






快到春节的时候, 发现了一个非常神奇的东西:
加上deepseek的爆火, 作为嵌入人, 怎么能放过这个大佬开源, 向大佬好好学习的机会?
早几个月, 我就想做一个语音助手, 一方便能听懂人类语音, 一方面能接入大语言模型, 一方面能用电机驱动做点小动作.
结果买了个这个:
号称开源, 其实也是拿库封装好了, 就暴露一个接口, 加上我真的对cpp了解太少, 一看到什么week, auto, 加上异步, 脑子就嗡的一下, 放下了…
这下倒好, 大佬直接开源了:
https://github.com/78/xiaozhi-esp32
先看看效果吧.:
小智
怎样, 这个速度, 可能不做技术的没法理解这种感动, 这可是ASR+LLM+TTS啊…这么快?
先说说这几个概念吧, 一段语音, 要AI去理解并作出反应, 首先第一步就是要做ASR(Automatic Speech Recognition), 就是把一段声音中间的语音信息提取出来, 并转为对应的文字.
是不是有点像从一张图片中, 找到人脸, 并做识别, 也是分两步, 第一步, 找到声音中的可能包含的人的声音的部分, 截取出来, 第二步, 把声音截取出来, 做识别, 类似人脸识别中的先detect, 再recognition, 文字识别的ocr也是差不多这样, 第一步, 找到图片中的可能是文字的部分即detect, 抠出来, 第二步, 做recognition.
翻了小智的github, 原来后台部分也是部分开源的,我滴天呐…ASR部分用的阿里的开源funasr, 即fun-asr, github地址:
https://github.com/modelscope/FunASR
这个方案的最大好处就是模型可以部署在本地, 即只要你有个显卡, 就可以用这个模型, 将用户使用ESP上传的声音, 直接转成文字了.
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
简简单单几行, 就把一段mp3中的说话, 转成了文字, 且直接流式输出.
最后这个rich_transcription_postprocess的部分, 就是把转出来的文字做了一个合理化的后处理, 比如去掉一些标点符号, 明显不合理的句子等等.
最终输出的就是我们要送入LLM的文字了.
LLM, 我们可以使用字节的Doubao-1.5-lite-32k, 速度实在太快了…
调用方法几乎傻瓜式…
def access_doubao_api(self, content, model_name="ep-20250205145412-2mzdp"):
sentence = ""
# 记录开始时间
start_time = time.time()
logging.info("----- streaming request -----")
stream = self.ark_client.chat.completions.create(
model=model_name, # your model endpoint ID
messages=[
{"role": "system", "content": "你是大宝,是由字节跳动开发的 AI 人工智能助手,简要回答问题"},
{"role": "user", "content": content},
],
stream=True
)
for chunk in stream:
if not chunk.choices:
continue
response_text_chunk = chunk.choices[0].delta.content
sentence += response_text_chunk
if self.if_sentence(response_text_chunk):
logging.info(sentence)
sentence = ""
# 打印耗时
logging.info(f"LLM耗时: {time.time() - start_time}")
大家可以花30块钱, 试试这个可怕的速度跟模型能力…
30块, 买不了吃亏, 买不了上当…如果是公司账号, 送30万token使用额度…
LLM搞定了, 接下来就要做TTS了, TTS就是文字转语音, 根据小智开源的记录, 有两个可以使用的tts, 一个是火山的, 一个是阿里家的, 著名的弯弯小何, 就是星火的一个音色, 这部分的调用小智已经开源成js了, 大家用自己访问密钥, 直接调用js的接口就行了.
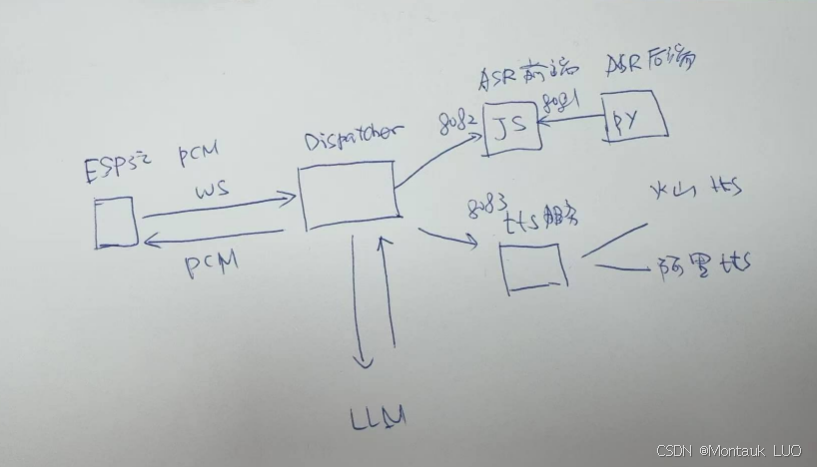
由于大佬把所有东西几乎都开源了, 他们公司自己用的是自己的qwen的大预言模型, 咱们如果要自己搭服务器, 用自己擅长的语言, 实现上面图中的dispatcher部分就好了. 一方面起一个websocket服务器, 让ESP32可以连接, 并上传json文本或者二进制语音数据, 将这些先丢到ASR前端去做识别, 识别完, 返回文本后用, 去拿豆包的接口, 拿到之后, 交给tts服务转为语音, 再把语音返回给ESP32, 做解码播放, 基本流程就是这样.
整个春节, 没咋休息, 除了看了几部恐怖片(异教徒, 危笑), 几步动作片(死侍与金刚狼,毒液3), 就在分析大佬的代码了…祝大家新春快乐! 代码无bug,功能都复用…

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









