







文章信息

论文题目为《Joint Autoregressive and Hierarchical Priors for Learned Image Compression》,文章来自NIPS2018谷歌团队,是第一篇端到端图像压缩论文《variational image compression with a scale hyperprior》的改进版本,在《variational image compression with a scale hyperprior》中引入了一个超先验来有效地捕获潜在表征中的空间依赖性。而本文受到概率生成模型中自回归先验的成功的启发,该文研究了自回归,分层和组合先验作为替代方案,在图像压缩的情况下权衡了它们的成本和收益。众所周知,自回归模型会带来很大的计算量损失,就压缩性能而言,自回归和分层先验是互补的,并且与所有先前学习的模型相比,自回归和分层先验在潜伏中的概率结构更好。组合的模型产生了最新的速率失真性能,第一个超过了BPG传统压缩的智能压缩算法。

摘要

最近的学习图像压缩模型是基于自编码器,它学习从像素到量化潜在表示的近似可逆映射。这些变换与熵模型相结合,熵模型是潜在表示的先验,可以与标准算术编码算法一起使用来生成压缩的比特流。最近,层次熵模型被引入,作为一种比以前的完全分解先验挖掘更多潜在结构的方法,在保持端到端优化的同时提高了压缩性能。受自回归先验在概率生成模型中成功的启发,我们研究了自回归先验、分层先验和组合先验作为替代方案,并在图像压缩的背景下权衡它们的成本和收益。虽然众所周知,自回归模型可能会导致显著的计算损失,但我们发现,在压缩性能方面,自回归和分层先验是互补的,可以结合起来利用潜在的概率结构,比所有以前的学习模型更好。该组合模型产生了最先进的速率失真性能,并且生成的文件比现有方法更小:比基线分层模型减少15.8%的速率,比JPEG、JPEG2000和BPG分别节省59.8%、35%和8.4%的速率。据我们所知,我们的模型是第一个在PSNR和MS-SSIM失真指标上优于顶级标准图像编解码器(BPG)的基于学习的方法。

贡献

(1)该模型是基于Ballé 2018等人的工作.使用基于噪声的松弛来将梯度下降方法应用于方程式中的损失函数。并引入了层次化的改进熵模型。
(2)本文证明了深度神经网络的标准优化方法足以了解边信息的大小与从更精确的熵模型获得的节省之间的有用平衡。与早期的基于学习的方法相比,生成的压缩模型提供了最新的图像压缩结果。

问题定义

在图像压缩的变换编码方法中,编码器使用参数分析变换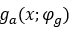 转化为潜在表示y,然后量化形成y ̂。因为y ̂是离散值,它可以使用熵编码技术,如算术编码进行无损压缩,并作为比特序列传输。另一方面,解码器从压缩信号中恢复y ̂,并对其进行参数合成变换
转化为潜在表示y,然后量化形成y ̂。因为y ̂是离散值,它可以使用熵编码技术,如算术编码进行无损压缩,并作为比特序列传输。另一方面,解码器从压缩信号中恢复y ̂,并对其进行参数合成变换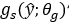 恢复重构图像x ̂。在本文中认为变换g_a和g_s是一般的参数化函数,如人工神经网络(ann),而不是传统压缩方法中的线性变换。然后,参数θ_g和φ_g封装了神经元的权重等。因此问题定义如下:
恢复重构图像x ̂。在本文中认为变换g_a和g_s是一般的参数化函数,如人工神经网络(ann),而不是传统压缩方法中的线性变换。然后,参数θ_g和φ_g封装了神经元的权重等。因此问题定义如下:


