







本文主要是参考学习了网上作者卢龙的一篇文章以及自己对源码的解读两部分组成。参考原文地址Apache Spark内存管理详解。感谢原作者~
spark的内存
按照存储位置主要分为两大块
jvm堆内
主要分为三部分
storage 用于rdd的缓存和存储 默认占60%?,可以占用execution的空间,但是当execution空间不足的时候需要释放
execution 用于reduce的shuffle阶段存放数据 默认占20%,可以占用storage的空间,涉及到shuffle的复杂性,占用时不能释放,只能等它运行结束释放
other 用于用户代码、用户计算逻辑的存储
堆外
这一块与jvm堆不一样,直接在系统内存中开辟空间,不受jvm本身内存回收机制的管理,有spark直接进行操做、使用更灵活、性能会更好
两部分
storage 50%
execution 50%
按照功能划分主要是两部分
storage 相关存储结构 LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
execution /*Map from taskAttemptId -> memory consumption in bytes*/ mutable.HashMap[Long, Long]()
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
代码版本与主要结构如下图:
public enumMemoryMode {
ON_HEAP,
OFF_HEAP
}
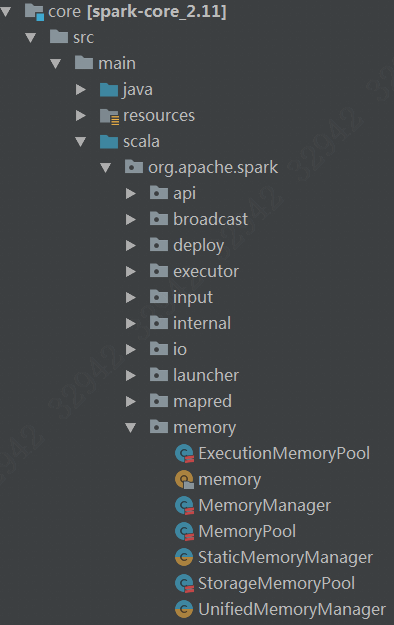
由上面这段枚举代码可知Spark的内存分为两大块:堆内和堆外。
memoryManager
涉及到的最主要的类—memoryManager,这与spark中的其他模块的代码结构也是一样的,很清晰。
/** * An abstract memory manager that enforces how memory is shared between execution and storage. * * In this context, execution memory refers to that used for computation in shuffles, joins, * sorts and aggregations, while storage memory refers to that used for caching and propagating * internal data across the cluster. There exists one MemoryManager per JVM. */ private[spark] abstract class MemoryManager( conf: SparkConf, numCores: Int, onHeapStorageMemory: Long, onHeapExecutionMemory: Long) extends Logging {
该类负责了每个jvm所有task的内存管理,内存管理模式主要又可以分为两种:
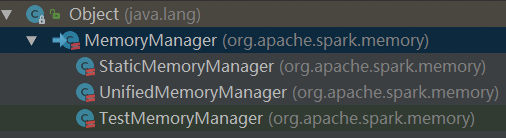
StaticMemoryManager:spark1.6之前使用,内存区域的划分是静态固定,这里保留是为了兼容。
UnifiedMemoryManager:spark1.6之后引入,统一的动态的内存管理模型,默认是采用这种,我们这里解析的也是这一种。
MemoryManager这个虚类的内容不是很多,提供了如下的方法:
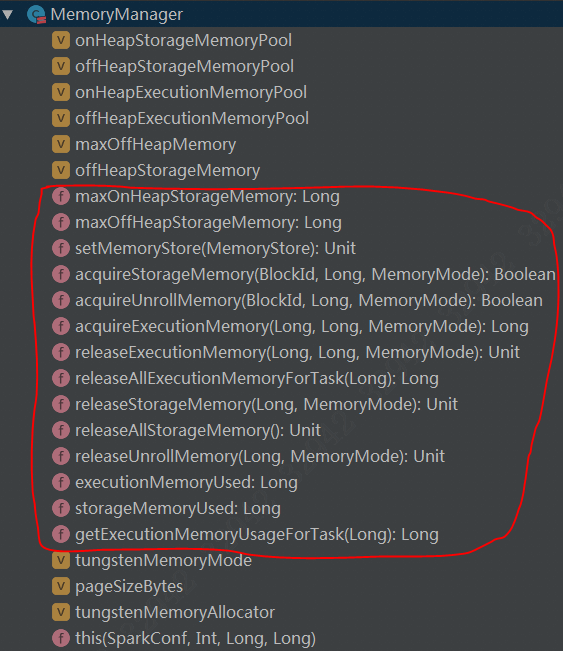
主要是完成具体内存的申请和释放,细节留在后面介绍,这里先介绍下该类所定义的那些具体的变量:
