






导读
本论文于2025年发表于《Transactions on Intelligent Transportation Systems》上。该论文采用半监督学习进行数据增强,使用 Conv-Transformer 模型对客流趋势特征和规模特征分开进行预测,最终结合客流特征以获得新线客流量预测结果。
关键词:Deep learning, new lines, passenger flow prediction, transformer, semi-supervised learning
作者:Yue Mo; Jinlei Zhang; Chengcheng Wang; Xiaopei Hao; Lixing Yang; Ziyou Gao
标题:A Semi-Conv-Transformer Model for Inflow Prediction of Newly Expanding Subway Lines
文献来源:Transactions on Intelligent Transportation Systems, 2025, 10.1109/TITS.2025.3554691
摘要
由于城市轨道交通的快速发展和新线路的不断扩展,准确预测新开通地铁线路的客流量变得愈发重要。既往研究因缺乏历史数据且预测周期较长,在直接预测新线站点客流时存在精度不足的问题。为解决这些挑战,作者提出了一种将进站客流特征分解为趋势特征与规模特征的方法,并基于半监督学习与深度学习神经网络构建了Semi-Conv-Transformer模型用于新线客流预测。这一创新方法将新线进站客流预测划分为三个部分:(1)采用半监督学习进行数据增强以扩充数据集;(2)通过Conv-Transformer深度学习模型分别预测趋势特征与规模特征;(3)融合站点客流的趋势特征与规模特征获得所需进站流量数据。该研究方法在中国南宁新开通的地铁线路上进行了测试,实验结果表明该模型较既有方法具有更优的表现,并实现了更高的预测精度。
问题定义
