






内存访问模式的影响:行主序与列主序的性能分析
两种方式执行的对比
我们平时默认就是使用的第一种方式遍历数组。可能很少思考为什么使用第一种不用第二种,今天来试着比较一下两种方式的差距。
// 在第一种方式中,内层循环首先访问nums[i][0],然后nums[i][1],依此类推。这是一种连续的内存访问模式,称为行主序(row-major order)或按行存储(row-wise storage)。
public static void ergodicOne(int[][] nums){
for (int i = 0;i<nums.length;i++){
for (int j = 0; j<nums[0].length;j++){
int a = nums[i][j];
}
}
}
// 在第二种方式中,内层循环首先访问nums[0][i],然后nums[1][i],依此类推。这是一种间断的内存访问模式,称为列主序column-major order)或按列存储(column-wise storage)
public static void ergodicTwo(int[][] nums){
for (int i = 0;i<nums.length;i++){
for (int j = 0; j<nums[0].length;j++){
int a = nums[j][i];
}
}
}
传入大小 100x100 的数组 遍历10万次
public static long count1 (int[][] nums){
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
ergodicOne(nums);
}
long end = System.currentTimeMillis();
return end-start;
}
public static long count2 (int[][] nums){
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
ergodicTwo(nums);
}
long end = System.currentTimeMillis();
return end-start;
}
public static int[][] create (){
int[][] ints = new int[100][100];
for (int i = 0;i<ints.length;i++){
for (int j = 0; j<ints[0].length;j++){
ints[i][j] = i+j;
}
}
return ints;
}
public static void main(String[] args) throws Exception{