// -- Methods related to memory allocation policies and bookkeeping ------------------------------ @GuardedBy("this") protected val onHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.ON_HEAP) @GuardedBy("this") protected val offHeapStorageMemoryPool = new StorageMemoryPool(this, MemoryMode.OFF_HEAP) @GuardedBy("this") protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.ON_HEAP) @GuardedBy("this") protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, MemoryMode.OFF_HEAP) onHeapStorageMemoryPool.incrementPoolSize(onHeapStorageMemory) onHeapExecutionMemoryPool.incrementPoolSize(onHeapExecutionMemory) protected[this] val maxOffHeapMemory = conf.getSizeAsBytes("spark.memory.offHeap.size", 0) protected[this] val offHeapStorageMemory = (maxOffHeapMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong offHeapExecutionMemoryPool.incrementPoolSize(maxOffHeapMemory - offHeapStorageMemory) offHeapStorageMemoryPool.incrementPoolSize(offHeapStorageMemory)
由上面这段代码可知,内存的划分方法为:堆内or堆外?storage or execution?
堆外的划分比较简单,s(storage)和e(execution)各占0.5。堆内的划分后面再分析。这样的话内存可以分为以下两大块,四小块:
位置 | 用途 |
On-heap | Storage |
On-heap | Execution |
Off-heap | Storage 50% |
Off-heap | Execution 50% |
这里只是做的比较粗一点的划分,细节上比这会有更多的内容,具体可以参考链接中的博文。
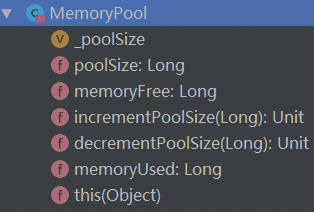
MemoryPool
由上面代码可知,s和e两类内存的具体类分别是StorageMemoryPool和ExecutionMemoryPool,这两个类都继承自MemoryPool这个虚类,简单过一下这个类:
/** * Manages bookkeeping for an adjustable-sized region of memory. This class is internal to * the [[MemoryManager]]. See subclasses for more details. * * @param lock a [[MemoryManager]] instance, used for synchronization. We purposely erase the type * to `Object` to avoid programming errors, since this object should only be used for * synchronization purposes. */ private[memory] abstract class MemoryPool(lock: Object) {
注意看下lock,这里是通过上文提到的MemoryManager对象的锁来实现所有task的互斥和同步的,方法很简单,就是使用了synchronized关键字,这里我也有点疑惑,这个关键字在高并发下性能不是很差么?
看一下它所提供的方法:
下面分析具体的内存模块。
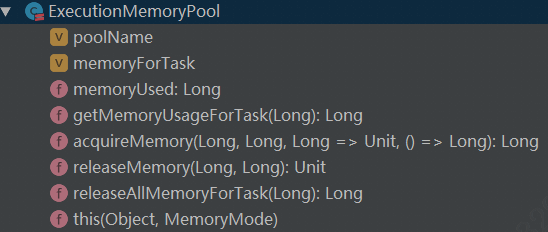
ExecutionMemoryPool
结构如下:
/**
* Implements policies and bookkeepingfor sharing an adjustable-sized pool of memory between tasks.