本节提供预测新扩建地铁站客流量的相关定义。定义1介绍AFC刷卡数据与进站流;定义2提出描述车站客流规模特征的规模量;定义3引入描述车站客流趋势特征的趋势流;定义4说明POI数据及其提取方法;最后给出问题定义。基于这些定义,作者进行了新扩建地铁站的客流量预测。
相关概念
进站流
根据清洗后的AFC刷卡记录中的进站时间,统计不同时段的记录数可得车站进站流。例如,某车站某日6:00-7:00有132条进站记录,则该时段进站流为132。定义
表示所有
个车站在
天内
个时段的进站流,其中元素
表示第
个车站第
天第
时段的进站流。
规模量
规模量用于描述车站的客流规模特征,通过加总单日进站流(即日客流量)计算:
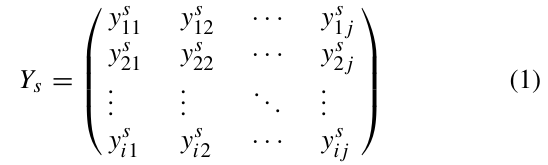

表示所有车站在 天内的日客流量。元素 为第 车站第 天的规模量,反映车站单日客流规模特征。与传统统计方法不同,规模量直接精确估计各站日客流量,而非通过类别均值模糊表示。
趋势流
趋势流描述车站客流趋势特征,由单日各时段进站流除以规模量得出:

表示所有车站在 天内 时段的趋势流。元素 反映第 车站第 天第 时段的客流趋势。与传统聚类方法不同,趋势流精准匹配各站趋势特征,而非归类为单一类别。趋势流量与规模值可同步结合,通过逆向分解过程得到流入量,如下所示:

POI数据
POI(兴趣点)包含名称、编码、位置及类别信息。本文统计车站半径1000米内各类POI数量,定义
为所有车站
的
类POI数据,元素
表示第
车站第
类POI数量。为优化趋势流预测,提出趋势POI概念:

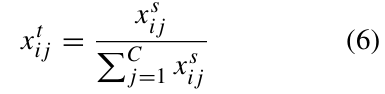
表示趋势POI,元素 为第 车站第 类POI占比,比原始POI更能反映客流趋势特征。
问题说明
目标为构建预测函数 和 ,分别预测趋势流 和规模量 ,最终通过 计算新线车站进站流 。其中 和 分别为新线车站的POI数据及趋势POI数据。
方法论
此处首先说明模型如何针对趋势流和规模量两类预测任务进行调整,随后介绍结合半监督学习与Conv-Transformer的预测框架。整个Semi-Conv-Transformer的图示如下所示:
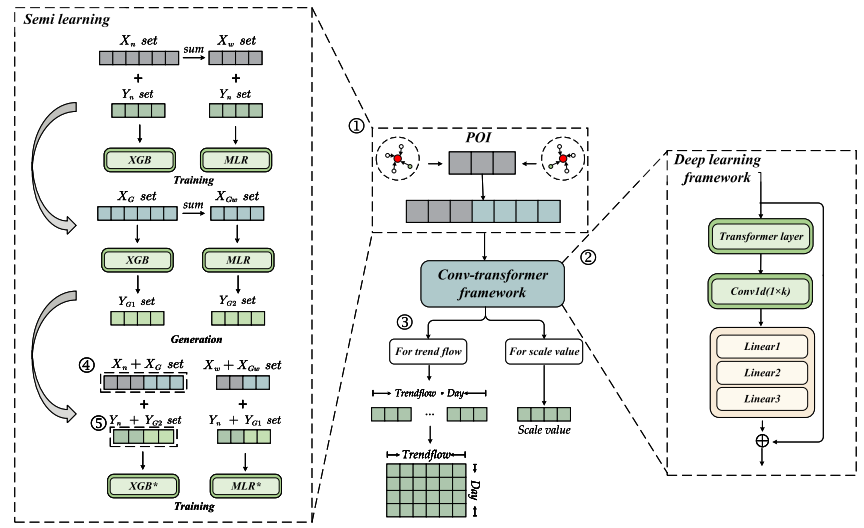
