






原文链接
https://arxiv.org/abs/2104.10729
Abstract & Introduction
Abstract
目标:为了改善在低光照环境中捕捉图像的感知和可解释性
Introduction
基本任务:弱光增强
传统的弱光增强方法:直方图均衡化 【28】,【29】;Retinex模型 【30】,【31】,【32】,【33】,【34】,【35】,【36】,【37】
1.典型的基于Retinex模型的方法
通过某种先验或正则化将弱光图像分解为反射分量和光照分量,将估计的反射分量作为增强结果处理。这种方法的局限性是:
1)将反射分量作为增强结果的理想假设并不总是成立,特别是考虑到各种光照特性,这可能导致不切实际的增强,如细节丢失和失真的颜色
2)Retinex模型通常忽略噪声
3)不准确的先验或正则化可能导致增强结果产生伪影和颜色偏差
4)优化过程复杂,运行时间长
2.基于深度学习的LLIE
优势:更好的准确性,鲁棒性和速度
使用的学习策略:监督学习(supervised learning),强化学习(reinforcement learning),无监督学习(unsupervised learning),零次学习(zero-shot learning),半监督学习(semi-supervised learning)(【38】、【39】,【40】,【41】,【42】,【43】,【44】,【45】,【46】也可以提升图像亮度,但不是用来处理弱光环境图像的)