*
* Tries to ensure that each task gets areasonable share of memory, instead of some task ramping up
* to a large amount first and thencausing others to spill to disk repeatedly.
*
* If there are N tasks, it ensures thateach task can acquire at least 1 / 2N of the memory
* before it has to spill, and at most 1/ N. Because N varies dynamically, we keep track of the
* set of active tasks and redo thecalculations of 1 / 2N and 1 / N in waiting tasks whenever this
* set changes. This is all done by synchronizingaccess to mutable state and using wait() and
* notifyAll() to signal changes tocallers. Prior to Spark 1.6, this arbitration of memory across
* tasks was performed by theShuffleMemoryManager.
*
* @param lock a [[MemoryManager]]instance to synchronize on
* @param memoryMode the type ofmemory tracked by this pool (on- or off-heap)
*/
注释里面有不少干货:
Ø 一个pool是由同一个进程下的所有tasks所共享的
Ø 尽可能的去让每个task获得较为合理的内存资源,避免某些task获得资源太多而导致其他task频繁的spill到磁盘上
Ø 如果总的有N个task,spark会保证每个task至少获得1/2N的内存资源,最多获得1/N的资源,超过了就需要spill至磁盘上,这个N是动态变化的,spark会负责实时跟踪计算,task之间是互斥获取资源的,主要通过对象锁以及wait()和notify()方法来实现
Ø 1.6版本之前的,这部分工作由ShuffleMemoryManager来完成
private[memory]class ExecutionMemoryPool(
lock: Object,
memoryMode: MemoryMode
) extends MemoryPool(lock)with Logging {
private[this]val poolName:String = memoryModematch {
case MemoryMode.ON_HEAP=> "on-heap execution"
case MemoryMode.OFF_HEAP=> "off-heap execution"
}
初始化参数lock就是每一个executor创建的唯一的一个memoryManager,用来实现所有task共享内存资源时的同步与互斥;另外memoryMode的话就两种on-heap和off-heap。
ExecutionMemoryPool里面最重要的数据结构就是:
/**
* Map from taskAttemptId -> memoryconsumption in bytes
*/
@GuardedBy("lock")
private val memoryForTask= newmutable.HashMap[Long, Long]()
taskAttemptedId-> memory consumption in bytes的这样一个hashMap来记录了整个过程中每个task的资源获取情况。后续凡是涉及到对该hashmap的get和set操作都是互斥的,注意这个地方是taskAttemptedId而不是taskId。
简单描述一下比较重要的两个方法:
acquireMemory:
private[memory]def acquireMemory(
numBytes: Long,
taskAttemptId: Long,
maybeGrowPool: Long=> Unit = (additionalSpaceNeeded: Long) =>Unit,
computeMaxPoolSize: () => Long= () => poolSize): Long= lock.synchronized {
assert(numBytes > 0,s"invalid number of bytesrequested: $numBytes")
// TODO: clean up this clunky methodsignature
// Add this task to the taskMemory map justso we can keep an accurate count of the number
// of active tasks, to let other tasksramp down their memory in calls to `acquireMemory`
if (!memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) =0L
// This will later cause waiting tasks towake up and check numTasks again
lock.notifyAll()
}
// Keep looping until we're either surethat we don't want to grant this request (because this
// task would have more than 1 /numActiveTasks of the memory) or we have enough free
// memory to give it (we always leteach task get at least 1 / (2 * numActiveTasks)).
// TODO: simplify this to limit each taskto its own slot
while (true) {
val numActiveTasks =memoryForTask.keys.size
val curMem =memoryForTask(taskAttemptId)
// In every iteration of this loop, weshould first try to reclaim any borrowed execution
// space from storage. This isnecessary because of the potential race condition where new
// storage blocks may steal the freeexecution memory that this task was waiting for.
maybeGrowPool(numBytes - memoryFree)
// Maximum size the pool would have afterpotentially growing the pool.
