







图解Protobuf编码
Protobuf是Google发布的消息序列化工具。Protobuf定义了消息描述语法(proto语法)和消息编码格式,并且提供了主流语言的代码生成器(protoc)。本文仅讨论Protobuf消息编码格式,并且假定读者已经熟悉Protobuf消息描述语法(proto2或者proto3)。
基本编码规则
Protobuf消息由字段(field)构成,每个字段有其规则(rule)、数据类型(type)、字段名(name)、tag,以及选项(option)。比如下面这段代码描述了由10个字段构成的Test消息:
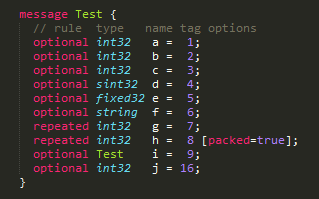
序列化时,消息字段会按照tag顺序,以key+val的格式,编码成二进制数据。以下面这段Java代码为例:
byte[] data = Test.newBuilder()
.setA(3).setB(2).setC(1)
.build().toByteArray();序列化之后,可以把data里的数据想象成下面这样:

proto2语法定义了3种字段规则:required、optional、repeated。proto3语法去掉了required规则,只剩下optional(默认)和repeated两种。由上图可知,如果没有给optional和repeated字段赋值,那么字段是不会出现在序列化后的数据中的。详细的编码规则,请继续阅读。
数据划分
Protobuf消息序列化之后,会产生二进制数据。这些数据(精确到bit)按照含义不同,可以划分为6个部分:MSB flag、tag、编码后数据类型(wire type)、长度(length)、字段值(value)、以及填充(padding)。后文会图解这些部分的具体含义,这里先约定好图中消息各部分使用的颜色:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









