






导读:数据分析要熟练掌握数据科学与数理统计的基本概念。
作者:张秋剑 张浩 周大川 常国珍
来源:大数据DT(ID:hzdashuju)
01 数据科学的基本概念
随着计算机技术的发展和有用数据的快速增多,数据科学应运而生。数据科学的总体目标是在已有数据集的基础上,通过特定的算法提取信息,并将其转化为可理解的知识以辅助做决策。
例如,北京****信用管理有限公司是一家典型的数据公司,有两个主要业务:第一个是为会员机构提供数据加工服务,第二个是提供反欺诈与信用风险管理的产品和咨询服务。
第一个业务的主要工作内容是为会员机构清洗数据,并提供数据存储与管理服务。按照经济学的观点,这类业务的附加价值极低,只能获得社会一般劳动报酬。
第二个业务属于增值服务,数据科学工作者将数据与金融借贷的业务知识相结合,为会员机构提供风控方面的咨询服务。这类业务的边际报酬在客户量达到一定阈值之后是递增的,即一元的投入会获得高于一元的产出,可以为企业高筑商业的安全边际。
从这家公司的业务中可以看出,数据是基础,数据科学是研发,不做研发的企业只能成为代工厂。
数据科学的工作范式见图1-1,以后我们的工作都是在重复这些步骤。
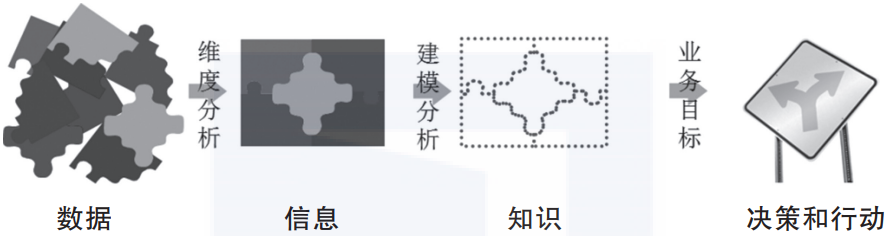
▲图1-1 数据科学的工作范式
我们再来看一个例子。有一个淘宝商家希望通过促销的方式激活沉默客户。这里的“决策和行动”就是向一些客户发放打折券。打折券不应该是随意发放的,比如黏性很高的客户没有打折券也会持续购买。
为了明确应该向哪些客户发放打折券,商家需要了解关于客户的三个知识:客户的流失可能性、客户价值、客户对打折券的兴趣。这些关于客户的知识往往被称为客户标签。根据获取标签的难度,客户标签可以分为基础、统计、模型三种。
基础标签可以从原始数据直接获取,比如性别、年龄段、职业,可以供决策者使用,等价于信息和数据。
统计标签是通过原始数据汇总得到的,比如获得客户的价值标签需要将客户过去一段时间内在企业的所有消费进行汇总,并扣除消耗的成本。统计标签通过对原始数据进行简单的描述性统计分析获得。