// This is used to compute the upperbound of how much memory each task can occupy. This
// must take into account potentialfree memory as well as the amount this pool currently
// occupies. Otherwise, we may runinto SPARK-12155 where, in unified memory management,
// we did not take into account spacethat could have been freed by evicting cached blocks.
val maxPoolSize = computeMaxPoolSize()
val maxMemoryPerTask = maxPoolSize /numActiveTasks
val minMemoryPerTask = poolSize / (2* numActiveTasks)
// How much we can grant this task; keep itsshare within 0 <= X <= 1 / numActiveTasks
val maxToGrant = math.min(numBytes,math.max(0,maxMemoryPerTask - curMem))
// Only give it as much memory as is free,which might be none if it reached 1 / numTasks
val toGrant = math.min(maxToGrant,memoryFree)
// We want to let each task get at least 1/ (2 * numActiveTasks) before blocking;
// if we can't give it this much now,wait for other tasks to free up memory
// (this happens if older tasksallocated lots of memory before N grew)
if (toGrant < numBytes && curMem+ toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of$poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
}
0L // Neverreached
}
不是很复杂,主要就是对上文的memoryForTask的hashmap进行同步和互斥访问,根据当前所剩下的内存情况进行分配,并会实时更新整个进程的内存资源情况。
releaseMemory:
defreleaseMemory(numBytes:Long, taskAttemptId:Long): Unit = lock.synchronized {
val curMem = memoryForTask.getOrElse(taskAttemptId,0L)
var memoryToFree =if (curMem <numBytes) {
logWarning(
s"Internalerror: release called on$numBytes bytes but task onlyhas$curMem bytes "+
s"of memory fromthe$poolName pool")
curMem
} else {
numBytes
}
if (memoryForTask.contains(taskAttemptId)){
memoryForTask(taskAttemptId) -=memoryToFree
if (memoryForTask(taskAttemptId)<=0) {
memoryForTask.remove(taskAttemptId)
}
}
lock.notifyAll() // Notify waiters inacquireMemory() that memory has been freed
}
更加简单,不赘述了。
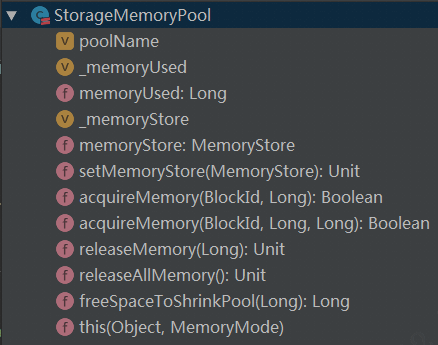
StorageMemoryPool
StorageMemoryPool的结构和上文中的ExecutionMemoryPool基本一致,需要注意的主要如下:
private var_memoryStore: MemoryStore = _
def memoryStore: MemoryStore = {
if (_memoryStore== null) {
throw new IllegalStateException("memory store not initializedyet")
}
_memoryStore
}
下图为它的结构:
相对来说比较简单,其中最复杂的函数应该是如下:
/**
* Acquire N bytes of storage memory forthe given block, evicting existing ones if necessary.
*
* @param blockId the ID of theblock we are acquiring storage memory for
* @param numBytesToAcquire thesize of this block
* @param numBytesToFree theamount of space to be freed through evicting blocks
* @return whether all N byteswere successfully granted.
