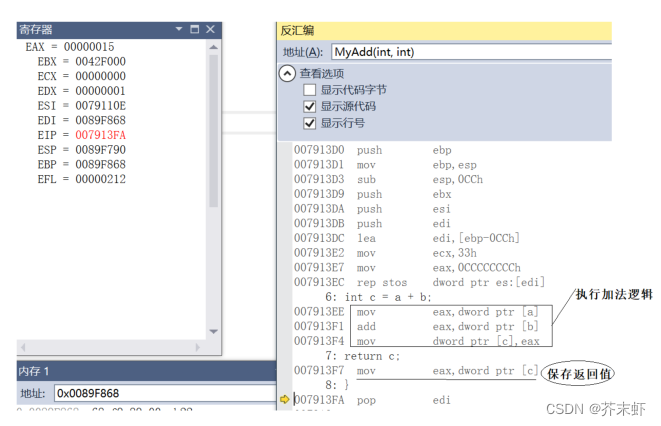
1. 如果函数的返回值是较小的内置类型(可以存放在寄存器中),就会通过寄存器返回给函数调用方。(即使不接受返回值,也会保存在寄存器中)
2. 如果函数的返回值是较大的内置类型或是复杂类型(结构体,C++类),就会存放在函数调用方的栈帧空间中。
7.释放栈帧

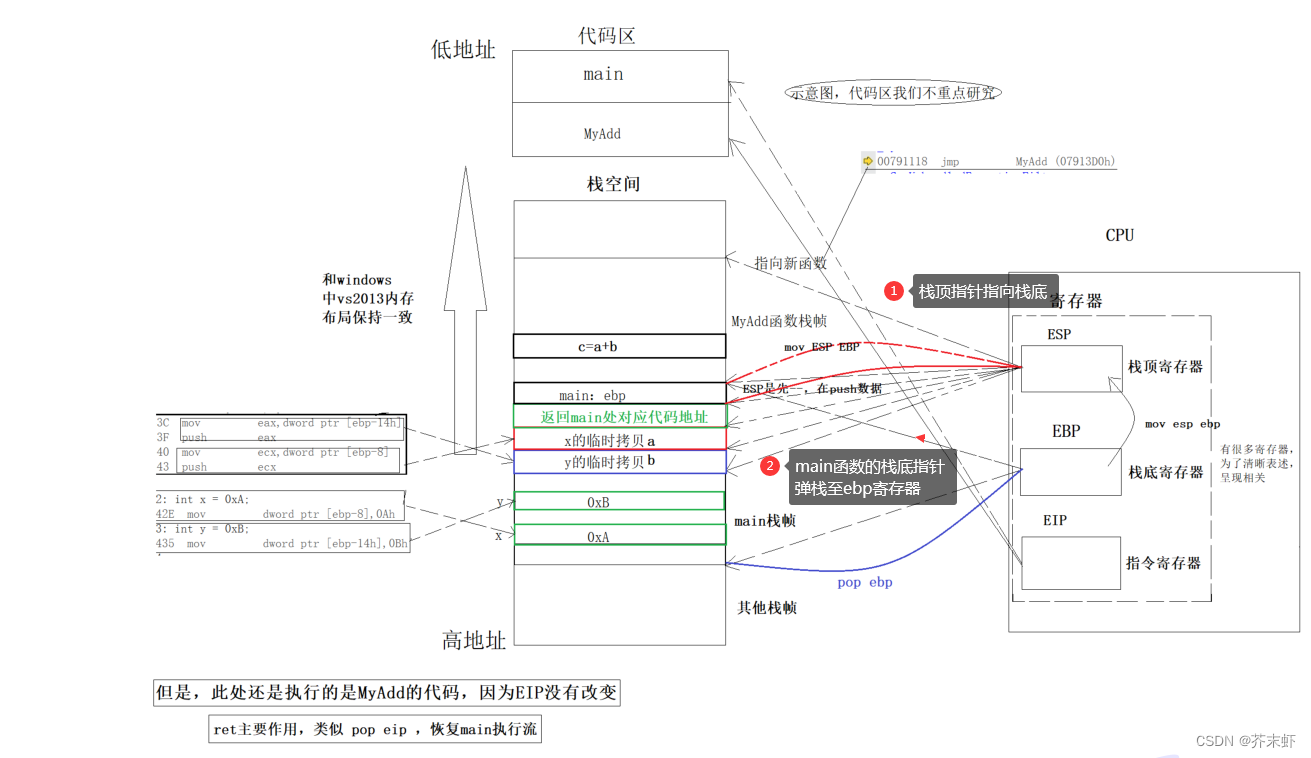
1.释放栈帧空间的本质是,函数的栈帧空间不在栈顶,栈底指针标定的范围内,下一次调用函数可以覆盖对应的空间。
2.释放栈帧空间,仅仅是将该空间设置为无效(使可以被覆盖),而并不会清空其中的数据。
8.释放临时拷贝,彻底释放空间

