







本文是论文《Unsupervised Learning for Fast Probabilistic Diffeomorphic Registration》的阅读笔记。涉及数学的东西太多,没搞懂是怎么做的。
一、微分同胚
现有的基于学习的配准方法通常不能保证配准是微分同胚的,即保留拓扑性的(topology-preserving)。
本文在VoxelMorph模型的基础上加入了微分同胚积分层(diffeomorphic integration layer),以保证无监督的端到端的学习是微分同胚的。微分同胚是可微和可逆的,因此保留了拓扑性。形变场是通过下述常微分方程(OED)来定义的:
∂
ϕ
(
t
)
∂
t
=
v
(
ϕ
(
t
)
)
\frac{\partial \phi^{(t)}}{\partial t}=\boldsymbol{v}\left(\phi^{(t)}\right)
∂t∂ϕ(t)=v(ϕ(t))
其中,
ϕ
(
0
)
=
I
d
\phi^{(0)}=Id
ϕ(0)=Id是恒等变换,
t
t
t是时间,用静态速度场(stationary velocity field)
v
v
v对
t
=
[
0
,
1
]
t=[0,1]
t=[0,1]积分得到最终的配准场
ϕ
(
1
)
\phi^{(1)}
ϕ(1)。使用缩放和展平(squaring)来计算积分,静态ODE的积分可以表示为微分同胚的单参数子群,在群论中,
v
v
v是李代数的一员,并且求幂得到
ϕ
(
1
)
\phi^{(1)}
ϕ(1),
ϕ
(
1
)
\phi^{(1)}
ϕ(1)是李群
ϕ
(
1
)
=
exp
(
v
)
\phi^{(1)}=\exp(v)
ϕ(1)=exp(v)的一员。从单参数子群的属性可知,对于任意常量
t
t
t和
t
′
t'
t′,有
exp
(
(
t
+
t
′
)
v
)
=
exp
(
t
v
)
∘
exp
(
t
′
v
)
\exp((t+t')v)=\exp(tv)\circ\exp(t'v)
exp((t+t′)v)=exp(tv)∘exp(t′v),其中
∘
\circ
∘是和李群相关的成分图(composition map)。从
ϕ
(
1
/
2
T
)
=
p
+
v
(
p
)
/
2
T
\phi^{\left(1 / 2^{T}\right)}=\boldsymbol{p}+\boldsymbol{v}(\boldsymbol{p}) / 2^{T}
ϕ(1/2T)=p+v(p)/2T开始,使用重现(recurrence)
ϕ
(
1
/
2
t
−
1
)
=
ϕ
(
1
/
2
t
)
∘
ϕ
(
1
/
2
t
)
\phi^{\left(1 / 2^{t-1}\right)}=\phi^{\left(1 / 2^{t}\right)} \circ \phi^{\left(1 / 2^{t}\right)}