模型标签比较复杂,是在基础标签、统计标签和已有的模型标签的基础上,通过构建数据挖掘模型得到的,比如客户的流失概率、违约概率的标签。
具体到本例,客户的流失可能性、客户价值、客户对打折券的兴趣这三个标签都属于统计标签。表1-1所示是该商家的交易流水表,记录了每位客户每笔交易的时间、金额和交易类型。从这些交易流水数据中获取信息的最简单而通用的方法被称为RFM模型。
▼表1-1 淘宝商家的交易流水
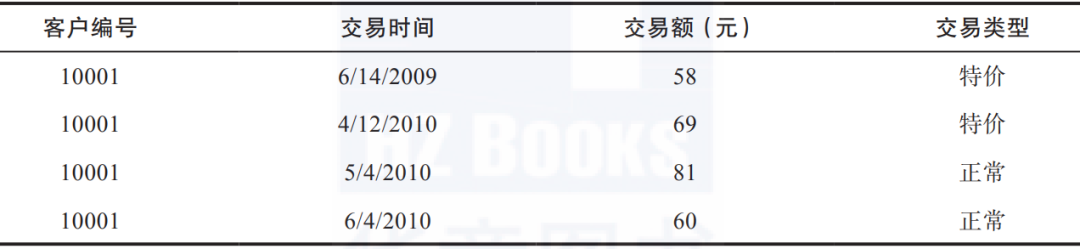
图1-2是根据表1-1的数据所做的RFM模型。RFM模型将每个信息进行二次分类,得到客户分群。
R(最后一次消费时间)标签可以代表客户的流失可能性,离最后一次消费时间越久的客户的流失可能性越高。
M(一段时期内消费的总金额或平均金额)标签可以代表客户的价值,消费额高的客户的价值高,因此可以初步确定重要保持和重要挽留客户都属于应该营销的客户。
最后一个标签F(一段时期内消费的频次)代表客户对打折券的兴趣。
直接使用RFM模型是不能满足要求的,我们可以按照交易类型,计算每个客户所有交易类型中购买特价产品的F(一段时期内消费的频次)或M的占比。
这里有人会开始纠结,两个标签该选哪个呢?其实,“对打折券的兴趣”是一个概念,我们可以用多种方法得到不同的标签来表示这个概念。如果你追求完美,可以使用后续章节中讲的主成分方法进行指标合成。
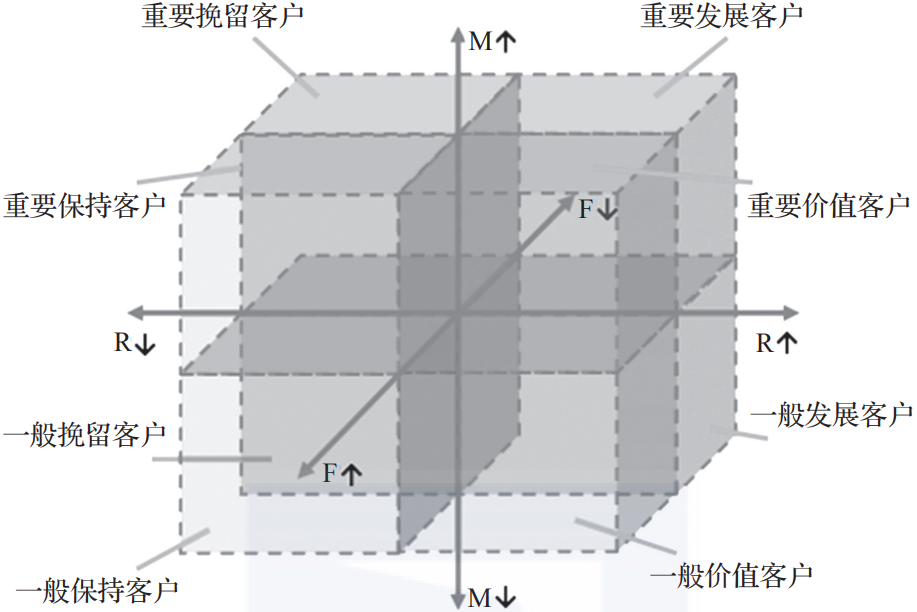
▲图1-2 RFM模型示例
经过以上数据分析,我们终于可以进行有针对性的折扣券营销了。细心的读者可以发现,数据分析是按照图1-1所示的工作范式从右至左规划和分析、从左至右实际操作的。本案例比较简单,数据量不大,使用Excel进行数据分析即可。
不过,当一个企业的年销售额达到几十亿元,活跃客户量达到几十万时,其就必须聘请专业的数据科学工作者,使用复杂的算法和专业的分析工具了。