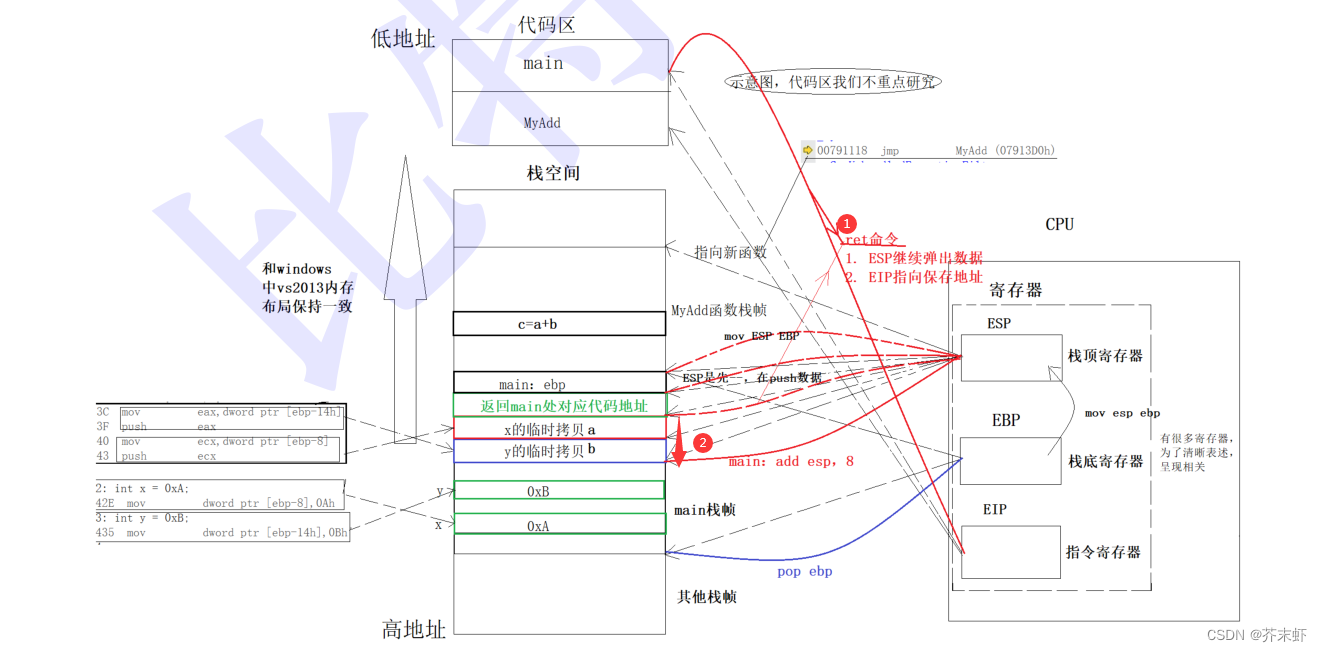
总结:调用函数是有成本的,成本体现在时间和空间上,本质是形成和释放栈帧的成本。
二、可变参数列表
1.使用
#include <stdio.h>
#include <windows.h>
//num:表示传入参数的个数
int FindMax(int num, ...)
{
va_list arg; //定义可以访问可变参数部分的变量,其实是一个char*类型
va_start(arg, num); //使arg指向可变参数部分
int max = va_arg(arg, int); //根据类型,获取可变参数列表中的第一个数据
for (int i = 0; i < num - 1; i++){//获取并比较其他的
int curr = va_arg(arg, int);
if (max < curr){
max = curr;
}
}
va_end(arg); //arg使用完毕,收尾工作。本质就是讲arg指向NULL
return max;
}
int main()
{
int max = FindMax(5, 11, 22, 33, 44, 55);
printf("max = %d\n", max);
system("pause");
return 0;
}初步了解相关宏:
1. va_list typedef char * va_list;
//定义可以访问可变参数部分的变量,其实是一个char*类型
2. va_start(ap,v)
//使ap指针跳过第一个变量v,指向可变参数部分
3. va_arg(ap,t)
//根据类型依次获取可变参数列表中的数据
4. va_end(ap) #define _crt_va_end(ap) ( ap = (va_list)0 )
//将指针设为NULL
2.注意事项
1.可变参数必须从头到尾逐个访问。如果你在访问了几个可变参数之后想半途终止,这是可以的,但是,如果你想一开始就访问参数列表中间的参数,那是不行的。
2.参数列表中至少有一个命名参数。如果连一个命名参数都没有,就无法使用 va_start 。
3.使用可变参数定义函数时,可变参数列表前可以有若干个命名参数(至少一个),但可变参数列表之后不能有命名参数。