规模量与趋势流预测
Semi-Conv-Transformer模型需分别预测规模量和趋势流。每个车站视为一个样本,符号中 表示第 个车站:
规模量预测:输入为POI一维向量 ,输出为规模量一维向量 。
趋势流预测:输入为趋势POI一维向量 ,输出为趋势流一维向量 ,最终reshape为二维矩阵 。
半监督学习
新线车站因缺乏历史数据易导致过拟合,本文采用半监督学习扩充数据集。整个半监督学习如下图所示:
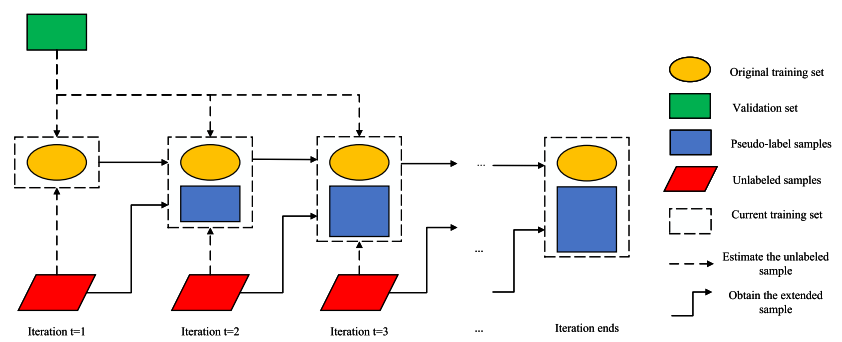
方法分为以下步骤:
固定验证集设计
• 传统方法中验证集随迭代扩展会导致数据失真,本文引入固定验证集保持初始验证比例。
• 训练集随迭代扩展,验证集样本量不变。
迭代流程
• 生成伪标签样本:通过随机数生成器在
取值范围内生成
,输入预训练的XGBoost和MLR模型得到伪标签
、
。
• 训练集扩展:比较扩展前后模型在固定验证集的RMSE,仅当
且
时扩展训练集。
单次迭代细节
• 协同训练:XGBoost(原始POI)与MLR(聚合POI至5类)双视角训练。
• 伪标签生成:
经XGBoost生成
,聚合后
经MLR生成
。
• 模型更新:XGBoost和MLR基于扩展数据训练,通过验证集性能决定是否保留扩展。
Conv-Transformer框架
该深度学习模型整体架构包含N个Transformer层、一个一维卷积层和三个全连接层。其中,Transformer层用于提取POI的全局特征,CNN层负责捕捉POI的局部特征,而全连接层则学习特征提取后的POI数据与客流数据间的复杂关联。最终输出通过残差跳跃连接机制缓解梯度爆炸和梯度消失问题。整个Conv-Transformer框架如下图所示:
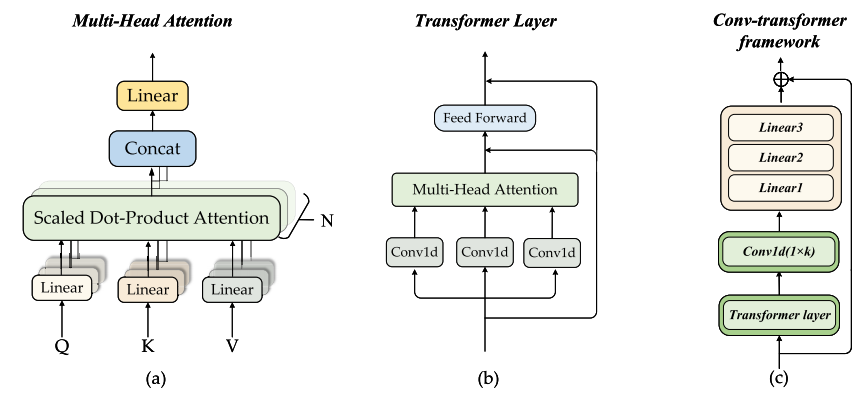
实验结果
作者分别设置了超参数实验,基准模型实验,消融实验以及半监督学习实验。
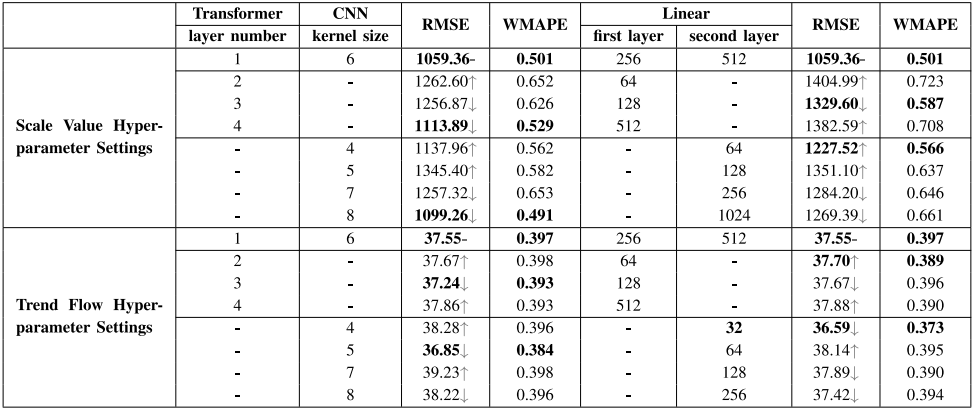
超参数实验
作者通过设置不同的超参数值来探究其对模型的影响。下表展示了趋势流预测模型和尺度值预测模型在不同超参数设置下的性能表现。