【47】论述的为传统LLIE方法,【48】从人类和机器视觉的角度讨论了几种传统和基于深度学习的LLIE方法的实验性能
基于深度学习的LLIE
问题定义
将图像定义为![]() ,模型定义为
,模型定义为![]() ,通过优化参数来降低损失函数L
,通过优化参数来降低损失函数L![]()
学习策略
1.有监督学习
端到端方法
1)LLNET【1】:一种叠稀疏去噪自编码器【49】的变形,同时对弱光图像进行增量和去噪。
2)MBLLEN【3】:端到端多分枝增强网络。通过特征提取模块、增强模块和融合模块提取有效的特征表示来提高LLIE的性能。【15】提出了其他三个子网,包括光照网、融合网和恢复网,以进一步提高性能。
3)【12】:设计了一个更复杂的端到端网络,包括用于图像内容增强的编解码器网络和用于图像边缘增强的循环神经网络。
4)EEMEFN【16】:包括多曝光融合和边缘增强两个阶段,并提出了一种用于LLIE的多曝光融合网络TBEFN【20】,TBEFN估计了两个分支的一个传递函数,可以得到两个增强结果。最后,采用一种简单的平均方法对两幅图像进行融合,并通过一个细化单元进一步细化结果。此外,在LLIE中引入了金字塔网络【18】、残差网络【19】和拉普拉斯金字塔【21】(DSLR)。这些方法通过LLIE常用的端到端网络结构有效地集成特征表示。
5)【50】:在观测到噪声在不同的频率层中表现出不同程度的对比度的基础上,提出了一种基于频率的分解增强网络。该网络在低频层抑制噪声后恢复图像内容,在高频层推断图像细节。
基于Retinex模型的深度学习方法(由于Retinex理论【51】,【52】,相较于端到端方法有更好的增强性能,通常通过专门的子网络分别增强光照分量和反射分量)
1)【4】:提出了一个Retinex网络,包括一个分解网络,它将输入图像分割成不依赖光的反射和结构感知的平滑照明,以及一个增强网络,它调整照明图以进行弱光增强。
2)【5】:提出了一种用于弱光照图像增强的轻量级LightenNet,它只包含4层。LightenNet将弱光照图像作为输入,然后估计其光照图。基于Retinex理论,将光照图除以输入图像得到增强后的图像。
3)DeepUPE网络【53】:提取全局和局部特征来学习图像到光照的映射。
4)KinD【11】:开发了用于层分解、反射率恢复和光照调整的三个子网。
5)KinD++【54】:通过多尺度光照注意模块,缓解了KinD【11】结果中留下的视觉缺陷。
6)渐进式Retinex网络【10】:IM-Net估计光照,NM-Net估计噪声水平。这两个子网以渐进的机制工作,直到获得稳定的结果。(解决基于深度Retinex方法中忽略噪声的问题)
7)【14】:将语义分割与Retinex模型相结合,进一步提高了实际情况下的增强性能。其核心思想是利用语义优先指导光照分量和反射分量的增强。
现实数据驱动方法(上述方法虽然取得了不错的性能,但由于使用了合成训练数据,在实际弱光情况下泛化能力较差。为了解决这个问题,使用一些其他方法尝试生成更真实的训练数据或捕捉真实的数据)
1)【6】:构建了一个多曝光图像数据集,其中不同曝光等级的低对比度图像有相应的高质量参考图像。每一幅高质量的参考图像都是通过主观地从13种不同方法增强的结果中选择最优输出得到的。在构建的数据集上训练频率分解网络,通过两级结构分别增强高频层和低频层。
2)SID【2】:收集了一个真实的微光图像数据集,并训练U-Net【55】学习从微光原始数据到sRGB空间中相应的长曝光高质量参考图像的映射。
3)DRV【8】:将SID数据集扩展到弱光视频(DRV)。DRV包含的静态视频与相应的长期曝光地面真相。为了保证动态场景视频处理的泛化能力,提出了一种暹罗网络。
4)SMOID【9】(增强黑暗中的移动物体):一个共轴光学系统来捕捉时间同步和空间对齐的微光和明亮视频对。SMOID视频数据集包含动态场景。为了在sRGB空间中学习从原始弱光视频到明亮视频的图,提出了一种基于三维u - net的网络。针对以往弱光视频数据集(如DRV数据集【8】仅包含统计视频,SMOID数据集【9】仅包含179个视频对)的局限性。
5)SIDGAN(一种弱光视频合成流水线):通过具有中间域映射的半监督双CycleGAN生成动态视频数据(raw - rgb)。为了训练这个管道,我们从Vimeo-90K数据集【56】中收集了真实的视频。从DRV数据集【8】中采集弱光原始视频数据和对应的长曝光图像。本工作利用综合的训练数据,采用与【2】相同的U-Net网络结构进行弱光视频增强。
2.强化学习
在没有成对训练数据的情况下,【22】通过强化对抗学习(深度曝光)来学习曝光照片。首先根据曝光量将输入图像分割为子图像。对于每一个子图像,采用基于强化学习的策略网络顺序学习局部曝光。奖励评价函数采用对抗性学习方法进行逼近。最后利用每次局部曝光对输入进行润色,得到不同曝光下的多幅润色图像。最终通过融合这些图像得到结果。
3.无监督学习
在配对数据上训练深度模型可能会导致过拟合和有限的泛化能力。为了解决这一问题,【23】中提出了一种名为EnligthenGAN的无监督学习方法。EnligthenGAN采用注意力引导的U-Net【55】作为生成器,并使用全局-局部鉴别器,以确保增强的结果看起来像真实的正常光图像。除了全局和局部对抗损失外,还提出了全局和局部自特征保持损失来保持增强前后的图像内容。这是单路径生成对抗网络(GAN)结构稳定训练的关键。
4.零次学习(监督学习、强化学习和非监督学习方法要么泛化能力有限,要么训练不稳定。为了解决这些问题,提出了零镜头学习,仅从测试图像中学习增强)
1)ExCNet【24】(背光图像恢复):首先使用网络来估计最适合输入背光图像的s曲线。一旦估计出s曲线,使用引导滤波器【57】将输入图像分割为一个基础层和一个细节层。然后根据估计的s曲线对基层进行调整。最后,使用韦伯对比度【58】融合细节层和调整后的基层。为了训练ExCNet,作者将损失函数表述为一个基于块的能量最小化问题。
2)RRDNet【26】(用于曝光不足的图像恢复):通过迭代最小化特别设计的损耗函数,将输入图像分解为光照、反射率和噪声。
3)ZeroDCE【25】(一种结合视网膜重建损失、纹理增强损失和光照引导噪声估计损失的算法):ZeroDCE将光增强作为图像特定曲线估计的任务,以低光图像为输入,产生高阶曲线作为输出。这些曲线用于对输入的动态范围进行像素化调整,以获得增强的图像。
4)ZeroDCE++【59】:这种基于曲线的方法在训练过程中不需要任何成对或非成对的数据。它们通过一组非参考损失函数来实现零次学习。此外,与基于图像重建的方法需要大量计算资源不同,图像到曲线的映射只需要轻量级网络,推理速度快。
5.半监督学习(结合有监督学习和无监督学习的优点)
DRBN【27】:首先在监督学习下恢复增强图像的线性频带表示,然后通过基于无监督对抗学习的可学习线性变换对给定频带进行重组,得到改进的频带表示。
有监督学习的缺陷:
1)收集大规模的成对数据集,覆盖不同的现实世界的低光条件是困难的
2)合成的低光图像不能准确地代表现实世界的照度条件,如空间变化的照明和不同水平的噪声
3)在配对数据上训练深度模型可能会导致过度拟合和对不同光照属性的真实图像的有限泛化。
无监督学习,强化学习,半监督学习,零次学习的缺陷:
1)对于非监督学习/半监督学习方法,如何实现稳定训练、避免颜色偏差、建立跨域信息关系是当前方法面临的挑战
2)对于强化学习方法,设计有效的奖励机制和实现高效稳定的训练是一个复杂的问题。
3)对于零次学习方法,在考虑颜色保留、伪影去除和梯度反向传播时,非参考损失的设计是非常重要的。