ϕ(1/2t−1)=ϕ(1/2t)∘ϕ(1/2t)来获取
ϕ
(
1
)
=
ϕ
(
1
/
2
)
∘
ϕ
(
1
/
2
)
\phi^{(1)}=\phi^{(1 / 2)} \circ \phi^{(1 / 2)}
ϕ(1)=ϕ(1/2)∘ϕ(1/2),其中
p
p
p是空间位置的映射,选择
T
T
T使得
v
/
2
T
≈
0
v/2^T\approx 0
v/2T≈0。
二、Prob-VoxelMorph
让
x
,
y
x,y
x,y表示3维MR图像,
z
z
z表示转换函数
ϕ
z
\phi_z
ϕz的隐变量,将
z
z
z的先验概率表示为:
p
(
z
)
=
N
(
z
;
0
,
Σ
z
)
p(\boldsymbol{z})=\mathcal{N}\left(\boldsymbol{z} ; \mathbf{0}, \boldsymbol{\Sigma}_{z}\right)
p(z)=N(z;0,Σz)
其中
N
(
z
;
0
,
Σ
z
)
\mathcal{N}\left(\boldsymbol{z} ; \mathbf{0}, \boldsymbol{\Sigma}_{z}\right)
N(z;0,Σz)是多远正态分布,
μ
\mu
μ和
Σ
\Sigma
Σ分别是其均值和方差。
z
z
z可以是形变场的低维嵌入,也可以是形变场本身。在本文中,让
z
z
z表示静态形变场。让
L
=
D
−
A
L=D-A
L=D−A表示定义在体素网格上的邻接图的拉普拉斯,其中
D
D
D是图的度矩阵,
A
A
A是体素邻接矩阵。通过让
Σ
z
−
1
=
Λ
z
=
λ
L
\boldsymbol{\Sigma}_{z}^{-1}=\boldsymbol{\Lambda}_{z}=\lambda \boldsymbol{L}
Σz−1=Λz=λL来保证
z
z
z的空间平滑,其中
Λ
z
\boldsymbol{\Lambda}_{z}
Λz是精密矩阵(precision matrix)。我们让
x
x
x是扭曲图像
y
y
y的噪声观测:
p
(
x
∣
z
;
y
)
=
N
(
x
;
y
∘
ϕ
z
,
σ
2
I
)
p(\boldsymbol{x} \mid \boldsymbol{z} ; \boldsymbol{y})=\mathcal{N}\left(\boldsymbol{x} ; \boldsymbol{y} \circ \boldsymbol{\phi}_{z}, \sigma^{2} \mathbb{I}\right)
p(x∣z;y)=N(x;y∘ϕz,σ2I)
其中
σ
2
\sigma^2
σ2是加性图像的方差。
我们的目标是估计后验配准概率
p
(
z
∣
x
;
y
)
p(z|x;y)
p(z∣x;y),使用变分的方法,引入一个近似后验概率
q
ψ
(
z
∣
x
;
y
)