与数据科学相关的知识涉及多个学科和领域,包括统计学、数据挖掘、模式识别、人工智能(机器学习)、数据库等,如图1-3所示。数据科学的算法来源比较复杂,所以同一概念在不同领域的称呼不一样。为了便于读者将来与不同领域的专家沟通,我们力争列出出现的术语在不同领域对应的称呼。
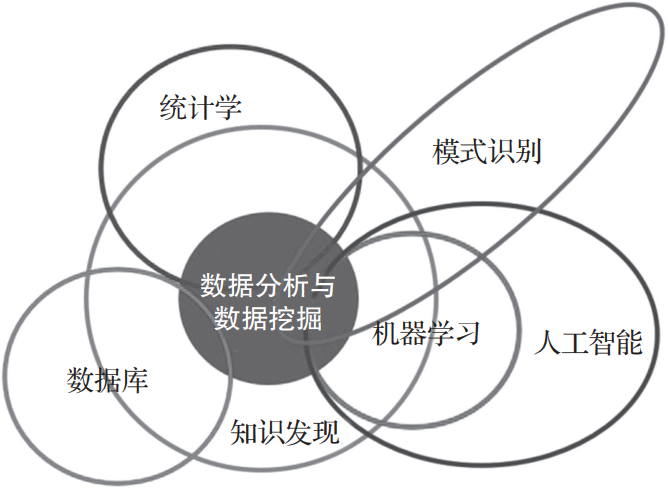
▲图1-3 数据科学知识领域
数据库
数据是数据科学的基础,任何数据分析都离不开数据。如今信息化建设日趋完善,数据库作为存储数据的工具,被数据分析人员广泛使用。
Python和R之类的工具都是内存计算,难以处理太大的数据。因此在对数据库中的数据进行分析前,数据分析师需要借助Oracle之类的数据库工具得到待分析的数据,并在数据库内进行适当的清洗和转换。即使在大数据平台上做数据分析,大量的数据也是在Hive或Impala中处理后才被导入Spark进行建模。
统计学
统计学一直被认为是针对小数据的数据分析方法,不过其仍旧在数据科学领域担任重要的角色,比如对数据进行抽样、描述性分析、结果检验等。目前商业智能中的数据可视化技术绝大多数使用的是统计学中的描述性分析。而变量降维、客户分群主要还是采用多元统计学中的主成分分析和聚类算法。
人工智能/机器学习/模式识别
一些数据科学方法起源于早期科技人员对计算机人工智能的研究,比如神经网络算法是模仿人类神经系统运作的,不仅可以通过训练数据进行学习,而且能根据学习的结果对未知的数据进行预测。
很多人视数学为进入数据科学的拦路虎,这是完全没有必要的。在一开始接触数据科学时,我们完全可以从业务需求出发,以最简单的方法完成工作任务。
02 数理统计技术
数理统计博大精深,但入门并不难。只要掌握本节中介绍的描述性统计分析和统计推断的知识,你便可应对绝大部分工作。
1. 描述性统计分析
描述性统计分析是每个人几乎都会使用的方法,比如新闻联播中提及的人民收入是均值,而不是每个人的收入。企业财务年报中经常提及的是年收入、利润总额,而不是每一笔交易的数据。这些平均数、总和就是统计量。