技术回顾和探讨

网络结构
现有模型采用多种网络结构设计,如U-Net,金字塔网络,多级网络,频率分解网络等,而主要使用的是U-Net和类U-Net网络。因为U-Net能够有效地集成多尺度特征,同时使用低级和高级特征。这些特性对于实现令人满意的弱光增强至关重要。
目前的LLIE网络所忽略的一些问题:
1)极低光图像经过几个卷积层后,由于像素值较小,梯度反向传播过程中可能会消失。
2)类U-Net网络中使用的跳过连接可能会在最终结果中引入噪声和冗余特性。如何有效地滤除噪声,同时融合低阶和高阶特征,需要认真考虑。
3)虽然针对LLIE提出了一些设计和组件,但大部分都是借鉴或修改了相关的低阶视觉任务。在设计网络结构时,应考虑弱光数据的特性。
深度学习模型和Retinex理论的结合
几乎有1/3的方法将深度网络的设计与Retinex理论相结合,例如设计不同的子网来估计Retinex模型的组成部分,估计光照图来指导网络的学习。尽管这种结合可以将基于深度学习的方法与基于模型的方法结合起来,但最终的模型可能会引入各自的缺点:
1)在基于retina的LLIE方法中,反射系数是最终增强结果的理想假设仍然会影响最终结果,
2)尽管引入了Retinex理论,但深度网络中仍存在过拟合风险。因此,当研究人员将深度学习与Retinex理论相结合时,应该仔细考虑如何去除最好的杂质。
数据格式
Raw数据格式在大多数方法中占主导地位。虽然原始数据仅限于特定的传感器,如基于拜耳模式的传感器,但数据覆盖更宽的色域和更高的动态范围。因此,在原始数据上训练的深度模型通常可以恢复清晰的细节和高对比度,获得鲜艳的颜色,减少噪声和伪影的影响,提高极弱光图像的亮度。
然而,RGB格式在某些方法中也被使用,因为它通常是智能手机相机、Go-Pro相机和无人机相机生成的最终图像形式。在未来的研究中,将不同模式的Raw数据平滑地转换为RGB格式,可能会结合RGB数据的便利性和Raw数据高质量增强的优势。
损失函数
LLIE模型中常用的损耗函数包括重构损失函数(L1、L2、SSIM)、感知损失、平滑损失。此外,根据不同的要求和配方,还采用了色差、曝光损耗和对抗损耗。
1.重构损失函数【61】
![]()
![]()
![]()
L2倾向于惩罚较大的错误,但可以容忍较小的错误。
L1可以很好地保留颜色和亮度,因为不管局部结构如何,误差都会被平均加权。
Lssim很好地保留了结构和纹理。【60】
2.感知损失【62】
![]()
感知损失是用来约束特征空间中与地面真值相似的结果。这种损失提高了结果的视觉质量。它被定义为增强结果的特征表示与相应的地面真值的特征表示之间的欧氏距离。特征表示通常是从ImageNet数据集【64】上预先训练的VGG网络【63】中提取的。
3.平滑损失

平滑损失用来去除增强结果中的噪声或保持相邻像素之间的关系,通常约束增强结果或估计的光照图。
4.对抗损失*************************************************
为了使增强的结果与参考图像难以区分,对抗学习解决了以下优化问题:
![]()
5.曝光损失
基于zsl的LLIE方法中的关键损耗函数之一,它衡量的是增强结果在没有成对或未成对图像作为参考图像时的曝光水平
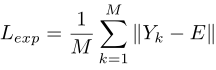
LLIE网络中常用的损失函数l1、L2、SSIM、感知损失等也被应用于用来解决图像超分辨率【65】、图像去噪【66】、图像去噪【67】、【68】、图像去模糊【69】的图像重建网络。与这些通用损失不同的是,LLIE特殊设计的曝光损耗启发了非参考损耗的设计。非参考损失不依赖于参考图像,使模型具有更好的泛化能力。在损耗函数的设计中考虑图像特性是一个正在进行的研究。
训练数据集
1.Gamma校正模拟
由于其非线性和简单性,Gamma校正被用于在视频或静止图像系统中调整亮度或三刺激值。
利用Gamma校正对亮度相关通道进行调整后,对颜色空间中相应通道进行等比例调整,避免产生伪影和颜色偏差。
为了模拟真实世界微光场景中的图像,将高斯噪声、泊松噪声或真实噪声添加到Gamma校正图像中。
2.随机照明模拟
根据Retinex模型,可以将图像分解为反射分量和光照分量。基于图像内容与光照分量无关且光照分量中的局部区域强度相同的假设,可以得到弱光图像,并将噪声添加到合成图像中。
这样的线性函数避免了伪影,但强假设要求合成只能在局部区域具有相同亮度的图像块上进行。在这样的图像块上训练的深度模型,由于忽略了上下文信息,可能会导致性能次优。
3.LOL【4】
LOL是在真实场景中拍摄的第一对低/常光图像数据集。通过改变曝光时间和ISO来收集弱光图像。LOL包含500对大小为400×600的低/常光图像,以RGB格式保存。
4.SCIE
SCIE是一个由低对比度和高对比度图像对组成的多曝光图像集。它包括589个室内和室外场景的多曝光序列。每个序列有3 - 18张不同曝光等级的低对比度图像,共包含4413张多次曝光图像。从13种具有代表性的增强算法的结果中选取589幅高质量的参考图像。即许多多次曝光的图像具有相同的高对比度参考图像。图像分辨率在3,000×2,000和6,000×4,000之间。SCIE中的图像以RGB格式保存。
5.MIT-Adobe FiveK【70】
MIT-Adobe FiveK的输入图像光线较弱,对比度较低。它包含5000张图片,每一张图片都由5名训练有素的摄影师进行润色,以达到视觉上令人愉悦的效果,类似于明信片。因此,每个输入都有五个修饰过的结果。在训练阶段,通常使用专家C的结果作为地面真值图像。图片都是Raw格式。要训练能够处理RGB格式图像的网络,需要使用Adobe Lightroom对图像进行预处理,并按照以下步骤1将其保存为RGB格式。图像通常会调整大小,使其长边为500像素。
6.SID【2】
SID包含5094张原始短曝光图像,每一张都有对应的长曝光参考图像。清晰的长曝光参考图像数为424。换句话说,多个短曝光图像对应同一个长曝光参考图像。图像有不同的传感器模式(索尼相机的拜耳传感器和富士相机的APS-C X-Trans传感器)。索尼的解决方案是4,240×2,832,富士的解决方案是6,000×4,000。通常,长曝光图像由libraw(原始图像处理库)处理并保存在sRGB颜色空间中,并随机裁剪512×512补丁进行训练。
7.VE-LOL【48】
VE-LOL包含两个子集:成对的VE-LOL-L用于训练和评估LLIE方法,而非成对的VE-LOL-H用于评估LLIE方法在人脸检测中的效果。具体来说,VE-LOL-L包含2500对图片。其中1000对是人造的,1500对是真的。VE-LOL- H包括10940张未配对的图像,其中人脸是用边界框手工标注的。
8.DRV【8】
DRV包含202个静态原始视频,每一个都有相应的长曝光地面真相。每个视频在连续拍摄模式下以每秒16至18帧的速度拍摄,最多可达110帧。这些图像是由索尼RX100 VI相机在室内和室外场景拍摄的,因此都是拜耳Raw格式。格式是3,672×5,496
9.SMOID【9】
SMOID包含179对共轴光学系统拍摄的视频,每组200帧。因此,SMOID包括35800张极低光的Bayer Raw图像和它们对应的良好光照的RGB图像。SMOID中的视频由不同光照条件下移动的车辆和行人组成。

上述成对训练数据集存在一些问题:
1)在合成数据上训练的深度模型在处理真实图像和视频时,由于合成数据和真实数据之间的差距,可能会引入伪影和颜色偏差
2)真实训练数据的规模和多样性不理想;因此,一些方法结合合成数据来增强训练数据。这可能导致次优增强
3)由于运动、硬件和环境的影响,输入图像和相应的地面真实可能存在错位。这将影响使用像素损失函数训练的深度网络的性能。
测试数据集
首先包括了【2】、【4】、【6】、【8】、【9】、【48】、【70】成对数据集中的测试子集,还有如下几种测试数据集
1)BBD-100K【75】:世界上最大的驾驶视频数据集,包含1万个视频,在一天中不同的时间、天气、条件、驾驶场景和10个任务注释,超过1100小时的驾驶体验。其中,夜间拍摄的视频被用来验证LLIE在高级视觉任务中的效果和在真实场景中的增强性能。
2)ExDARK【74】:用于微光图像的目标检测与识别。ExDARK数据集包含7363张从极低光环境到黄昏的低光图像,其中有12个对象类,用图像类标签和局部对象边界框注释。
3)DARK FACE【73】:包含6000张夜间室外场景拍摄的弱光图像,每一张图像都用人脸的边界框进行标记。