q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})
qψ(z∣x;y),通过最小化以下KL散度(即变分下界的负)来计算:
min
ψ
K
L
[
q
ψ
(
z
∣
x
;
y
)
∥
p
(
z
∣
x
;
y
)
]
=
min
ψ
E
q
[
log
q
ψ
(
z
∣
x
;
y
)
−
log
p
(
z
∣
x
;
y
)
]
=
min
ψ
E
q
[
log
q
ψ
(
z
∣
x
;
y
)
−
log
p
(
z
,
x
,
y
)
]
+
log
p
(
x
;
y
)
=
min
ψ
K
L
[
q
ψ
(
z
∣
x
;
y
)
∥
p
(
z
)
]
−
E
q
[
log
p
(
x
∣
z
;
y
)
]
\begin{array}{l} \min _{\psi} \mathrm{KL}\left[q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y}) \| p(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})\right] \\ =\min _{\psi} \mathbf{E}_{q}\left[\log q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})-\log p(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})\right] \\ =\min _{\psi} \mathbf{E}_{q}\left[\log q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})-\log p(\boldsymbol{z}, \boldsymbol{x}, \boldsymbol{y})\right]+\log p(\boldsymbol{x} ; \boldsymbol{y}) \\ =\min _{\psi} \mathrm{KL}\left[q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y}) \| p(\boldsymbol{z})\right]-\mathbf{E}_{q}[\log p(\boldsymbol{x} \mid \boldsymbol{z} ; \boldsymbol{y})] \end{array}
minψKL[qψ(z∣x;y)∥p(z∣x;y)]=minψEq[logqψ(z∣x;y)−logp(z∣x;y)]=minψEq[logqψ(z∣x;y)−logp(z,x,y)]+logp(x;y)=minψKL[qψ(z∣x;y)∥p(z)]−Eq[logp(x∣z;y)]
近似后验概率
q
ψ
(
z
∣
x
;
y
)
