







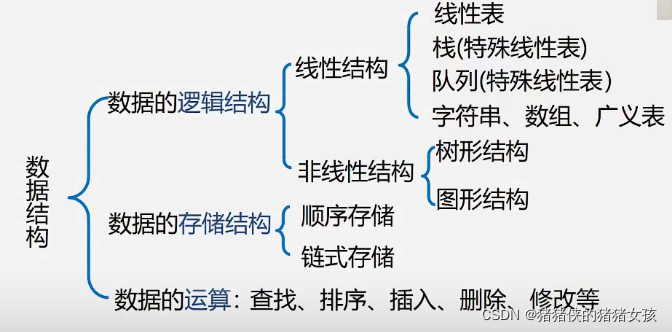
一、数据结构
二、平均查找长度(ASL)
ASL(Average Search Length),即平均查找长度,在查找运算中,由于所费时间在关键字的比较上,所以把平均需要和待查找值比较的关键字次数称为平均查找长度。
它的定义是这样的:
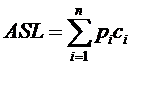
其中n为查找表中元素个数,Pi为查找第i个元素的概率,通常假设每个元素查找概率相同,Pi=1/n,Ci是找到第i个元素的比较次数。
三、顺序表查找
顺序表查找有三种方法:顺序查找,折半查找(二分查找),分块查找
1.顺序查找
顺序查找是一个个元素对比,即
int key;
cin >> key;
vector<int> nums = {.....};
for(int i = 0; i < nums.size(); i++)
{
if(nums[i] == key)
break;
}
顺序查找的平均查找长度(ASL):
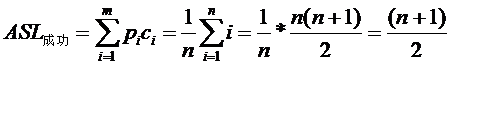
2.折半查找
折半查找又叫二分查找,那么折半查找,可以用二叉树描述查找过程,查找区间中间位置作为根,左子表为左子树,右子表为右子树,先与树根结点进行比较,若k小于根,则转向左子树继续比较,若k大于根,则转向右子树,递归进行上述过程,直到查找成功或查找失败。
代码表示如下
void test(const vector<int>& nums, int target)
{
int left = 0;
int right = nums.size();
while(left <= right)
{
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return;
if(nums[mid] < target)
left = mid+1;
else
right = mid - 1;
}
}
从上面代码可以看出,折半查找适合排序算法。对于非排序算法,需要先排序再二分查找
折半查找的ASL:
假设顺序表的长度是n,因其是使用二叉树的方式进行查找,所以表长为n,相当于结点总数为n,此时表的层数是h = log2(n+1),注意:这么计算的原因是假设数是满二叉树。
假设表中每个记录的查找概率相等Pi=1/n
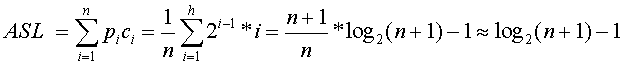
3.分块查找
1、条件:
1)将顺序表分为几块,且表为有序表或者是分块有序表
若i < j,则j块中所记录的关键字均大于第i块中的最大关键字
2)建立“索引表”(每个结点含有最大关键字域和指向本块第一个结点的指针,且按关键字有序)
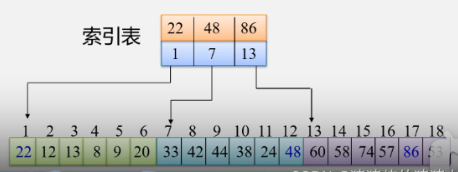
2、分块查找流程:
1)先分块
2)每块存储最大值和起始位置的下表
3)在块中进行折半查找
3、分块查找的ASL
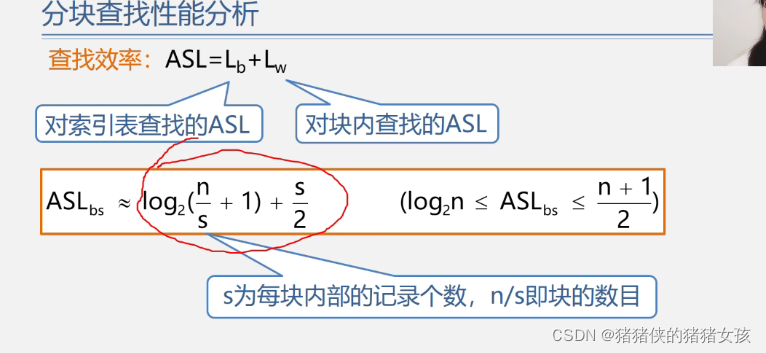
这种方法的时间复杂度大于二分查找,但是比顺序查找要小,接近二分查找。但是这种方法不局限于排序数组,但是二分查找需要局限在这里
这种方法查找和删除比较容易,但是需要额外空间存储查找表
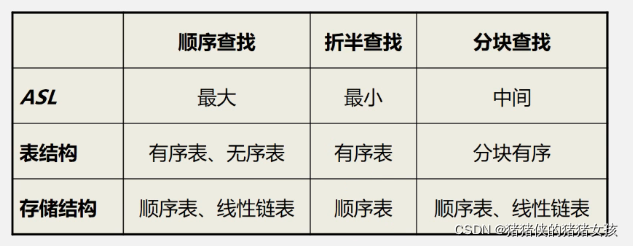
4.顺序表查找的对比
四、散列表
1.散列表构造
1、构造要求:
1)n个数据仅占用n个地址,虽然散列查找时以空间换时间,但仍希望散列的地址空间尽可能小
2)希望尽量均匀存放元素,避免冲突
2、构造方法:
直接定址法,数字分析法,平方取中法,折叠法,除留余数法,随机数法
1)直接定址法
Hash(key) = a*key + b
其中a和b是常数
优点:以关键码key的某个线性函数值为散列地址,不会发生冲突
缺点:要占用连续地址空间,空间效率低