*/
def acquireMemory(
blockId: BlockId,
numBytesToAcquire: Long,
numBytesToFree: Long):Boolean = lock.synchronized {
assert(numBytesToAcquire >= 0)
assert(numBytesToFree >= 0)
assert(memoryUsed <=poolSize)
if (numBytesToFree >0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId),numBytesToFree,memoryMode)
}
// NOTE: If the memory store evicts blocks,then those evictions will synchronously call
// back into this StorageMemoryPool inorder to free memory. Therefore, these variables
// should have been updated.
val enoughMemory = numBytesToAcquire <=memoryFree
if (enoughMemory) {
_memoryUsed += numBytesToAcquire
}
enoughMemory
}
在1.6以后的版本中,这个acquireMemory是通过下面的函数调用的:
/**
* Acquire N bytes of memory to cache thegiven block, evicting existing ones if necessary.
*
* @return whether all N byteswere successfully granted.
*/
def acquireMemory(blockId: BlockId,numBytes: Long):Boolean = lock.synchronized {
val numBytesToFree = math.max(0,numBytes - memoryFree)
acquireMemory(blockId, numBytes,numBytesToFree)
}
多了一行代码,计算出需要evict的memory大小。这里又会涉及到之前memoryStore里面的方法了:
/** * Try to evict blocks to free up a given amount of space to store a particular block. * Can fail if either the block is bigger than our memory or it would require replacing * another block from the same RDD (which leads to a wasteful cyclic replacement pattern for * RDDs that don't fit into memory that we want to avoid). * * @param blockId the ID of the block we are freeing space for, if any * @param space the size of this block * @param memoryMode the type of memory to free (on- or off-heap) * @return the amount of memory (in bytes) freed by eviction */ private[spark] def evictBlocksToFreeSpace( blockId: Option[BlockId], space: Long, memoryMode: MemoryMode): Long = {
memoryStore里面evict函数,有几个原则:
同一个RDD的Block不会进行evict;
正在读写的Block不会进行evict;
存储模式(on-heap/off-heap)不同的不会进行evict;
Evict的过程就是遍历linkHashMap结构,找到合适的block进行evict操作,这里需要借助spark的blockManager模块来处理block。
MemoryStore
与ExecutionMemoryPool里面的hashMap类似,StorageMemoryPool也有对应的数据结构,这里是MemoryStore,它的结构如下:
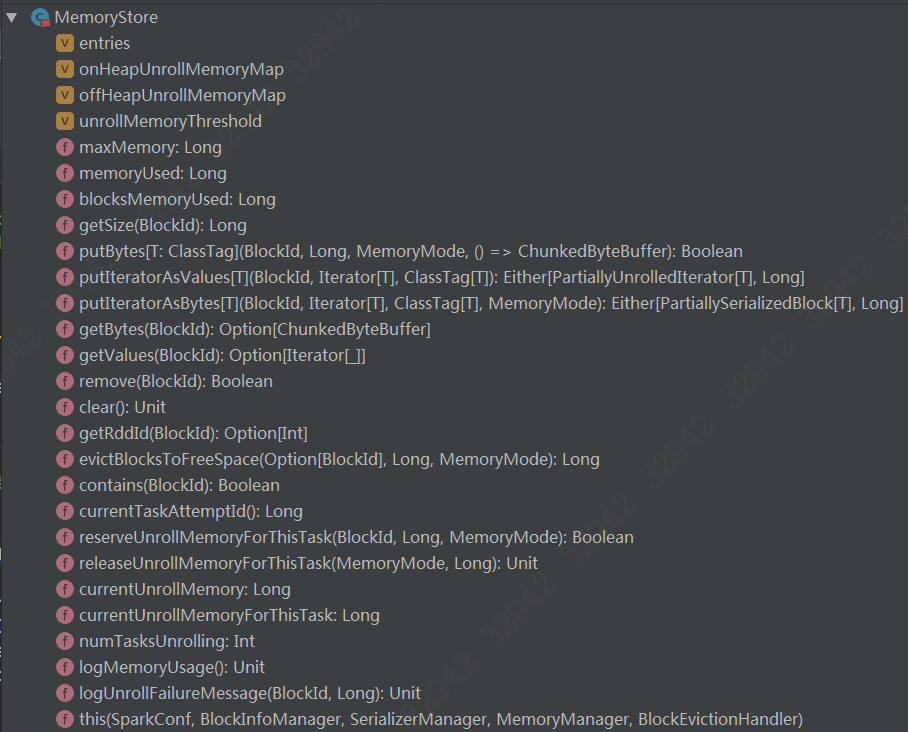
还是比较复杂的
/**
* Stores blocks in memory, either asArrays of deserialized Java objects or as
* serialized ByteBuffers.