q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})
qψ(z∣x;y)可以表示为:
q
ψ
(
z
∣
x
;
y
)
=
N
(
z
;
μ
z
∣
x
,
y
,
Σ
z
∣
x
,
y
)
q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})=\mathcal{N}\left(\boldsymbol{z} ; \boldsymbol{\mu}_{z \mid x, y}, \boldsymbol{\Sigma}_{z \mid x, y}\right)
qψ(z∣x;y)=N(z;μz∣x,y,Σz∣x,y)
其中
Σ
z
∣
x
;
y
\Sigma_{z|x;y}
Σz∣x;y是对角矩阵。
使用参数为
ψ
\psi
ψ的卷积神经网络
d
e
f
ψ
(
x
,
y
)
def_\psi(x,y)
defψ(x,y)来估计
μ
z
∣
x
,
y
\mu_{z|x,y}
μz∣x,y和
Σ
z
∣
x
,
y
\Sigma_{z|x,y}
Σz∣x,y,可以通过随机梯度下降的方法优化变分下界来学习参数
ψ
\psi
ψ,给定图像对
{
x
,
y
}
\{x,y\}
{x,y}和样例
z
k
∼
q
ψ
(
z
∣
x
;
y
)
\boldsymbol{z}_{k} \sim q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})
zk∼qψ(z∣x;y),通过以下损失来计算
y
∘
ϕ
z
k
y\circ\phi_{zk}
y∘ϕzk:
L
(
ψ
;
x
,
y
)
=
−
E
q
[
log
p
(
x
∣
z
;
y
)
]
+
K
L
[
q
ψ
(
z
∣
x
;
y
)
∥
p
(
z
)
]
=
1
2
σ
2
K
∑
k
∥
x
−
y
∘
ϕ
z
k
∥
2
+
1
2
[
tr
(
λ
D
Σ
z
∣
x
;
y
−
log
∣
Σ
z
∣
x
;
y
∣
)
+
μ
z
∣
x
,
y
T
Λ
z
μ
z
∣
x
,
y
]
+
c
o
n
s
t
\begin{array}{l} \mathcal{L}(\psi ; \boldsymbol{x}, \boldsymbol{y})=-\mathbf{E}_{q}[\log p(\boldsymbol{x} \mid \boldsymbol{z} ; \boldsymbol{y})]+\mathrm{KL}\left[q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y}) \| p(\boldsymbol{z})\right] \\ =\frac{1}{2 \sigma^{2} K} \sum_{k}\left\|\boldsymbol{x}-\boldsymbol{y} \circ \boldsymbol{\phi}_{z_{k}}\right\|^{2}+\frac{1}{2}\left[\operatorname{tr}\left(\lambda \boldsymbol{D} \boldsymbol{\Sigma}_{z \mid x ; y}-\log \left|\boldsymbol{\Sigma}_{z \mid x ; y}\right|\right)+\boldsymbol{\mu}_{z \mid x, y}^{T} \boldsymbol{\Lambda}_{z} \boldsymbol{\mu}_{z \mid x, y}\right]+\mathrm{const} \end{array}
L(ψ;x,y)=−Eq[logp(x∣z;y)]+KL[qψ(z∣x;y)∥p(z)]=2σ2K1∑k∥∥x−y∘ϕzk∥∥2+21[tr(λDΣz∣x;y−log∣∣Σz∣x;y∣∣)+μz∣x,yTΛzμz∣x,y]+const
其中
K
K
K是样例的个数,在实验中使用
K
=
1
K=1
K=1。上式中第一项可以让配准后的图像
y
∘
ϕ
z
k
y\circ\phi_{zk}
y∘ϕzk和
x
x
x相似,第二项鼓励后现概率接近于先验概率
p
(
z
)
p(z)
p(z)。虽然变分协方差
Σ
z
∣
x
,
y
\Sigma_{z|x,y}
Σz∣x,y是对角矩阵,但是最后一项在空间上平滑了均值:
μ
z
∣
x
,
y
T
Λ
z
μ
z
∣
x
,
y
=
λ
2
∑
∑
j
∈
N
(
I
)
(
μ
[
i
]
−
μ
[
j
]
)
2
\boldsymbol{\mu}_{z \mid x, y}^{T} \boldsymbol{\Lambda}_{z} \boldsymbol{\mu}_{z \mid x, y}=\frac{\lambda}{2} \sum \sum_{j \in N(I)}(\boldsymbol{\mu}[i]-\boldsymbol{\mu}[j])^{2}
μz∣x,yTΛzμz∣x,y=2λ∑∑j∈N(I)(μ[i]−μ[j])2,其中
N
(
i
)
N(i)
N(i)是体素
i
i
i的邻居,将
σ
2
\sigma^2
σ2和
λ
\lambda
λ看作是固定的超参数。
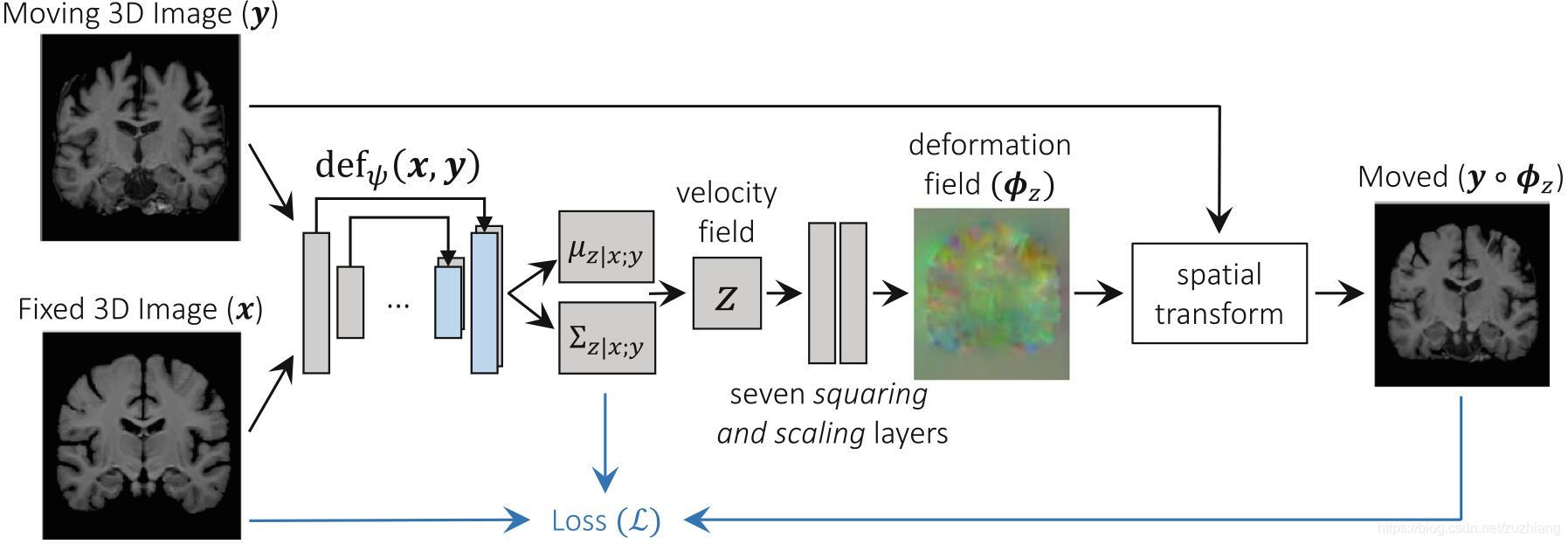
卷积神经网络 d e f ψ ( x , y ) def_\psi(x,y) defψ(x,y)的输入是图像 x , y x,y x,y,输出是 μ z ∣ x , y \mu_{z|x,y} μz∣x,y和 Σ z ∣ x , y \Sigma_{z|x,y} Σz∣x,y。神经网络包括一个卷积层(16通道),4个下采样层(32通道,步长为2)和3个上采样卷积层(32通道),每个卷积层后跟着Leaky ReLU激活函数,并且卷积核大小为 3 × 3 3\times3 3×3。模型的结构如上图所示。