人们在实验中更倾向于使用自收集的测试数据。主要原因分为三个方面:
1)除了配对的测试分区数据集,没有承认基准评估
2)常用的测试集遭受一些缺点如小规模(有些测试集只包含10图片),重复内容和照明的属性,和未知的实验设置
3)一些常用的检测数据不是最初用于评估LLIE的。一般来说,当前的测试数据集可能会导致偏差和不公平的比较。
评价指标
除了基于人类感知的主观评价外,图像质量评价指标(IQA)还可以客观地评价图像质量,包括完全参考和非参考IQA指标。此外,用户研究、可训练参数数量、FLOPs、运行时间和基于应用的评估也反映了LLIE模型的性能,如下分析:
1)PSNR和MSE:PSNR和MSE是低层次视觉任务中广泛使用的IQA指标。它们总是非负的,接近无穷大(PSNR)和零(MSE)的值更好。然而,像素方向的PSNR和MSE由于忽略了相邻像素之间的关系,可能不能准确地反映图像质量的视觉感知。
2)MAE:MAE代表了平均绝对误差,作为成对观测之间误差的测量。MAE值越小,相似度越好。
3)SSIM:SSIM用来衡量两幅图像之间的相似度。它是一种基于感知的模型,将图像退化视为结构信息的感知变化。两组数据完全相同时,值为1,表明结构完全相似。
4)LOE:LOE表示反映增强后图像自然度的亮度顺序误差。LOE值越小,亮度顺序保持得越好。
5)Application:除了提高视觉质量外,图像增强的目的之一是为高水平的视觉任务服务。因此,通常会检查LLIE对高级可视化应用程序的影响,以验证不同方法的性能。
现有的LLIE评价方法在以下几个方面需要改进:
1)PSNR、MSE、MAE和SSIM虽然是经典和流行的指标,但它们与人类真实的视觉感知距离还很遥远
2)有些指标并非最初针对弱光图像设计的。它们被用来评估图像信息的保真度和对比度。使用这些指标可以反映图像质量,但它们与弱光增强的真正目的相去甚远
3)缺乏专门为弱光图像设计的指标,除了LOE指标。此外,目前还没有评估弱光视频增强的标准,人们期望有一个既能平衡人类视觉又能平衡机器感知的标准。
基准测试和实证分析
本节提供实证分析并突出基于深度学习的LLIE中的一些关键挑战。在本节中,我们将对几个基准和我们建议的数据集进行广泛的评估。
在实验中,我们比较了13种有代表性的方法,包括7种基于监督学习的方法(LLNet【1】,LightenNet【5】,Retinex-Net【4】,MBLLEN【3】,KinD【11】,KinD++【54】,TBEFN【20】,DSLR【21】),1种无监督学习的方法(Enlighten-GAN【23】), 1种半监督学习的方法(DRBN【27】),三种基于零镜头学习的方法(ExCNet【24】,ZeroDCE【25】,RRDNet【26】)
一个新的微光图像和视频数据集
我们提出了一个大规模的微光图像和视频数据集,称为LoLi-Phone,以全面和彻底地验证LLIE方法的性能。
LoLi-Phone是同类产品中最大、最具挑战性的真实世界测试数据集。特别是数据集包含120个视频图像(55148)由18种不同手机的相机包括iPhone 6s, iPhone 7, iPhone7 Plus, iPhone8 Plus,
iPhone 11, iPhone 11 Pro, iPhone XS, iPhone XR, iPhone SE, Xiaomi Mi 9, Xiaomi Mi Mix 3, Pixel 3, Pixel 4, Oppo R17, Vivo Nex, LG M322, OnePlus 5T, Huawei Mate 20 Pro在室内和室外场景的不同照明条件下(例如,弱光、曝光不足、月光、晨光、暗、极暗、背光、不均匀光和彩色光)

这个具有挑战性的数据集是在真实的场景中收集的,包含不同的低光图像和视频。因此,该方法适用于评价不同微光图像和视频增强模型的泛化能力。值得注意的是,该数据集可以作为无监督学习方法的训练数据集和合成方法的参考数据集,以生成真实的微光图像和视频。
在线评估平台
http://mc.nankai.edu.cn/ll/
基准测试结果
我们从LoLi-Phone数据集的每个视频中平均选取5张图像,形成一个总共600张图像的图像测试数据集(记为LoLi-PhoneimgT)。此外,我们从每个手机的LoLi-Phone品牌的视频数据集中随机选择一个视频,形成一个总共有18个视频的视频测试数据集(记为LoLi-Phone- vidt)。我们在LoLi-Phone-imgT和LoLi-Phone-vidT中都将帧的分辨率减半,因为一些基于深度学习的方法无法处理测试图像和视频的全部分辨率。
对于LOL数据集,我们采用真实场景中采集的15张微光图像的原始测试集进行测试,记作LOL-test。
对于MIT-Adobe FiveK数据集,我们遵循【40】中的处理将图像解码为PNG格式,并使用Lightroom将它们的长边大小调整为512像素。我们采用与【40】,MITAdobe FiveK-test相同的测试数据集,包括500张图像,其中专家C的润色结果作为相应的ground truth。
1.定性比较
如图所示,所有方法都提高了输入图像的亮度和对比度。然而,当结果与地面真实相比较时,没有一种方法能够成功地恢复输入图像的准确颜色。特别是LLNet【1】产生模糊结果。LightenNet【5】和RRDNet【26】产生曝光不足的结果,而MBLLEN【3】和ExCNet【24】倾向于过度曝光图像。KinD【11】、KinD++【54】、TBEFN【20】、DSLR【21】、Enlightenment GAN【23】、DRBN【27】引入明显伪影。