方法

5.1 模型概况
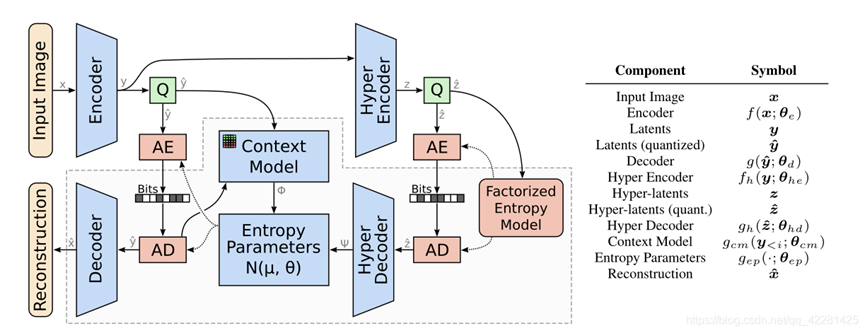
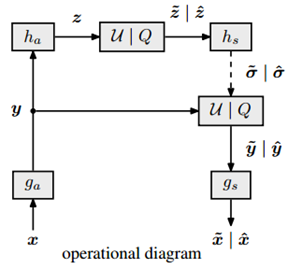
本文提出的网络架构如下图所示,其中左半边是对图像进行编解码的网络模型,右半边对应超先验模型,AE和AD表示算数熵编码器和熵解码器,本文引入了自回归模型来预测隐变量的均值,因此隐变量的均值无需存储传输,大大节约了码率消耗。组合模型共同优化了一个自回归组件,该组件根据其因果上下文(上下文模型)以及超优先级和底层自动编码器来预测隐变量的均值。,然后使用算术编码器(AE)将其压缩为位流,并通过算术解码器(AD)对其进行解压缩。
5.2 编码器
对于编码器来说,和变分自编码器的思想一样,对图片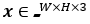 所携带的所有特征信息转为隐层向量
所携带的所有特征信息转为隐层向量 。
。
和变分自编码器不一样的是:如果是变分自编码器,我们只能假设F的C1个通道里每个通道的先验分布为高斯分布;但是本文的作者对隐层向量F的每一个点的先验分布为高斯分布,这是通过后面的超先验网络实现的(但是变分自编码器也能假设每一个点的先验分布为高斯分布,只要你线性层映射的足够多就可以做到)。
变分自编码器需要获得隐层向量中每一个点也好,每一个通道内所有点也好,需要预先假设他们的先验分布(这是为熵编码服务的),但是我们并不知道隐层向量可能的分布,因此在变分自编码器中我们一般假设他们都是标准正态分布,即F~N(0,1);但是对于图像中一些边缘信息,映射到隐层向量中往往离标准正态分布较远(增加了熵编码的成本),因此本文作者提出了一个超先验模型(后面会介绍),和最开始提出的超先验模型不同,该超先验模型不仅得到每一个点的σ,并配合上下文模型预测得到每一个点的均值,预测我们不再假设隐向量的每一个点的均值维0,也就是说超先验模型代替了人为假设隐层向量的分布这一个工作,并且他好像提前知道每一个点可能的分布。
5.3 解码器
对于解码器来说,从隐层向量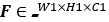 中,输入到
中,输入到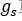 重构出样本
重构出样本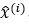 。
。
5.4 超先验网络
经过编码器后得到的隐层向量的元素之间存在显著的空间依赖性。值得注意的是,它们的尺度在空间上是耦合的。对一组目标变量之间的依赖关系进行建模的标准方法是引入潜在变量,假设目标变量是独立的。我们引入了一组额外的随机变量来捕获空间依赖性,并建议将模型扩展如下:
每个隐层向量元素现在被建模为具有自己的标准差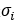 的零均值高斯,其中标准差通过应用参数变换
的零均值高斯,其中标准差通过应用参数变换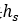 到
到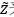 来预测(如上所述,我们将每个高斯密度与标准均匀度卷积)
来预测(如上所述,我们将每个高斯密度与标准均匀度卷积)
5.5 上下文模型
该自回归组件是通过一层的mask convolution卷积层实现的,具体可参考论文《Pixel Recurrent Neural Networks》,通过对卷积核进行Mask操作,掩盖了未解码点的数值,保证了自回归模型预测的当前的像素点参数仅来自于前面已经解码的点,而不取决于未解码点。通过这种Mask 掩膜,遮蔽卷积核下面和右边的权重,这种卷积核与特征图进行卷积的时候,可以可知卷积得到的结果与“未来”的数据无关。自回归模型的问题在于存在严格是时序关系,只能先得到前面的点才能得到当前点的信息,而前面的点也只能依靠更前面的点得到,即表现为在解码的时候,原始的解码方式具有并行性质,而自回归则是串行顺序。