描述性统计分析就是从总体数据中提炼变量的主要信息,即统计量。日常的业务分析报告就是通过标准的描述性统计分析方法完成的。做这类分析时只要明确分析的主题和可能的影响因素,即可确定可量化主题和影响因素的指标,然后根据这些指标的度量类型选择适用的统计表和统计图进行信息呈现。图1-4展现了统计表的类型和对应的柱形图。
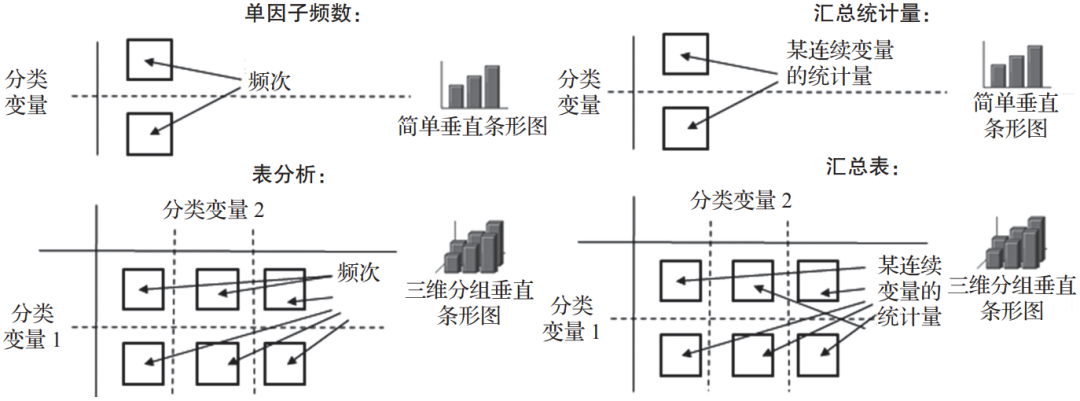
▲图1-4 描述性统计分析方法
以图1-5为例,这是某知名商业智能软件的截图,其实就是图1-4中方法的运用。比如图中“普通小学基本情况”报表就是“汇总表”的直接运用;“普通小学专任教师数”是柱形图的变体,使用博士帽的数量替代柱高;“各省份小学学校数量占比”中使用气泡的大小代表各省小学学校数量的占比情况。
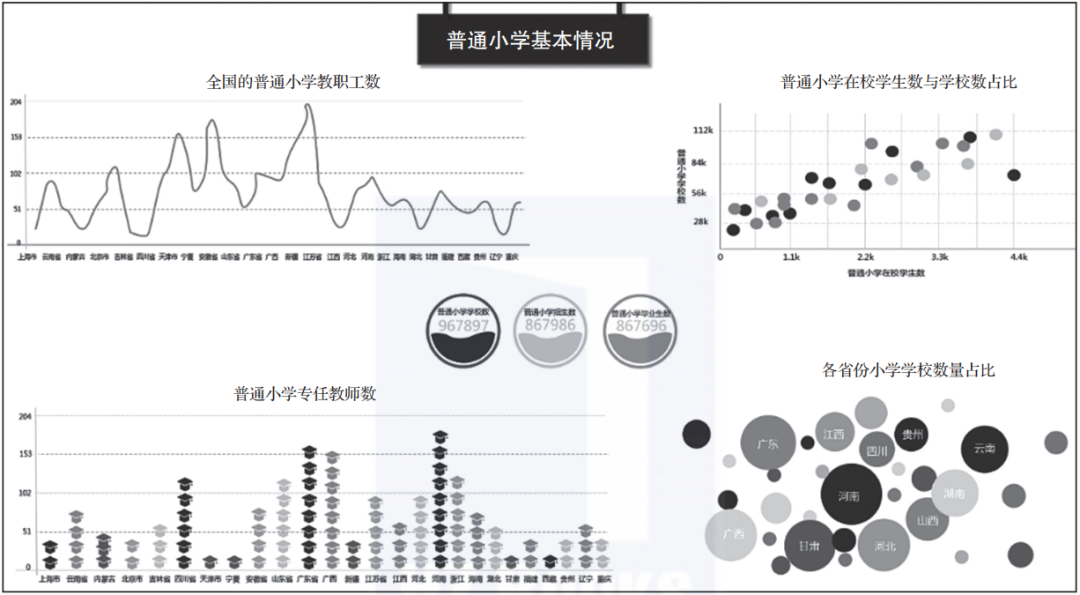
▲图1-5 某商业智能软件的截图
剩下的难点就是理解业务和寻找数据了,这要靠多读分析报告、积累业务经验来解决。
2. 统计推断与统计建模
统计推断及统计建模的含义是建立解释变量与被解释变量之间可解释的、稳定的,最好是具有因果关系的表达式。在模型运用时,将解释变量带入该表达式可以预测每个个体被解释变量的均值。目前,针对统计推断,业界存在两个误解。
统计推断无用论
认为大数据时代只做描述性统计分析即可,不需要做统计推断。由于总体有时间和空间两个维度,即使通过大容量与高速并行处理得到空间上的总体,也永远无法获取时间上的总体,因为需要预测的总是新的客户或新的需求。
更为重要的是,在数据科学体系中,统计推断的算法往往是复杂的数据挖掘与人工智能算法的基础。比如特征工程中大量使用统计推断算法进行特征创造与特征提取。
学习统计推断的产出/投入比低
深度学习大行其道的关键点是产出/投入比高。实践表明,具有高等数学基础的学生可以通过两个月的强化训练掌握深度学习算法并投入生产,而培养同样基础的人开发可落地的商业统计模型的时间至少是半年,原因在于统计推断的算法是根据分析变量的度量类型定制开发的,需要分析人员对各类指标的分布类型有所认识,合理选择算法。
