







课时101 优化目标
SVM和其它算法的区别
在监督学习中,很多监督学习算法的性能都很相似,我们考虑的不是选哪个算法,而是选择算法时所使用的数据量,这就体现了应用算法时的技巧,比如你设计的用于学习算法的特征的选择,正则化参数的选择。
SVM和神经网络、逻辑回归相比,在学习复杂的非线性方程时能够提供一种更为清晰的方式。
优化目标
SVM的总体优化目标为:

当最小化这个函数的时候,就得到了SVM学习到的参数。
假设函数
支持向量机不会输出概率,我们通过SVM得到的是通过优化上面的代价函数得到一个参数θ,然后进行直接的预测y是等于0还是等于1:若θ的转置乘以x大于等于0,假设函数输出1,反之输出0。
SVM假设函数的形式:
h
θ
(
x
)
=
{
1
θ
>
=
0
0
θ
<
0
h_θ(x)=\left\{ \begin{aligned} 1 &&&&&θ>=0 \\ 0 &&&&&θ<0 \end{aligned} \right.
hθ(x)={10θ>=0θ<0
SVM和逻辑回归的目标函数的区别
首先来看一下逻辑回归的目标函数:
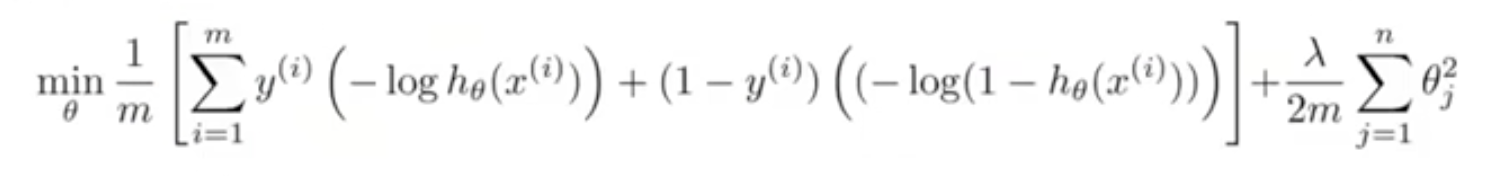
通过对比二者的目标函数,我们可以看出来对逻辑回归做一点改动就可以得到SVM的目标函数,改动如下:
①把两部分改成蓝笔写的部分
 我认为SVM就是把逻辑回归的两个极限y=0和y=1,所以就变成了分类问题,因为当样本取1(或取0)时,对于逻辑回归的假设函数来说
z
=
θ
T
x
z=θ^Tx
z=θTx远大于0(或远小于0),具体看下面的逻辑回归的假设函数和激活函数图:
我认为SVM就是把逻辑回归的两个极限y=0和y=1,所以就变成了分类问题,因为当样本取1(或取0)时,对于逻辑回归的假设函数来说
z
=
θ
T
x
z=θ^Tx
z=θTx远大于0(或远小于0),具体看下面的逻辑回归的假设函数和激活函数图:

接下来我们看逻辑回归的每个单个训练样本对逻辑回归的总体目标函数做的贡献,当y=1和y=0时得到的代价函数如下图,SVM的代价函数(红线部分)就是根据这个做的小的修改,然后取名为
c
o
s
t
1
(
z
)
cost_1(z)
cost1(z)和cost_0(z)$,下标的0和1就指的是样本的y=0和y=1。
修改后得到的SVM的代价函数和逻辑回归的效果很相似,但会使SVM拥有计算上的优势并使之后的优化问题变得简单。

②参数写法上的改动
<1>去掉逻辑回归的m分之一
我们通过代价函数是为了得到最优解θ,m的存在并不会影响最优解的取值,所以去掉只是因为两个算法人们的习惯不同
<2>正则化参数的不同:把λ换成C
目标函数都是由代价函数和正则化项两部分组成的,我们用A表示目标函数,用B表示正则化项,则逻辑回归的目标函数可以写成
A+λB,SVM的可以写成CA+B。
λ和C的作用都是为了平衡A和B这两项,也就是我们想在多大程度上适应训练集,是更注重A还是更注重B。对于A+λB来说,给λ设一个很大的值,证明B有很大的权重;对于CA+B来说,给C设一个很小的值,证明B有很大的权重。所以可以说C和λ成反比,即C=1/λ。
课时102 直观上对大间隔的理解
SVM又叫大间距分类器,SVM就是用尽可能大的间距将样本分开,下面我们就从图像上理解SVM假设。
通过看SVM的代价函数,为了使代价函数变得更小,cost应该取0,根据下图:当有一个正样本的时候,我们需要z>=1;当有一个负样本的时候,我们需要z<=-1。这是SVM和其他算法的很大区别,其他算法一般都是z>=0(或z<0 样本为负样本时)就可以正确分类,因为这样就能使假设函数等于0.

正是因为SVM需要z>=1或z<=-1,这样就建立了安全因子、一个安全间距。
①当C很大时并且数据线性可分(存在一条直线把正样本和负样本完美划分开)
如下图,SVM得到的黑色的线和训练样本的间距最大,这使得SVM具有鲁棒性,因为他在分离数据的时候会尽量用大的间距分离。

②当C很大时会对异常点非常敏感
如下图,没有异常点的时候得到的是黑线,有异常点之后SVM为了用最大间距把样本分开,得到的就会是红色的那条线。如果我们把C设的小,那么得到的还会是黑色那条线,也就是不会被异常点影响,并且对数据不可分的数据也是能够正确进行分类的。

课时103 大间隔分类器的数学原理
内积
两个向量u和v,下面知道一个概念,范数:
u和v的范数(表示为||u||)也叫做欧几里得长度就是
||u||=根号下u1方加u2方

计算内积的方法:将v投影到u上得到p(p是有符号的,可能是正数也可能是负数,u和v夹角大于九十度p就是负数)再乘以u的范数就是v和u的内积,也可以这样算
u
v
内
积
=
u
T
v
=
p
∣
∣
u
∣
∣
=
u
1
v
1
+
u
2
v
2
=
v
T
u
uv内积=u^Tv=p||u||=u_1v_1+u_2v_2=v^Tu
uv内积=uTv=p∣∣u∣∣=u1v1+u2v2=vTu
从公式看SVM如何选择决策边界
下图是SVM的优化目标函数,我们为了简化,我们忽略截距即
θ
0
=
0
θ_0=0
θ0=0,并且将特征数设为2,即只有两个特征向量
x
1
x_1
x1和
x
2
x_2
x2

通过上面讲的内积的知识,可以将上图的目标函数写成下面的形式:

接下来我们就从公式看SVM如何进行决策:
下图左和右分别有两种决策(绿色线),如果SVM选择图左的绿色线作为边界,则根据线性代数的知道我们知道θ是垂直于这条绿色线的向量,那么我们为了满足
p
(
i
)
∣
∣
θ
∣
∣
>
=
1
p^{(i)}||θ||>=1
p(i)∣∣θ∣∣>=1和
p
(
i
)
∣
∣
θ
∣
∣
<
=
−
1
p^{(i)}||θ||<=-1
p(i)∣∣θ∣∣<=−1,
p
(
i
)
p^{(i)}
p(i)也就是每个样本在θ上的投影,我们可以看到左图的投影都比较小,那么为了让乘积大于1只能让||θ||足够大,但是我们的目的就是为了让||θ||足够小,所以SVM不会选择左图那个线。
因此为了得到最大的投影,唯一的方式就是使绿线周围保持最大间距
,这样就会得到右图的那个线,也就是产生大间距分类现象。
















 4990
4990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