为了使用公式(6)进行无监督的学习,使用了一个通过重参数化技巧来采样一个新的 z k ∼ N ( μ z ∣ x , y , Σ z ∣ x , y ) \boldsymbol{z}_{k} \sim \mathcal{N}\left(\boldsymbol{\mu}_{z \mid x, y}, \boldsymbol{\Sigma}_{z \mid x, y}\right) zk∼N(μz∣x,y,Σz∣x,y)。
文章提出了缩放和展平层来计算 ϕ z k = exp ( z k ) \phi_{z_k}=\exp(z_k) ϕzk=exp(zk),给定两个3D向量场 a a a和 b b b,对于每个体素 p p p,使用线性插值计算 ( a ∘ b ) ( p ) = a ( b ( p ) ) (a\circ b)(p)=a(b(p)) (a∘b)(p)=a(b(p)),即 a a a中一个非整数的体素位置 b ( p ) b(p) b(p)。开始时有 ϕ ( 1 / 2 T ) = p + z k / 2 T \phi^{\left(1 / 2^{T}\right)}=\boldsymbol{p}+\boldsymbol{z}_{k} / 2^{T} ϕ(1/2T)=p+zk/2T,递归的计算 ϕ ( 1 / 2 t + 1 ) = ϕ ( 1 / 2 t ) ∘ ϕ ( 1 / 2 t ) \boldsymbol{\phi}^{\left(1 / 2^{t+1}\right)}=\boldsymbol{\phi}^{\left(1 / 2^{t}\right)} \circ \boldsymbol{\phi}^{\left(1 / 2^{t}\right)} ϕ(1/2t+1)=ϕ(1/2t)∘ϕ(1/2t),使得 ϕ ( 1 ) ≜ ϕ z k = exp ( z k ) \phi^{(1)} \triangleq \phi_{z_{k}}=\exp \left(\boldsymbol{z}_{k}\right) ϕ(1)≜ϕzk=exp(zk),在本文中 T = 7 T=7 T=7。
三、处理过程
总结一下就是,卷积神经网络 d e f ψ ( x , y ) def_\psi(x,y) defψ(x,y)以 x , y x,y x,y为输入,计算 μ z ∣ x , y \mu_{z|x,y} μz∣x,y和 Σ z ∣ x , y \Sigma_{z|x,y} Σz∣x,y,采样一个新的 z k ∼ N ( μ z ∣ x , y , Σ z ∣ x , y ) \boldsymbol{z}_{k} \sim \mathcal{N}\left(\boldsymbol{\mu}_{z \mid x, y}, \boldsymbol{\Sigma}_{z \mid x, y}\right) zk∼N(μz∣x,y,Σz∣x,y),计算微分同胚 ϕ z k \phi_{z_k} ϕzk并将其作用在 y y y上。