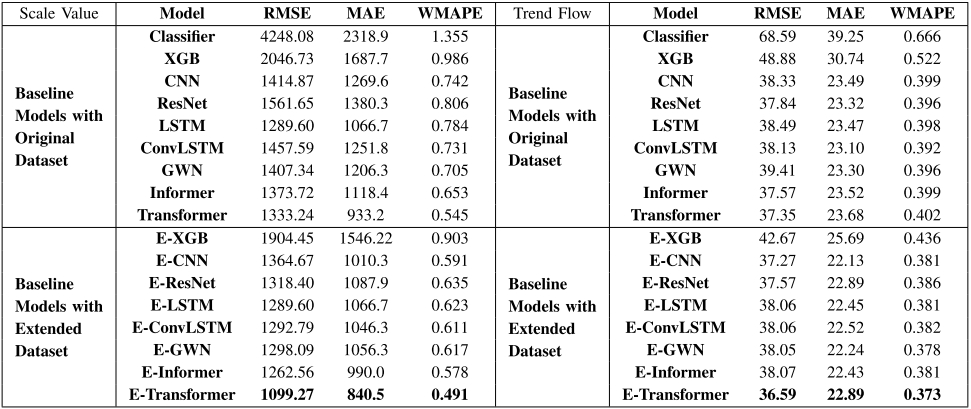
基准模型实验
作者介绍了实验得出的基线模型,模型可分为规模量预测基准模型和趋势流预测基准模型两类。
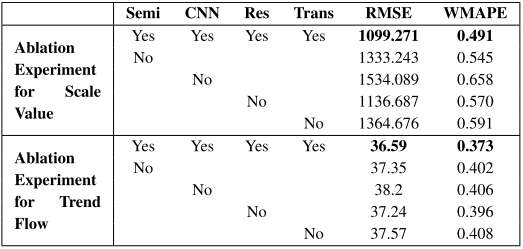
消融实验
为验证趋势流模型和尺度值模型中是否存在冗余部分,作者分别对这两个模型进行了消融实验。
半监督学习实验
半监督学习实验测试了在半监督学习过程中不同半监督学习模型的效果以及不同条件验证率对实验的影响。
半监督学习模型对比
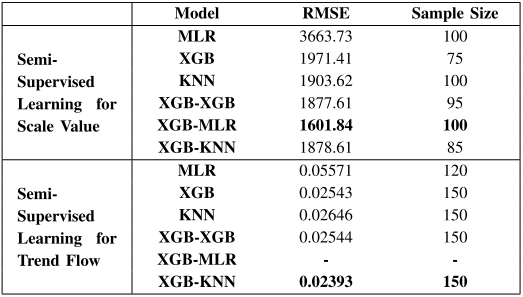
下表展示了半监督学习中不同模型的实验结果,其中MLR代表多元线性回归(Multiple Linear Regression),XGB指代XGBoost算法,而KNN表示K近邻算法(K-Nearest Neighbors)。
固定验证率对比
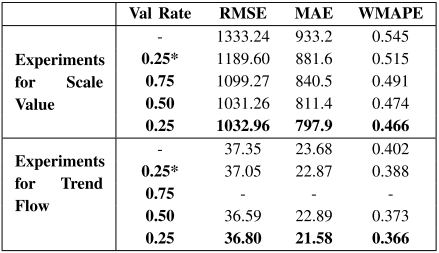
在下表中,验证率对应着不同的验证比例和不同的半监督学习方法。
总结
基于新扩建地铁线路的客流特征,本研究提出趋势流和规模量的概念,并开发了基于这两个特征的Semi-Conv-Transformer预测模型。主要贡献如下:
提出新研究框架:针对新线客流预测的特点,将客流分解为规模特征(日客流量)和趋势特征(时段分布),通过深度学习模型分别预测这两个分量,最终合成进站流预测结果。
设计深度学习模型:开发了结合半监督学习、CNN和Transformer的Semi-Conv-Transformer模型。基准模型实验与消融实验表明,该模型在预测新线客流任务中表现最优,WMAPE较传统方法降低24.1%。
显著提升预测精度:通过融合传统统计方法与深度学习模型,在相同条件下较直接预测方法的MSE降低24.5%,WMAPE降低24.1%,该表现验证了框架的合理性。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