LLNet【5】、KinD++【54】、TBEFN【20】和RRDNet【26】产生了过度曝光的结果。Retinex-Net【4】,KinD++【54】和RRDNet【26】在结果中产生伪影和模糊。我们发现MITAdobe FiveK数据集的ground truth仍然包含一些黑暗区域。这是因为数据集最初是为全局图像修饰而设计的,因此恢复低光区域并不是这项任务的主要优先级

我们还观察到LOL数据集和MIT-Adobe FiveK数据集的输入图像相对较干净,这与真实的低光场景不同。虽然一些LLIE方法【18】,【21】,【53】采用MITAdobe FiveK数据集作为训练或测试数据集,但我们认为该数据集不适合LLIE的任务,因为它对LLIE不匹配/不满意的地面真相。
如图7所示,所有的方法都不能有效地提高输入低光图像的亮度和去除噪声。此外,Retinex-Net 【4】, MBLLEN【3】和DRBN【27】产生明显的伪影。在图8中,所有方法都增强了输入图像的亮度。然而,只有MBLLEN【3】和RRDNet[【26】在没有色差、伪影和过度/不足曝光的情况下获得了视觉上令人愉悦的增强。值得注意的是,对于有光源的区域,没有一种方法能在不放大这些区域周围噪声的情况下使图像变亮。在LLIE中考虑光源将是一个有趣的探索方向。


2.定量比较
对于具有ground truth的测试集,即LOL-test和MIT-Adobe FiveK-test,我们采用MSE、PSNR、SSIM【60】和LPIPS【76】度量来定量比较不同的方法。LPIPS【76】是一种基于深度学习的图像质量评估指标,通过深度视觉表征来衡量结果与其对应的ground truth之间的感知相似性。对于LPIPS,我们采用基于alexnet的模型来计算感知相似度。较低的LPIPS值表明,在感知相似性方面,结果更接近相应的ground truth。

在LOL-test和MIT-Adobe FiveK-test数据集上,基于监督学习方法的量化得分优于基于无监督学习方法、半监督学习方法和基于零次学习方法。其中,LLNet【1】在LOL-test数据集上获得了最佳的MSE和PSNR值。然而,它的性能在MIT-Adobe fivek测试数据集上下降。这可能会导致LLNet【1】对LOL数据集的偏差,因为它是使用LOL训练数据集训练的。对于LOL-test数据集,TBEFN【20】的SSIM值最高,KinD【11】的LPIPS值最低。尽管有些方法是在LOL训练数据集上训练的,但在LOL-test数据集上的这四个评价指标中没有赢家。对于MIT-Adobe FiveK-test数据集,MBLLEN【3】在四个评价指标下优于所有比较方法,尽管在合成训练数据上进行训练。然而,MBLLEN【3】在两个测试数据集上仍然不能获得最好的性能。
对于LoLi-Phone-imgT测试集,我们使用非参考图像质量评估指标NIQE【77】、知觉指数(PI)【77】、【78】、【79】、LOE【30】和SPAQ【80】来定量比较不同的方法。从LOE来看,LOE值越小,亮度顺序保持得越好。对于NIQE, NIQE值越小,视觉质量越好。PI值越低,感知质量越好。SPAQ是为智能手机摄影感知质量评估而设计的。SPAQ值越大,说明智能手机摄影的感知质量越好。

我们可以发现Retinex-Net【4】, KinD++【54】,以及Enlightened-GAN【23】的性能相对较好。Retinex-Net【4】的PI和SPAQ得分最高。评分结果表明,Retinex-Net【4】提高了结果良好的知觉质量。但是,Retinex-Net【4】的结果明显存在伪影和颜色偏差。因此,我们认为非参考PI和SPAQ指标可能不适用于弱光图像的感知质量评价。其中,KinD++【54】的NIQE得分最低,而原始输入的LOE得分最低。对于事实上的标准LOE度量,我们质疑亮度顺序是否能有效地反映增强性能。总的来说,非参考IQA指标在评价增强的弱光图像质量时存在偏差。
为了在LoLi-vidT测试集中准备视频,我们首先丢弃连续帧中没有明显对象的视频。总共选择了10个视频。对于每一个视频,我们选择一个在所有帧中出现的对象。然后我们使用跟踪器【81】在输入视频的连续帧中跟踪目标,并确保在边界框中出现相同的目标。我们丢弃目标跟踪不准确的帧。在每一帧中收集包围盒的坐标。我们利用这些坐标对不同方法增强的结果中对应的区域进行裁剪,并计算对象在连续帧中的平均亮度方差(ALV),ALV值越低,增强视频的时间相干性越好。此外,我们利用【9】绘制它们在补充材料中的亮度曲线。
![]()