给定已经学习好的参数,使用
ϕ
z
^
k
\phi_{\hat{z}_{k}}
ϕz^k来对图像对
(
x
,
y
)
(x,y)
(x,y)进行近似配准,首先使用以下公式获取
z
k
^
\hat{z_k}
zk^:
z
^
k
=
arg
max
z
k
p
(
z
k
∣
x
;
y
)
=
μ
z
∣
x
;
y
\hat{\boldsymbol{z}}_{k}=\arg \max _{z_{k}} p\left(\boldsymbol{z}_{k} \mid \boldsymbol{x} ; \boldsymbol{y}\right)=\boldsymbol{\mu}_{z \mid x ; y}
z^k=argzkmaxp(zk∣x;y)=μz∣x;y
然后使用缩放和展平层计算
ϕ
z
k
^
\phi_{\hat{z_k}}
ϕzk^,我们还得到
Σ
z
∣
x
,
y
\Sigma_{z|x,y}
Σz∣x,y,可以估计每个体素
j
j
j处速度场
z
z
z的不确定性:
H
(
z
[
j
]
)
≈
E
[
−
log
q
ψ
(
z
∣
x
,
y
)
]
=
1
2
log
2
π
Σ
z
∣
x
;
y
[
j
,
j
]
H(\boldsymbol{z}[j]) \approx \mathbf{E}\left[-\log q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x}, \boldsymbol{y})\right]=\frac{1}{2} \log 2 \pi \boldsymbol{\Sigma}_{z \mid x ; y}[j, j]
H(z[j])≈E[−logqψ(z∣x,y)]=21log2πΣz∣x;y[j,j]
我们也估计形变场
ϕ
z
\phi_z
ϕz的不确定性。采样几个表达
z
k
′
∼
q
ψ
(
z
∣
x
;
y
)
\boldsymbol{z}_{k^{\prime}} \sim q_{\psi}(\boldsymbol{z} \mid \boldsymbol{x} ; \boldsymbol{y})
zk′∼qψ(z∣x;y),通过微分同胚层传播它们来计算
ϕ
z
k
′
\phi_{z'_k}
ϕzk′和经验对角协方差(empirical diagonal covariance)
Σ
^
ϕ
z
[
j
,
j
]
\hat{\Sigma}_{\phi_z}[j,j]
Σ^ϕz[j,j],不确定性为
H
(
ϕ
[
j
]
)
≈
1
2
log
2
π
Σ
^
ϕ
z
[
j
,
j
]
H(\phi[j])\approx\frac{1}{2}\log 2\pi\hat{\Sigma}_{\phi_z}[j,j]
