







1.文章信息
《Reducing Bus Bunching with Asynchronous Multi-Agent Reinforcement Learning》。本文作者为加拿大蒙特利尔麦吉尔大学的王家伟,孙立君老师等,论文已被IJCAI-2021接收。

2.亮点速览

1.提出异步多智能体强化学习框架优化公交车驻车策略;
2.首次考虑多智能体系统中不确定的事件对智能体策略优化策略的影响,具有推广到其他类似异步控制场景的潜力;
3.基于现实公共交通数据,通过与传统方法及其他前沿强化学习方法对比,验证了模型的优越性。

3.问题介绍

公共交通系统是发展可持续交通出行的关键一环。但在日常运营过程中,由于交通路况、乘客需求等的不确定性,公交车的服务容易变得不稳定——我们往往发现“串车”的现象,即多辆属于同一条线路的公交车几乎同时到达同一个车站(如图1(a)),此时线路上的公交车的车头间距变得不均匀,从而导致公交资源不均,部分乘客的候车时长被迫延长,公交服务质量下降。因此,在公共交通的日常运营中,我们需要实时的公交控制策略去避免“串车”现象。目前,应用最广泛的控制策略是公交驻站控制,如图1(b)所示,公交驻车控制通过给公交车添加额外的停站时间,保证车辆间的车头间距足够均匀,从而保证了可靠且高效率的公交运行。

图 1 发生串车vs避免串车

4.方法简述

传统的控制方法往往不能动态更新模型(静态),不能充分考虑全局信息(孤立),不能高效考虑控制的长远效果(短视),而多智能体强化学习为我们提供了避免这些局限性的新控制方式。但现有的多智能体强化学习框架只关注多智能体的同步决策,而在公共交通中,因为每辆公交车往往在不同时刻到达各个车站,所以车辆进行驻车决策的时间也不尽相同。因此,本文面向公共交通控制,提出了异步的多智能体强化学习框架(Credit Assignment Framework for Asynchronous Control)。本框架采用了经典的actor-critic强化学习框架和ddpg策略优化算法,如下图所示:

图2 利用actor-critc优化公交驻站策略
在该基础框架上,我们提出了基于归纳学习的critic训练框架如下图所示:

图3 基于归纳学习critic的强化学习框架
特别地,我们认为在某辆车(ego bus)连续的两次决策之间,其他车辆进行的决策属于不确定事件,这些事件也在影响系统运行,从而导致critic对ego bus控制策略的评价不够准确,为此,我们分开考虑ego bus和其他bus的决策对系统运行的影响,在上图中。“ego critic”特别学习对ego bus的策略评价,“event critic“学习其他控制事件带来影响。具体来说,我们首先通过构造“事件图”归总这些不确定事件:

图4 事件图示意
其中图的节点表示公交车的到站控制事件。在ego bus的连续两次决策之间,构造其他的事件与ego bus的第一次决策的联系(红色箭头)。最后,我们提出基于“图深度学习”的框架归纳“事件图”的信息,并学习其对系统的影响。我们采用归纳学习的方法训练提出的critic模块,通过其中的“ego critic”实现对ego bus策略的更准确评价,使策略优化更高效率。

图5 通过图卷积神经网络分别归纳上下游控制事件信息

5.实验亮点

我们基于某城市的几条公交线路数据进行模型的验证。我们首先基于一条公交线路训练各个强化学习模型(caac,ddpg,maddpg),然后分别在不同线路进行测试(包括该参与训练的线路和另外三条不参与训练的线路)。在参与训练的线路中,通过可视化不同控制策略下的轨迹图(图中颜色深浅表示车辆载客率大小),我们发现本模型能在全天公交运行过程中保持更稳定有效的控制效果。
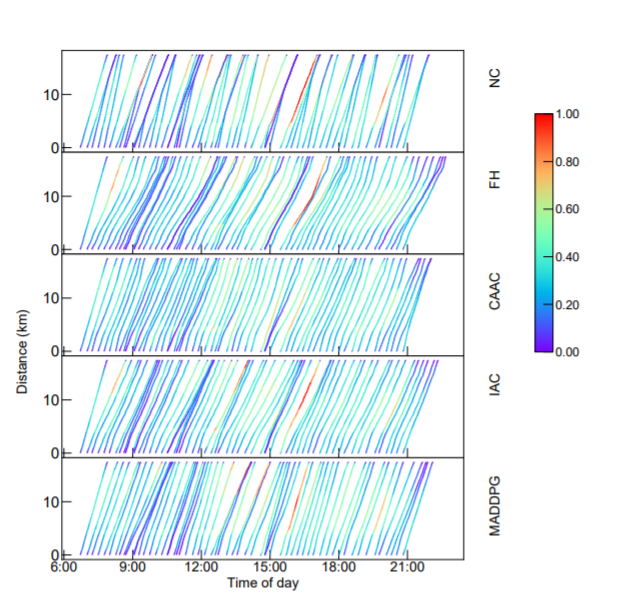
图6 不同控制策略下的公交运行轨迹
此外,我们在未参与训练的线路上进行分析,从而验证强化学习模型的迁移性,如下表所示:

我们考虑控制对公交运行效率和乘客服务质量的改善效果,比较了驻车时间,乘客候车时间,公交旅行时间以及公交载客率的散度等指标,发现本模型在保证系统稳定性上表现更好,但倾向于付出更长的控制时间,相应导致公交旅行时间变长。这是因为我们考虑的奖赏中包括了系统稳定性和控制时长两部分,为的是保证控制策略能以尽可能少的控制时长,有效保证公交系统的稳定。由于系统稳定性的影响并不是仅仅来自一个bus的一次控制策略,所以特别考虑其他控制事件的本模型在该部分优化表现更好,这也侧面说明了本框架考虑多智能体系统中不确定事件的意义。
论文已被IJCAI-2021接收,可点击下方阅读原文快速下载文章!

Attention
如果你和我一样是轨道交通、道路交通、城市规划相关领域的,可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!
















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