由上图可知,BEFN【20】的ALV值的时间相干性最好,LLNet【1】和Enlightened-GAN【23】的时间相干性次之,第三。ExCNet【24】的ALV值最差,为1375.29。这是因为基于零参考学习的ExCNet【24】对连续帧的增强性能不稳定。换句话说,ExCNet【24】可以有效地提高某些帧的亮度,而在其他帧上却不能很好地工作。
计算复杂度
我们比较了不同方法的计算复杂度,包括运行时长、可训练参数和使用NVIDA 1080Ti GPU训练的32张1200×900×3大小的图像的平均FLOPs。
为了公平比较,我们省略了LightenNet【5】,因为只有它的CPU版本的代码是公开的。另外,我们不报告ExCNet【24】和RRDNet【26】的FLOPs,因为该值的大小取决于输入图像(不同的输入需要不同数量的迭代)

如上表所示,Zero-DCE【25】运行时间最短,因为它只通过一个轻量级网络估计几个曲线参数。因此,它的可训练参数和FLOPs的数量要少得多。此外,LightenNet【5】的可训练参数数和FLOPs数在比较方法中最少。这是因为LightenNet【5】通过一个由四个卷积层组成的微小网络来估计输入图像的光照图。LLNet【1】和KinD++【54】的FLOPs非常大,分别达到4124.177G和12238.026G。基于ssl的ExCNet【24】和RRDNet【26】由于优化过程耗时,运行时间较长。
基于应用程序的评估
我们研究了弱光图像增强方法在黑暗中人脸检测中的性能。按照【25】中的设置,我们使用DARK FACE数据集【73】,该数据集由在黑暗中拍摄的人脸图像组成。由于测试集的包围盒不是公开可用的,我们对从训练集和验证集中随机采样的500张图像进行评估。使用在WIDER Face数据集【83】上训练的双镜头人脸检测器(DSFD)【82】作为人脸检测器。我们将不同LLIE方法的结果输入DSFD【82】,并在图中描绘了0.5 IoU阈值下的精度召回(P-R)曲线。