2)数字分析法
若关键字是以r为基的数(如:以10为基的十进制数),并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
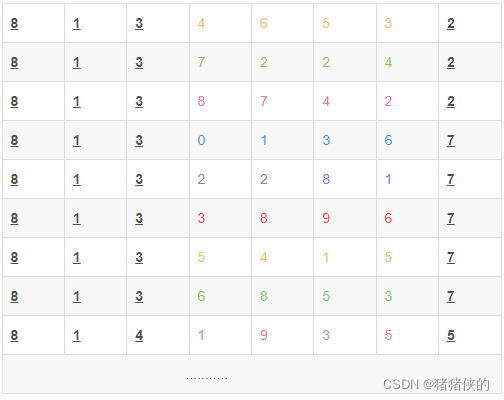
举例:有80个记录,其关键字为8位十进制数,假设哈希表长1000_{10},则可取两位十进制数组成哈希地址,为了尽量避免冲突,可先分析关键字。
经分析,发现第一位、第二位都是8,1,第三位只可能取3或4,第八位只可能取2,5或7,所以这四位不可取,那么对于第四、五、六、七位可看成是随机的,因此,可取其中任意两位,或取其中两位与另外两位的叠加求和舍去进位作为哈希地址。
3)平方取中法
取关键字平方后的中间几位为哈希地址。
举例:为BASIC源程序中的标识符键一个哈希表(假设BASIC语言允许的标识符为一个字母或者一个字母和一个数字两种情况,在计算机内可用两位八进制数表示字母和数字),假设表长为512=2^9,则可取关键字平方后的中间9位二进制数为哈希地址。(每3个二进制位可表示1位八进制位,即3个八进制位为9个二进制位)
4)折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。适用于关键字位数比较多,且关键字中每一位上数字分布大致均匀时。
5)除留余数法
Hash(key) = key mod p
其中p是任意整数,一般是选择比表长小的质数
这种方式容易发生地址冲突
6)随机数法
H(key)=random(key)
选择一个随机函数,取关键字的随机函数值为它的哈希地址。
适用于关键字长度不等时。
2.开放地址散列表构造
上面六种方法的散列构造是定址的,易发生地址冲突的问题
开放地址可以有效的避免这个问题
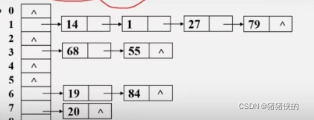
1)链地址法
(1)基本思想:相同散列地址的记录链成一单链表
m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态结构
(2)优点:
地址不冲突,无聚集现象
链表上结点空间动态申请,更适合表长不确定的情况
(3)链地址建立散列表的步骤
- 取数据元素的关键字key,计算其散列函数值(地址)。若该地址对应的链表为空,将该元素插入此链表;否则执行第2步解决冲突
- 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若该地址对应的链表不为空,则利用链表的头插法或者尾插法将该元素插入进链表中
2)开放定址址法
(1)基本思想:右冲突时就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将元素存入
比如:
除留余数法:Hi = (Hash(key) + d)mod m
其中d表示的时增量序列;常用的增量序列有:

(2)以二次探测法为例,解释下详细步骤
eg: 有一下10个元素:60,17,29,38,…将其存入哈希表中
因为是10个元素,所以开辟11个空间。
根据除留余数法进行散列表构造,并设置余数是11
因此 60,17,29分别存入地址5,6,7中
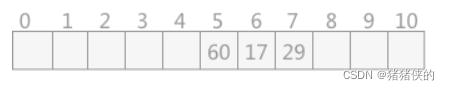
38余11为5和60冲突。此时根据二次探测法原理,提供一个增量,其按照1,-1,2,-2,4,-4…的规律变化,直到找到空空间,
(38+1)%11 = 6冲突
(38-1)%11 = 4
发现地址为空,因此将38存入下标为4的空间

以此类推,存入其他元素
3.散列表查找效率分析

其中ASL是平均查找长度
装填因子是散列表中已有的元素个数和容量的比值

















 3772
3772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