而深度学习算法是通用的,可以在一个框架下完成所有任务。听上去当然后者的投入产出比更高。但是,效率与风险往往是共存的。目前,顶尖AI公司的模型开发人员发现一个现象:解决同样的问题,统计模型开发周期长而更新频次低;深度学习算法开发周期短而优化频次高。
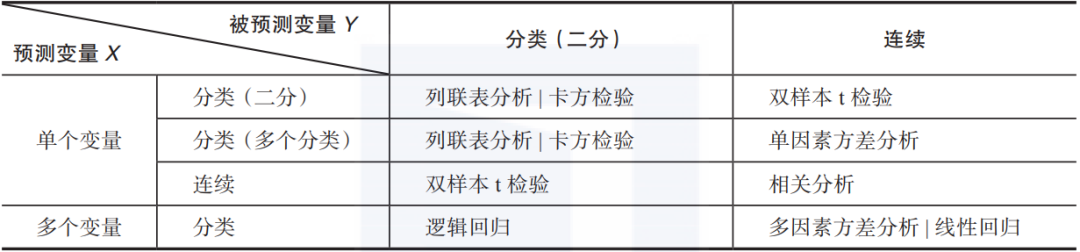
过去,深度学习所鼓吹的实时优化造成企业过度的人员投入,使得企业综合受益不一定高。而我们的目的之一就在于降低统计推断学习的成本。读者将来只要按照表1-2所示方法分析,即可大大缩减学习时间。
▼表1-2 统计推断与统计建模方法
关于作者:张秋剑,就职于腾讯云金融拓展中心,从事微信财富营销管理、数据中台、AI应用等解决方案拓展工作,研究方向包括数字化转型、创新实践等。
张浩,曾任腾讯云金融首席架构师和星环科技金融行业技术总监,主要从事大数据、人工智能、云计算、区块链、联邦学习等相关技术研发与产品设计,具有丰富的企业架构设计、企业数字化战略转型运营与业务咨询经验。
周大川,就职于某中央金融企业金融科技研发中心,主要从事企业级数据平台开发、核心业务平台建设、AI赋能金融科技创新等工作,具有丰富的新一代金融业务系统建设经验。
常国珍,曾任毕马威咨询大数据总监,具有近20年数据挖掘、精益数据治理、数字化运营咨询经验,是金融信用风险、反欺诈和反洗钱算法领域的专家。
本文摘编自《金融商业数据分析:基于Python和SAS》,经出版方授权发布。(ISBN:9787111695837)

《金融商业数据分析:基于Python和SAS》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:腾讯云等资深数据架构师、商业分析师20年经验,全流程讲解金融数据分析思路、方法、技巧,快速入门到精通。

划重点👇
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇














 3557
3557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