实验

我们通过计算公开可用的柯达图像集的平均率失真(RD)性能来评估我们的广义模型。图2显示了使用峰值信噪比(PSNR)作为图像质量度量的RD曲线。虽然已知PSNR是一个相对较差的感知度量,但它仍然是用于评估图像压缩算法的标准度量,也是用于调整传统编解码器的主要度量。图2左侧的RD图将我们的组合上下文+超先验模型与现有的图像编解码器(标准编解码器和学习模型)进行了比较,并显示该模型优于所有现有的方法,包括BPG,一种基于HEVC帧内编码算法的最先进的编解码器。右边的RD图比较了我们模型的不同版本,并显示了组合模型的性能最好,而上下文模型的性能略差于任何一个层次版本。
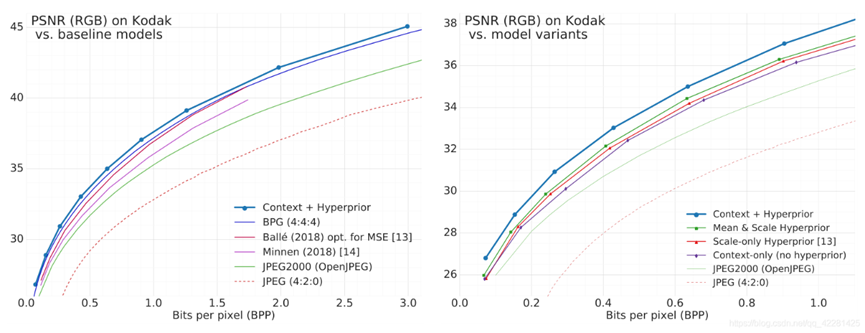
结果在很大程度上取决于训练过程中损失函数中使用的失真度量。当测量PSNR中的失真时(图5,顶部),如果我们的模型针对MS-SSIM进行了优化,则它们的性能都很差。然而,当对平方误差进行优化时,具有因式先验的模型优于现有的传统编解码器,如JPEG,以及其他基于人工神经网络的方法,这些方法已经经过平方误差的训练。请注意,这里没有显示的其他已发表的基于人工神经网络的方法与所显示的方法相比表现不佳,或者没有向我们提供数据。
我们的因式先验模型并不优于BPG (Bellard, 2014), BPG是HEVC(2013)的封装,目标是静止图像压缩。当训练我们的超先验模型的平方误差时,我们得到了接近BPG的性能,在高比特率下比低比特率下有更好的结果,但仍然大大优于所有已发表的基于人工神经网络的方法。
当使用MS-SSIM(图5,底部)测量失真时,JPEG和BPG等传统编解码器最终处于性能排名的低端。这并不奇怪,因为这些方法已经针对平方误差进行了优化(手工选择的约束旨在确保平方误差优化不会违背视觉质量)。据我们所知,MS-SSIM压缩性能的最新技术是Rippel和Bourdev(2017)。
令人惊讶的是,它与我们的因式先验模型相匹配(在高比特率下性能更好,在低比特率下性能稍差),尽管他们的模型在概念上要复杂得多(由于其多尺度架构、GAN损失和上下文自适应熵模型)。超先验模型在所有利率扭曲权衡中增加了进一步的收益,始终超过最先进的水平。


















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