int[][] nums = create();
long t1 = count1(nums);
long t2 = count2(nums);
System.out.println("第一种方式耗时:"+ t1); // 456
System.out.println("第二种方式耗时:"+ t2); // 668
}
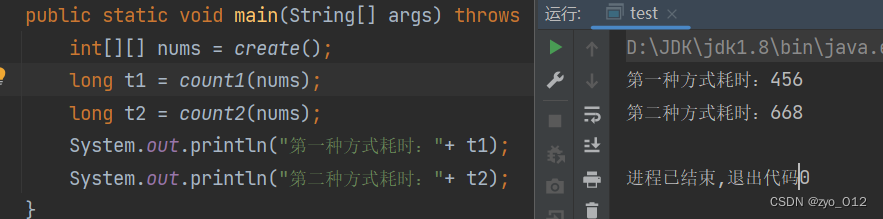
可以看出第一种方式和第二种方式遍历数组有很大的差距,这是为什么呢?
分析
cpu内存层级:
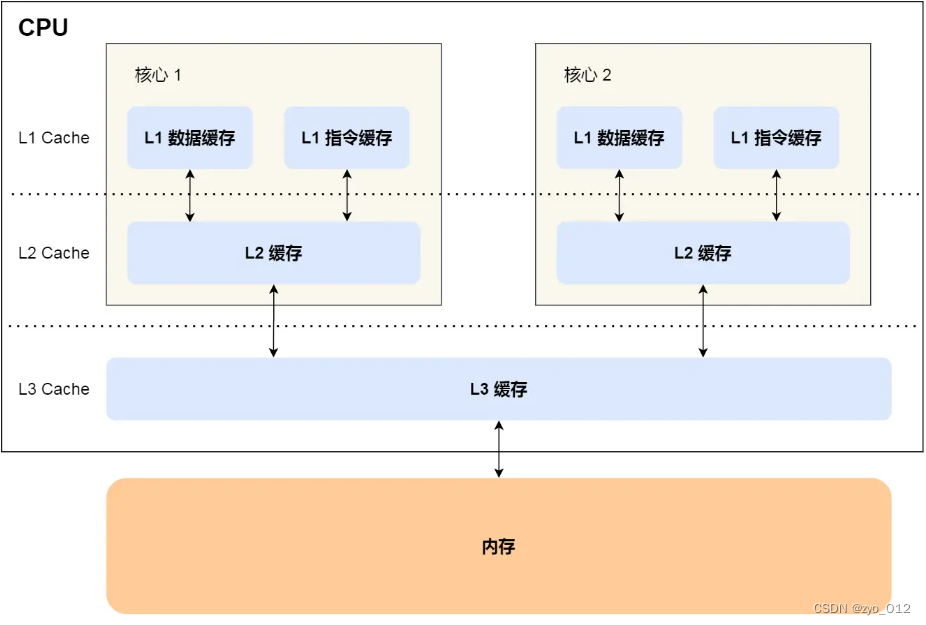
- L1 Cache 通常会分为「数据缓存」和「指令缓存」,这意味着数据和指令在 L1 Cache 这一层是分开缓存的
- 程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后进入到最快的 L1 Cache,之后才会被 CPU 读取。
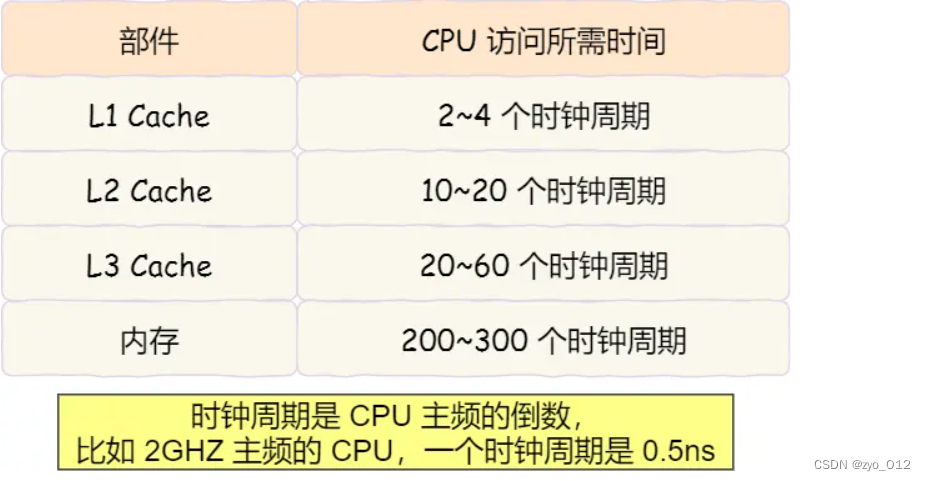
越靠近 CPU 核心的缓存其访问速度越快,CPU 访问 L1 Cache 只需要 2~4 个时钟周期,访问 L2 Cache 大约 10~20 个时钟周期,访问 L3 Cache 大约 20~60 个时钟周期,而访问内存速度大概在 200~300 个 时钟周期之间。如下表格:
在这两种方式中,第一种方式(ergodicOne)执行更快的原因是与内存访问模式和CPU缓存有关。让我们更详细地解释一下:
CPU缓存:
- 现代计算机系统通常具有多级缓存(L1、L2、L3缓存等)。这些缓存是用来存储从主内存中读取的数据,以加速CPU对数据的访问。
- CPU缓存以缓存行(cache line)为单位进行数据加载。每个缓存行通常包含多个相邻的字节或整数。当CPU访问一个特定的内存地址时,它通常会将整个缓存行加载到缓存中。
- 在行主序访问中,连续的数组元素通常位于相邻的内存地址中,因此它们更有可能在同一个缓存行中。这意味着在行主序访问中,CPU更容易从缓存中命中数据,而不必频繁地从主内存中加载新数据。
- 在列主序访问中,由于内存访问模式不连续,CPU可能需要更频繁地从内存中加载新的缓存行,导致更多的缓存未命中(cache misses)。
因此,第一种方式(ergodicOne)的行主序访问模式更有可能充分利用CPU缓存,减少了缓存未命中的情况,从而使代码执行更快。总之,在编写需要频繁访问多维数组的代码时,可以通过优化内存访问模式来提高性能。














 8075
8075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