3.这些宏是无法直接判断实际存在参数的数量。以上的例子中FindMax函数是通过num变量确定参数数量的。
4.这些宏无法判断每个参数的是类型。参数的类型需要在va_arg宏中指定。
5.如果在 va_arg 中指定了错误的类型,那么其后果是不可预测的。会发生多读取或少读取内存的错误。
6.标准库函数printf();就是使用可变参数的典型代表,当中通过格式控制符(%d,%f,%s)向函数传递参数的类型及数量。第一个参数const char*是唯一存在的命名参数。
3.原理
1.使用可变参数列表定义的函数,最终调用也是函数调用,也要形成栈帧
2.栈帧形成前,临时变量是要先入栈的,根据之前所学,参数之间位置关系是固定的。(函数形参压栈(形参实例化)的顺序是从右向左依次入栈的,形参与形参之间是紧挨着的。)
3.通过查看汇编,我们看到,在可变参数场景下:
>>>实际传入的参数如果是char,short,float,编译器在编译的时候,会自动进行4字节提升(4的最小倍数):char,short向int提升;float向double提升。函数形参是按找4字节提升后的内存大小进行压栈的。
>>>函数内部使用的时候,根据类型提取数据,就要考虑提升之后的值,如果不加考虑,获取数据可能会报错或者结果不正确。
>>>函数内部使用的时候,根据类型提取数据,更多的是通过int或者double来进行
#pragma warning(disable:4996)
#include <stdio.h>
#include <Windows.h>
//FindMax1:不考虑float类型的4字节提升
float FindMax1(int num, ...)
{
va_list arg; //定义可以访问可变参数部分的变量,其实是一个char*类型
va_start(arg, num); //使arg指向可变参数部分
float max = va_arg(arg, float); //根据类型,获取可变参数列表中的第一个数据
for (int i = 0; i < num - 1; i++){//获取并比较其他的
float curr = va_arg(arg, float);
if (max < curr){
max = curr;
}
}
va_end(arg); //arg使用完毕,收尾工作。本质就是讲arg指向NULL
return max;
}
//FindMax2:float类型4字节提升为double类型
double FindMax2(int num, ...)
{
va_list arg; //定义可以访问可变参数部分的变量,其实是一个char*类型
va_start(arg, num); //使arg指向可变参数部分
double max = va_arg(arg, double); //根据类型,获取可变参数列表中的第一个数据
for (int i = 0; i < num - 1; i++){//获取并比较其他的
double curr = va_arg(arg, double);
if (max < curr){
max = curr;
}
}
va_end(arg); //arg使用完毕,收尾工作。本质就是讲arg指向NULL
return max;
}
int main()
{
float a = 3.14f;
float b = 6.28f;
float c = 9.37f;
float d = 2.56f;
float e = 1.1f;
float max1 = FindMax1(5, a, b, c, d, e);
double max2 = FindMax2(5, a, b, c, d, e);
printf("max1 = %f\n", max1);
printf("max2 = %lf\n", max2);
system("pause");
return 0;
}执行结果:

4.相关宏的底层源码:
1. va_list typedef char * va_list;
//定义可以访问可变参数部分的变量,其实是一个char*类型
2. va_start #define _crt_va_start(ap,v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
//使ap指针跳过第一个变量v,指向可变参数部分
>>>宏参ap是va_list指针
>>>宏参v是可变参数列表之前的被命名参数,紧邻可变参数列表。
将上面的宏定义稍加翻译:( ap = (char*)&v + _INTSIZEOF(v) )
3. va_arg #define _crt_va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
//根据类型依次获取可变参数列表中的数据
>>>宏参t是可变参数4字节提升后的类型
1. (ap += _INTSIZEOF(t))
使ap指向当前可变参数的下一个参数
2. ((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
指向当前可变参数,此时ap任然指向下一个参数
3. ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
将指针强转成对应可变参数类型的指针,再解引用访问当前可变参数。
4.由以上解释可知,va_arg宏的工作有两个步骤:
>>>将ap指针指向下一个可变参数
>>>访问当前可变参数
4. va_end #define _crt_va_end(ap) ( ap = (va_list)0 )
//将指针设为NULL
5. ADDRESSOF #define _ADDRESSOF(v) ( &(v) )
//取变量的地址
6. _INTSIZEOF #define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
//按照4字节对齐的原则,确定变量的大小
>>>宏参n传入的是数据类型
1. 将上面的宏定义稍加翻译:( ((sizeof(n) + sizeof(int) - 1) / sizeof(int)) * sizeof(int) )
2. 将sizeof(int)替换为4:( ((sizeof(n) + 3) / 4) * 4 )
当n是4的整数倍时(4,8):
((sizeof(n) + 3) / 4) <==> (sizeof(n) / 4)
当n不是4的整数倍时(1,2,5,6):
((sizeof(n) + 3) / 4) <==> ((sizeof(n) / 4)+1) //完成了4字节提升
3. ( ((sizeof(n) + 3) / 4) * 4 ) <==> w / 4 * 4
从位运算的角度来看实际上就是将w的数据右移两位再左移两位,即将w的后两位清空
4. w / 4 * 4 <==> w & ~3(位运算关闭位,将后两位清零)
最终得到定义式: ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) )
三、函数的递归调用
1.递归算法的本质是:目标问题的子问题,也可以采用相同的算法解决,本质就是分治的思想。
2.递归的两个必要条件:
>>>存在限制条件,当满足限制条件时,递归便不再继续。
>>>每次递归调用之后越来越接近这个限制条件
3.Stack overflow 栈溢出
>>>每一次函数的调用都要在栈区申请分配函数栈帧
>>>函数递归调用时,上一层的递归并未结束任然占用着栈区中的内存空间,再次递归调用时又需要在栈区分配内存。如此循环,栈空间总有被耗干的时候,即出现栈溢出的错误
4.函数递归调用时栈溢出的一般原因:
>>>死递归(没有跳出条件,或者没有逼近跳出条件)
>>>递归调用层次太深
5.递归VS迭代

递归法:
1.递归代码简洁,解题思路简单
1.随着计算量的变大,递归成本越来越高。
2.具体原因是树形结构越来越大,并且里面存在大量的重复计算
3.函数调用是有成本的!递归不一定适合所有场景,尤其是对效率或者资源需求量大的场景。

由上图可以看出,fib(6)和fib(7)虽然只相差一个数字但计算量却相差很大,这种差距会随计算数字的增大也变得越来越大,并且里面存在大量的重复计算。

上图是用递归法求第41,42,43个斐波那契数所得的结果,计算所用的时间,和fib(3)所计算的次数。
迭代法:
1.效率一般很高,迭代法效率高的根本原因是没有多余的函数调用
2.代码一般比较复杂
















 5531
5531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