*/
private[spark]class MemoryStore(
conf: SparkConf,
blockInfoManager: BlockInfoManager,
serializerManager: SerializerManager,
memoryManager: MemoryManager,
blockEvictionHandler:BlockEvictionHandler)
extends Logging {
// Note: all changes to memory allocations,notably putting blocks, evicting blocks, and
// acquiring or releasing unrollmemory, must be synchronized on `memoryManager`!
private val entries= newLinkedHashMap[BlockId,MemoryEntry[_]](32,0.75f, true)
// A mapping from taskAttemptId to amountof memory used for unrolling a block (in bytes)
// All accesses of this map are assumedto have manually synchronized on `memoryManager`
private val onHeapUnrollMemoryMap= mutable.HashMap[Long, Long]()
// Note: off-heap unroll memory is onlyused in putIteratorAsBytes() because off-heap caching
// always stores serialized values.
private val offHeapUnrollMemoryMap= mutable.HashMap[Long, Long]()
// Initial memory to request beforeunrolling any block
private val unrollMemoryThreshold:Long =
conf.getLong("spark.storage.unrollMemoryThreshold",1024 * 1024)
在内存中存储block,可以是非序列化的java对象或者是序列化的bytebuffer,同样的在这里的所有操作都需要memoryManager对象来做同步。
关于StorageMemory的特点在《Spark内存管理详解》中一段很好的诠释:摘抄一部分:
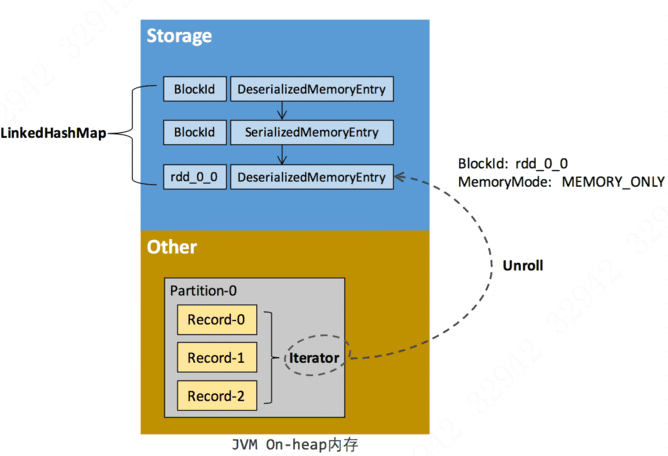
RDD在缓存到存储内存之前,Partition中的数据一般以迭代器(Iterator)的数据结构来访问,这是scala语言的一种遍历数据集合的方法。通过Iterator可以获取分区中每一条序列化或者非序列化的数据项(Record),这些Record的对象实例在逻辑上占据了JVM堆内内存的other部分的空间,同一Partition的不同Record的空间并不连续。
RDD在缓存到存储内存之后,Partition被转换成Block,Record在堆内或堆外存储内存中占用一块连续的空间。将Partition由不连续的存储空间转换为连续存储空间的过程,Spark称之为“展开”(Unroll)。Block有序列化和非序列化两种存储格式,具体以哪种方式取决于该RDD的存储级别。非序列化的Block以一种DeserializedMemoryEntry的数据结构来定义,用一个数组存储所有的java对象,序列化的Block则以SerializedMemoryEntry的数据结构定义,用字节缓冲区(ByteBuffer)来存储二进制数据。每个Executoir的storage模块用一个链式Map结构(LinkedHashMap)来管理堆内和堆外所有的Block对象的实例,对这个LinkedHashMap的新增和删除间接记录了内存的申请和释放。
因为不能保证存储空间可以一次容纳Iterator中的所有数据,当前的计算任务在Unroll时要向MemoryManager申请足够的Unroll空间来临时占位,空间不足则Unroll失败,空间足够时可以继续进行。对于序列化的Partition,其所需的Unroll空间可以直接累加计算,一次申请。而非序列化的Partition则要在遍历Record的过程中一次申请,即每读取一条Record,采样估算其所需的Unroll空间并进行申请,空间不足时可以中断,释放已占用的Unroll空间。如果最终Unroll成功,当前Partition所占用的Unroll空间被转换为正常的缓存RDD的存储空间,如下图所示:
UnifiedMemoryManager
最后介绍最重要的一个类:
/**
* A [[MemoryManager]]that enforces a soft boundary betweenexecution and storage such that
* either side can borrow memory from theother.