此外,我们使用下表中DARK FACE数据集【73】提供的评价工具3比较了不同IoU阈值下的平均精度(AP)。

所有基于深度学习的解决方案都提高了黑暗条件下人脸检测的性能,说明基于深度学习的LLIE解决方案在黑暗条件下人脸检测中的有效性。由上表可以看出,表现最好的人在不同IoU阈值下的AP得分范围为0.268 ~ 0.013,且输入在不同IoU阈值下的AP得分非常低。结果表明,仍有改进的空间。值得注意的是,Retinex-Net【4】、Zero-DCE【25】和TBEFN【20】在黑暗环境下的人脸检测中具有相对健壮的性能。我们在下图中展示了不同方法的可视化结果。尽管Retinex-Net【4】比其他方法AP评分高,其视觉结果包含明显的人为因素和非自然纹理。总的来说,ZeroDCE【25】在黑暗中人脸检测的AP分数和感知质量之间取得了很好的平衡。
 讨论
讨论
从实验结果中,我们得到了一些有趣的观察和见解:
1)基于测试数据集和评估指标,不同方法的性能存在显著差异。在常用测试数据集的全参考IQA指标方面,MBLLEN[3]、KinD++[54]和DSLR[21]总体上优于其他比较方法。对于由手机拍摄的真实世界的微光图像,基于监督学习的Retinex-Net[4]和KinD++[54]在非参考IQA指标中获得更好的分数。对于用手机拍摄的现实世界的微光视频,TBEFN[20]更好地保留了时间相干性。在计算效率方面,LightenNet[5]和Zero-DCE[25]表现突出。在黑暗中的人脸检测方面,TBEFN[20]、Retinex-Net[4]、Zero-DCE[25]排在前三位。没有一种方法总是成功的。总的来说,在大多数情况下,retina - net [4], [20], Zero-DCE[25]和DSLR[21]是更好的选择。
2)低光图像和视频的提议LoLi-Phone数据集失败了大多数方法。现有方法的泛化能力有待进一步提高。值得注意的是,仅用平均亮度方差来评价弱光视频增强的不同方法的性能是不够的。更有效和全面的评估指标将指导微光视频增强的发展走向正确的轨道。
3)在学习策略方面,监督学习在大多数情况下都有较好的表现,但需要大量的计算资源和成对的训练数据。相比之下,零概率学习在实际应用中更有吸引力,因为它不需要成对或非成对的训练数据。因此,基于零次学习的方法具有更好的泛化能力。然而,基于零机会学习的方法的定量性能不如其他方法。
4)视觉结果和定量的IQA评分之间存在差距。换句话说,良好的视觉外观并不总是产生良好的IQA分数。人类感知与IQA评分之间的关系值得更多的研究。追求更好的视觉感知或量化分数取决于具体的应用。例如,为了将结果展示给观察者,就应该更加注意视觉感知。相比之下,LLIE方法在黑暗环境下进行人脸检测时,精度比视觉感知更重要。因此,在比较不同的方法时,应进行更全面、更彻底的比较。、
5)基于深度学习的LLIE方法有利于在黑暗中进行人脸检测。这些结果进一步支持了增强弱光图像和视频的重要性。然而,与正常光照下的图像中人脸检测的高准确率相比,在黑暗环境下,尽管使用了LLIE方法,人脸检测的准确率却非常低。
潜在研究方向
有效的学习策略
如前所述,目前的LLIE模型主要采用监督学习,这需要大量的成对训练数据,可能会对特定的数据集进行过拟合。虽然有研究者尝试将非监督学习(如对抗性学习)引入LLIE,但LLIE与这些学习策略之间的内在联系尚不明确,其在LLIE中的有效性有待进一步提高。零镜头学习在不需要成对训练数据的情况下,在真实场景中表现出了稳健的性能。这种独特的优势表明,零机会学习是一个潜在的研究方向,特别是在零参考损失的制定、深度先验和优化策略方面。
特定的网络结构
网络结构对增强性能有显著影响。如前所述,大多数LLIE深度模型采用u网或类似u网的结构。虽然它们在某些情况下取得了很好的性能,但是对于这种编解码器网络结构是否最适合LLIE任务的研究仍然缺乏。一些网络结构由于参数空间大,需要占用较大的内存和较长的推断时间。这种网络结构在实际应用中是不可接受的。因此,考虑到弱光图像的光照不均匀、像素值小、噪声抑制和颜色恒定等特点,研究一种更有效的LLIE网络结构是值得的。也可以通过考虑弱光图像的局部相似性或考虑深度可分离卷积层[84]和自校准卷积[85]等更有效的操作来设计更高效的网络结构。神经结构搜索(Neural architecture search, NAS)技术[86]、[87]可以考虑获得更有效、更高效的LLIE网络结构。将变压器架构[88]、[89]应用于LLIE可能是一个潜在的、有趣的研究方向。
损失函数
损失函数约束了输入图像与地面真实之间的关系,推动了深度网络的优化。LLIE中常用的损失函数借用了相关的视觉任务。没有专门的损耗函数来指导弱光视频增强网络的优化。因此,需要设计更适合LLIE的损耗函数。此外,最近的研究表明,利用深度神经网络近似人类对图像质量的视觉感知的可能性[90],[91]。这些思想和基本理论可用于指导弱光增强网络合适损耗函数的设计。
真实训练数据集
虽然LLIE有几个训练数据集,但它们的真实性、规模和多样性都落后于真实的弱光条件。因此,如第4节所示,当前的LLIE深度模型在遇到真实场景中捕获的微光图像时,无法达到令人满意的性能。需要更多的努力来研究大规模和多样化的真实世界配对LLIE 17训练数据集的收集,或者生成更真实的合成数据。
标准测试数据
目前还没有公认的LLIE评价基准。研究人员更喜欢选择他们自己的测试数据,这可能会偏向于他们提出的方法。尽管一些研究人员留下一些成对的数据作为测试数据,训练和测试分区的划分在文献中大多是特别的。因此,在不同的方法之间进行公平的比较,即使不是不可能,也是很费力的。此外,有些测试数据要么易于处理,要么在弱光增强时没有最初收集。希望有一个标准的微光图像和视频测试数据集,其中包括大量的测试样本,具有相应的地面真相,涵盖不同的场景和挑战性的照明条件。
特定的评估指标
LLIE中常用的评价指标可以在一定程度上反映图像质量。然而,如何衡量LLIE方法增强结果的程度,仍然挑战着当前的IQA度量标准,特别是对于非参考度量标准。此外,目前的IQA指标要么关注人的视觉感知(如主观质量),要么强调机器感知(如对高级视觉任务的影响)。需要一种同时考虑人类感知和机器感知的评价指标。因此,在本研究方向还需要做更多的工作,为LLIE设计更准确、更有任务针对性的评价指标。
健壮的泛化能力
在实际测试数据上观察实验结果,大多数方法由于泛化能力有限而失败。综合训练数据、小尺度训练数据、无效的网络结构、不现实的假设和不准确的先验等因素导致了较差的泛化。研究如何提高基于深度学习的LLIE模型的泛化性是非常重要的。
扩展到低光视频增强
与视频去模糊[92]、视频去噪[93]、视频超分辨率[94]等其他低水平视觉任务中视频增强的快速发展不同,弱光视频增强受到的关注较少。将现有的LLIE方法直接应用于视频往往会导致不满意的结果和闪烁伪影。为了有效地消除视觉闪烁,充分利用相邻帧间的时间信息,提高增强速度,需要付出更多的努力。
结合语义信息
语义信息是微光增强的关键。它指导网络在增强过程中区分不同的区域。没有语义先验的网络很容易偏离区域的原始颜色,例如增强后将黑发变成灰色。因此,将语义先验集成到LLIE模型中是一个很有前景的研究方向。在图像超分辨率[95]、[96]和面部恢复[97]方面也做了类似的工作。















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