H(ϕ[j])≈21log2πΣ^ϕz[j,j]。
四、实验
实验部分进行了基于3D atlas的配准,使用的数据集有ADNI,OASIS,ABIDE,ADHD200,MCIC,PPMI,HABS和Harvard GSP。首先对数据进行标准预处理:将图像重采样成1mm的各向同性体素,并用FreeSurfer进行反射空间正则化和脑部提取(头骨去除),然后将图像裁剪到 160 × 192 × 224 160\times192\times224 160×192×224大小。按照7329,250,250大小分别划分为训练集、验证集和测试集。
将配准得到的形变场作用在分割标签上,并计算其Dice score。为了验证微分同胚性,使用了雅克比矩阵
J
ϕ
(
p
)
=
∇
ϕ
(
p
)
∈
R
3
×
3
J_\phi(p)=\nabla\phi(p)\in R^{3\times3}
Jϕ(p)=∇ϕ(p)∈R3×3,雅克比矩阵可以捕获形变场
ϕ
\phi
ϕ在体素
p
p
p处的局部特性。只有在满足
∣
J
ϕ
(
p
)
∣
>
0
|J_\phi(p)|>0
∣Jϕ(p)∣>0的位置,局部形变才是微分同胚的,即可逆和方位保持(orientation-preserving)的。
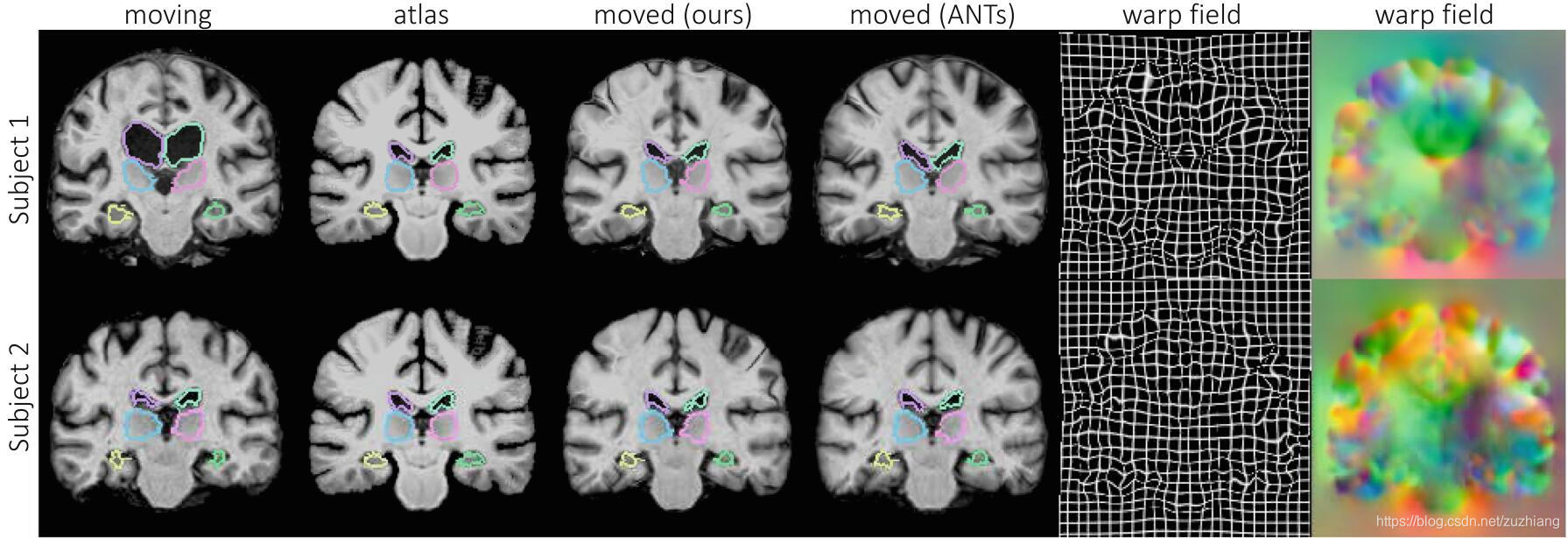
baseline选用的是ANTs软件包中的SyN和VoxelMorph,后者不能保证形变场是微分同胚的或者是不确定的估计。上图两行分别是本文的方法和ANTs的配准结果对比,VoxelMorph的和ANTs的类似,没有画出。
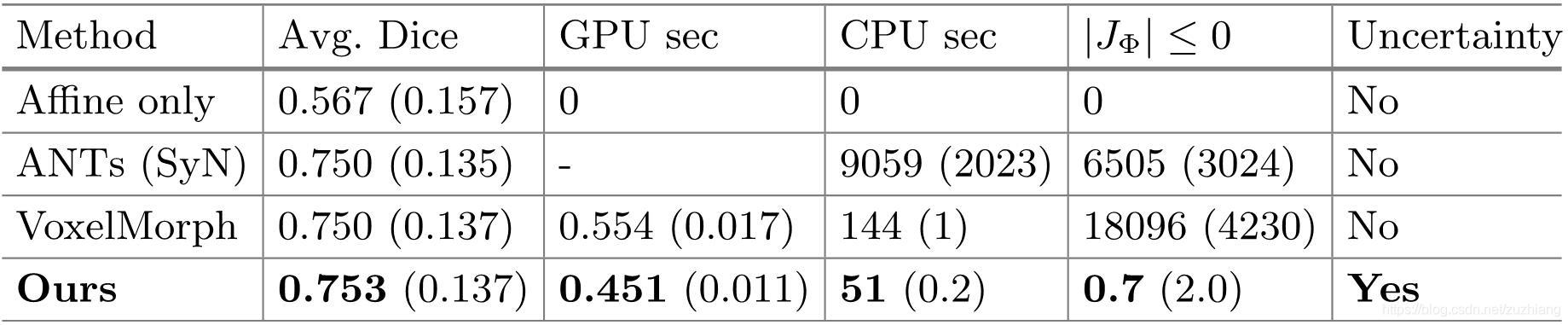
由上图可知,本文所提出的模型不仅在Dice值上达到了最好的水平,而且运行时间更快,并且配准形变场是微分同胚的(几乎没有非负的雅克比体素)。
通过是实验发现
σ
2
∼
(
0.035
)
2
\sigma^2\sim(0.035)^2
σ2∼(0.035)2并且
λ
∈
(
2
w
,
10
w
)
\lambda\in(2w,10w)
λ∈(2w,10w)时效果最好,本文中使用的是
λ
=
7
w
\lambda=7w
λ=7w。
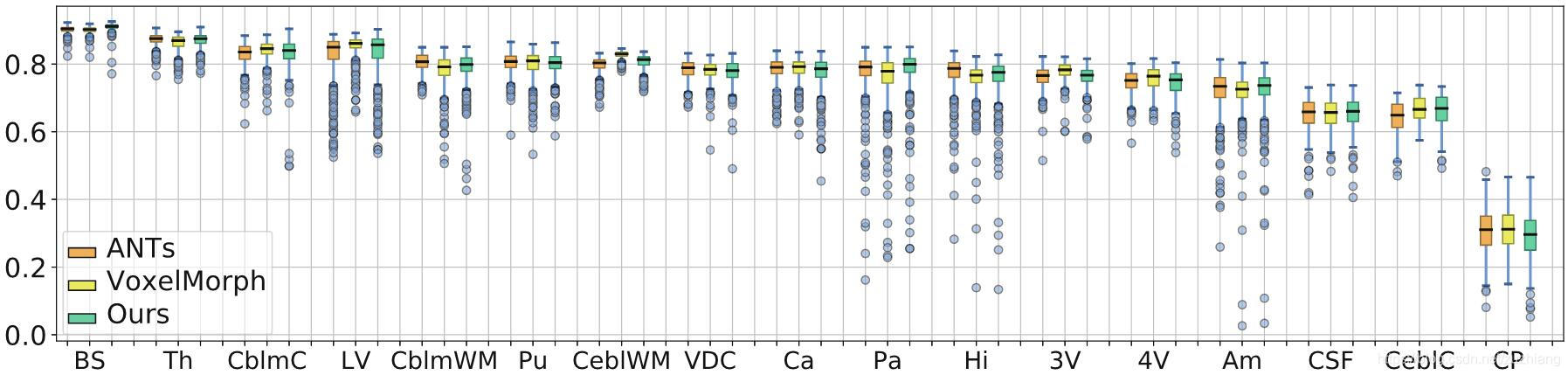
上图是ANTs、VoxelMorph和本文配准结果在脑部各个结构的Dice值对比。
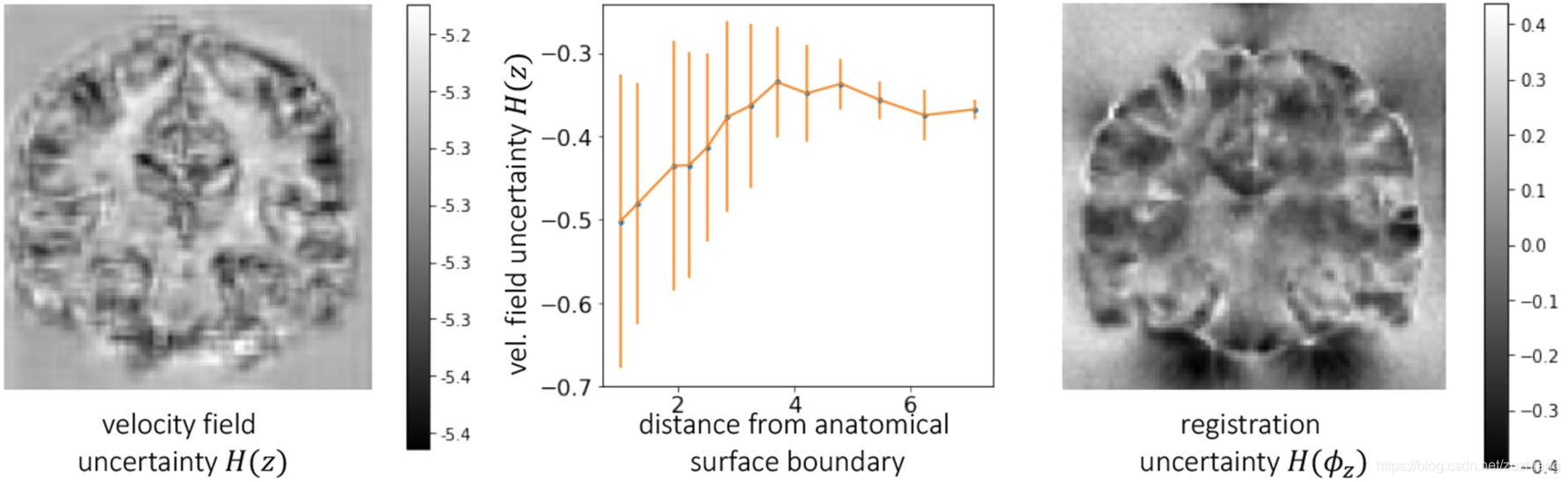
上图中的左图的速度场的不确定性 H ( z ) H(z) H(z)表明了在结构边缘的低不确定性,如中间的折线图所示,这种相关性在最终的配准场的不确定性 H ( ϕ z ) H(\phi_z) H(ϕz)中并不明显,如右图所示。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