*
* The region shared between executionand storage is a fraction of (the total heap space - 300MB)
* configurable through `spark.memory.fraction`(default 0.6). The position of theboundary
* within this space is furtherdetermined by `spark.memory.storageFraction`(default 0.5).
* This means the size of the storageregion is 0.6 * 0.5 = 0.3 of the heap space by default.
*
* Storage can borrow as much executionmemory as is free until execution reclaims its space.
* When this happens, cached blocks willbe evicted from memory until sufficient borrowed
* memory is released to satisfy theexecution memory request.
*
* Similarly, execution can borrow asmuch storage memory as is free. However, execution
* memory is *never* evicted by storagedue to the complexities involved in implementing this.
* The implication is that attempts tocache blocks may fail if execution has already eaten
* up most of the storage space, in whichcase the new blocks will be evicted immediately
* according to their respective storagelevels.
*
* @param onHeapStorageRegionSize Sizeof the storage region, in bytes.
* This region is notstatically reserved; execution can borrow from
* it if necessary. Cached blockscan be evicted only if actual
* storage memory usageexceeds this region.
*/
private[spark]class UnifiedMemoryManagerprivate[memory] (
conf: SparkConf,
val maxHeapMemory: Long,
onHeapStorageRegionSize: Long,
numCores: Int)
extends MemoryManager(
conf,
numCores,
onHeapStorageRegionSize,
maxHeapMemory - onHeapStorageRegionSize){
从注释中可以看出,spark集群中每个executor所管理的内存的总大小:jvmheap-300m
Storage默认为总大小的0.5,1.6以后spark的内存管理是动态的,storage和execution之间没有静态的界限划分,s和e之间可以占用对方的资源,区别是s占用e的资源在e资源不足时需要evict,而e占用s的资源则不可能被evict。
UnifiedMemoryManager结构如下:

功能很清晰,内存分为三大块:storage(unroll)、execution、other(s和e之外的)。
先看下unroll:
override defacquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean= synchronized {
acquireStorageMemory(blockId, numBytes,memoryMode)
}
显然其实unroll就是storage中的一部分,用于rdd的缓存,上文有过详细介绍。
再看下storage:
override defacquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean= synchronized {
assertInvariants()
assert(numBytes >= 0)
val (executionPool,storagePool,maxMemory) = memoryMode match{
case MemoryMode.ON_HEAP=> (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
maxOnHeapStorageMemory)
case MemoryMode.OFF_HEAP=> (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
maxOffHeapMemory)
}
if (numBytes > maxMemory) {
// Fail fast if the block simply won't fit
logInfo(s"Will not store$blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxMemory bytes)")
return false
}
if (numBytes > storagePool.memoryFree) {
// There is not enough free memory in the storagepool, so try to borrow free memory from
// the execution pool.
