






1 介绍
支持向量机(SVM)作为机器学习中的一种强大工具,主要用于解决分类和回归问题。
分类:在SVM中,我们的目标是找到一个(最优)划分超平面,将不同类别的数据点分隔开。它通过最大化不同类别数据点之间的间隔,同时最小化分类错误来找到最佳的超平面,SVM在处理分类问题时表现出色。支持向量机可以处理线性可分和线性不可分的情况,以及通过核函数处理非线性问题。
回归:在回归问题中,SVM的目标是找到一个函数,尽可能拟合训练数据,并且使得预测误差最小化。
通过深入理解支持向量机在机器学习中的定位和其解决的问题类型,我们可以更好地掌握这一强大工具的应用和优势。在接下来的部分,我们将深入研究支持向量机的基本概念和工作原理。
2 分类
2.1 线性可分支持向量机
1.超平面
在样本空间中找到一个划分超平面,将不同类别的样本分开,以至两类别数据之间的间隔最大,同时这个最优超平面所产生的分类结果是最具鲁棒性的。


划分超平面可通过线性方程来描述:
其中w为法向量,b为位移项(截距)。
这个划分超平面由w和b决定,想要找到划分超平面就需要找到最合适的w和b值。
2.支持向量
样本空间中任意点x到超平面的距离为:

若超平面可以正确分类样本,令:

训练数据中距离超平面最近的几个特殊点(图中的红点和红圈)使等号成立,它们就是“支持向量”(support vector)。这些支持向量决定了超平面的位置和方向,因此它们在分类问题中具有重要的意义。
两个异类支持向量到超平面的距离之和为:

被称为“间隔”。 如图:

3.寻找最大间隔(划分超平面)
也就是要找参数w和b,使得间隔最大。

可以看出,最大化间隔就是最大化,等价于最小化
:

(这是一个规划问题。)
这就是支持向量机(SVM)的基本型。
4.对偶问题求解超平面
最大间隔划分超平面对应的模型为:
![]()
对求最小化的式子,将目标函数和约束条件结合,引入拉格朗日乘子 α,定义 Lagrange 函数:

其中,α_i 是拉格朗日乘子。

将它们代入Lagrange函数,消去w和b,得到规划问题的对偶问题:


解出α,再求解w和b,得到模型:
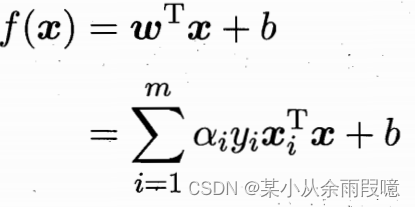
上述过程需要满足条件以下条件,具体可见西瓜书:
2.2 核函数与非线性支持向量机
1.核函数
前面的叙述解决的是训练样本为线性可分的情况(存在一个划分超平面能正确分类训练样本)。对于非线性不可分的情况需要引入核函数。
核函数是支持向量机(SVM)中的关键概念之一,它允许 SVM 在更高维度的特征空间中进行非线性映射,从而处理复杂的数据集。核函数的引入使得 SVM 在解决非线性问题时更加灵活和强大。


假设原始特征空间中的特征向量为 x,映射后的特征向量为 ϕ(x),则对于在样本空间中划分超平面对应的模型为:

求解过程与前述一样。对偶问题为:

由于直接计算通常很困难,则设想一个核函数。在支持向量机中,核函数是一个将输入数据从原始特征空间映射到更高维度的函数。核函数可以表示为:
其中,K是核函数,<,>表示内积。即 x_i与x_j在特征空间的内积等于它们在原始样本空间中通过函数k(x_i,x_j)计算的结果。
2.核函数的作用
-
处理非线性问题: 核函数使得 SVM 能够处理原始特征空间中线性不可分的问题,通过映射到更高维度的空间使得数据在新空间中变得线性可分。
-
避免显式特征映射: 在高维度空间中进行显式的特征映射可能会导致计算复杂度的增加,而核函数允许在不显式计算映射的情况下进行非线性变换。
-
提高计算效率: 使用核函数可以避免在高维度空间中进行大量的计算,通过核技巧(kernel trick)直接在原始特征空间中计算核函数值。
3.常见的核函数

2.3 硬间隔和软间隔
硬间隔和软间隔是支持向量机(Support Vector Machine,SVM)中用于处理线性不可分数据的概念。它们涉及到对数据集中的噪声和异常值的容忍度,以及对模型复杂度的不同处理。
1. 硬间隔(Hard Margin)SVM
硬间隔 SVM 是指在训练数据集中,要求所有样本点都严格位于类别之间的间隔之外。简而言之,它期望在特征空间中找到一个超平面,能够完美地将不同类别的样本分隔开。硬间隔 SVM 的优化目标是最大化间隔,同时确保所有的训练样本都被正确分类。这对于线性可分的情况是适用的。
硬间隔 SVM 的优点是它在满足线性可分条件下能够得到最优的分类结果。然而,它对于数据中的噪声和异常值非常敏感,因为它要求所有的样本都必须被正确分类。在实际应用中,数据往往不是完全线性可分的,因此硬间隔 SVM 的使用受到了一定的限制。
2. 软间隔(Soft Margin)SVM
软间隔 SVM 引入了对误分类的容忍,允许一些样本点位于间隔之内或甚至在错误的一侧。这是为了处理现实中存在噪声或不可避免的一些异常值的情况。软间隔 SVM 的优化目标是最大化间隔的同时,最小化误分类的样本点数目。
软间隔 SVM 的优点在于对于一些噪声或异常值,它能够更具鲁棒性。它能够处理一些线性不可分的情况,并且允许在最优化过程中有一些样本点被错误分类。
算法原理:
软间隔就是对于我们的最优化问题中允许部分样本(尽可能地少)不满足约束条件:
将这个严格的约束条件转化为灵活的“损失”,损失函数要求:满足约束时,损失为0;不满足约束时,损失不为0,且损失与违反约束条件的程度成正比。

软间隔 SVM 它引入了一个新的参数(惩罚参数 C),用于平衡最大化间隔和最小化误分类的权衡。选择合适的 C 对于模型的性能至关重要,需要通过交叉验证等方法来调优。
0/1损失函数非凸、非连续,最小化损失函数不易求解,通常用其他函数代替(代替损失函数):



令![]()

求解:


具体见西瓜书:

总体而言,在处理实际数据时,通常会选择软间隔 SVM,因为它更灵活,对于一些噪声和异常值有更好的鲁棒性。
3 回归


类似软间隔。计算损失:




(待补充内容)
参数调优与模型评估
- SVM 的参数:核函数的选择、惩罚参数等。
- 交叉验证:介绍如何使用交叉验证调整参数。
- 性能度量:解释如何评估支持向量机的性能,如准确率、召回率等。
实际应用与案例研究
- 提供一些实际应用场景,如图像识别、文本分类等。
- 引入一些经典的支持向量机案例,解释如何应用和调整参数。
本篇文章为学习笔记,具体的内容和解释可参考西瓜书、软间隔与支持向量回归。















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