val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree,numBytes)
executionPool.decrementPoolSize(memoryBorrowedFromExecution)
storagePool.incrementPoolSize(memoryBorrowedFromExecution)
}
storagePool.acquireMemory(blockId, numBytes)
}
首先是根据存储模式获得一个描述内存结构的三元组(executionPool,storagePool,maxMemory)
Storagememory与block相关所以会有具体的blockId
接着判断storage所剩下的资源量,不足的话会从executionPool中借用,同时减少executionPool大小,增加StoragePool的大小。
最后调用StoragePool的acquireMemory函数。
最后是execution:
/**
* Try to acquire up to `numBytes`of execution memory for the current taskand return the
* number of bytes obtained, or 0 if nonecan be allocated.
*
* This call may block until there isenough free memory in some situations, to make sure each
* task has a chance to ramp up to atleast 1 / 2N of the total memory pool (where N is the # of
* active tasks) before it is forced tospill. This can happen if the number of tasks increase
* but an older task had a lot of memoryalready.
*/
overrideprivate[memory]defacquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long= synchronized {
assertInvariants()
assert(numBytes >= 0)
val (executionPool,storagePool,storageRegionSize,maxMemory) = memoryMode match{
case MemoryMode.ON_HEAP=> (
onHeapExecutionMemoryPool,
onHeapStorageMemoryPool,
onHeapStorageRegionSize,
maxHeapMemory)
case MemoryMode.OFF_HEAP=> (
offHeapExecutionMemoryPool,
offHeapStorageMemoryPool,
offHeapStorageMemory,
maxOffHeapMemory)
}
/**
* Grow the execution pool by evictingcached blocks, thereby shrinking the storage pool.
*
* When acquiring memory for a task,the execution pool may need to make multiple
* attempts. Each attempt must be ableto evict storage in case another task jumps in
* and caches a large block between theattempts. This is called once per attempt.
*/
def maybeGrowExecutionPool(extraMemoryNeeded:Long): Unit = {
if (extraMemoryNeeded >0) {
// There is not enough free memory in theexecution pool, so try to reclaim memory from
// storage. We can reclaim any freememory from the storage pool. If the storage pool
// has grown to become larger than`storageRegionSize`, we can evict blocks and reclaim
// the memory that storage hasborrowed from execution.
val memoryReclaimableFromStorage = math.max(
storagePool.memoryFree,
storagePool.poolSize -storageRegionSize)
if (memoryReclaimableFromStorage >0) {
// Only reclaim as much space as is necessaryand available:
val spaceToReclaim =storagePool.freeSpaceToShrinkPool(
math.min(extraMemoryNeeded,memoryReclaimableFromStorage))
storagePool.decrementPoolSize(spaceToReclaim)
executionPool.incrementPoolSize(spaceToReclaim)
}
}
}
/**
* The size the execution pool wouldhave after evicting storage memory.
*
* The execution memory pool dividesthis quantity among the active tasks evenly to cap
* the execution memory allocation foreach task. It is important to keep this greater
* than the execution pool size, whichdoesn't take into account potential memory that
* could be freed by evicting storage.Otherwise we may hit SPARK-12155.
*
* Additionally, this quantity shouldbe kept below `maxMemory`to arbitrate fairness
* in execution memory allocationacross tasks, Otherwise, a task may occupy more than
* its fair share of execution memory,mistakenly thinking that other tasks can acquire
* the portion of storage memory thatcannot be evicted.
*/
def computeMaxExecutionPoolSize():Long = {
maxMemory - math.min(storagePool.memoryUsed,storageRegionSize)
}
executionPool.acquireMemory(
numBytes, taskAttemptId,maybeGrowExecutionPool,computeMaxExecutionPoolSize)
}
由于该类是memoryManager的子类,所以对于内存的释放以及其他操作都在父类memoryManager中实现。
到此spark内存管理模块的几个重要的类都已经介绍完毕,个人觉得需要先结合上文提到的博客,再来看源码这样效果会更好。















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









