







使用 LSTM 网络即兴创作爵士乐独奏
1、问题描述
2、模型的构建
3、生成音乐
第五门课:序列模型
第一周:循环序列模型
将实现一个使用 LSTM 生成音乐的模型。您甚至可以在作业结束时听自己的音乐。
您将学习:
将 LSTM 应用于音乐生成。
通过深度学习生成您自己的爵士音乐。
from __future__ import print_function
import IPython
import sys
from music21 import *
import numpy as np
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
from keras.models import load_model, Model
from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from keras.initializers import glorot_uniform
from keras.utils import to_categorical
from keras.optimizers import Adam
from keras import backend as K
一、问题描述
您想专门为朋友的生日创作一首爵士乐作品。但是,您不了解任何乐器或音乐作品。幸运的是,您了解深度学习,并将使用 LSTM 网络来解决这个问题。
您将训练一个网络,以代表表演作品的风格生成新颖的爵士独奏。
1、数据集
IPython.display.Audio('./data/30s_seq.mp3')
我们负责对音乐数据进行预处理,以根据音乐“价值”进行渲染。你可以非正式地把每个“值”想象成一个音符,它包括一个音高和一个持续时间。例如,如果您按住特定的钢琴键 0.5 秒,那么您刚刚弹奏了一个音符。在音乐理论中,“值”实际上比这更复杂——具体来说,它还捕获了同时演奏多个音符所需的信息。例如,在弹奏一首乐曲时,您可以同时按下两个钢琴键(同时弹奏多个音符会产生所谓的“和弦”)。但是我们不需要担心这个作业的音乐理论的细节。出于此作业的目的,您需要知道的是,我们将获得一个值数据集,并将学习一个 RNN 模型来生成值序列。
我们的音乐生成系统将使用 78 个唯一值。运行以下代码以加载原始音乐数据并将其预处理为值。这可能需要几分钟时间。
X, Y, n_values, indices_values = load_music_utils()
print('shape of X:', X.shape)
print('number of training examples:', X.shape[0])
print('Tx (length of sequence):', X.shape[1])
print('total # of unique values:', n_values)
print('Shape of Y:', Y.shape)
您刚刚加载了以下内容:
1、X:这是一个 (m, Tx , 78) 维数组。我们有 m 个训练示例,每个示例都是 Tx=30 的片段
音乐价值。在每个时间步长中,输入是 78 个不同可能值之一,表示为一个热向量。因此,例如,X[i,t,:] 是一个单热向量,表示第 i 个示例在时间 t 的值。
2、Y:这与X基本相同,但向左移动了一步(过去)。与恐龙赋值类似,我们对使用前一个值来预测下一个值的网络感兴趣,因此我们的序列模型将尝试预测 y⟨t⟩给定 x⟨1⟩,…,x⟨t⟩ .但是,Y 中的数据被重新排序为维度 (Ty,m,78),其中 Ty=T 这种格式使以后馈送到 LSTM 更加方便。
3、n_values:此数据集中唯一值的数量。这应该是 78。
4、indices_values:python字典从0-77映射到音乐值。
2、模型概述
下面是我们将使用的模型的架构。这与您在上一个笔记本中使用的恐龙模型类似,只是您将在 Keras 中实现它。架构如下:
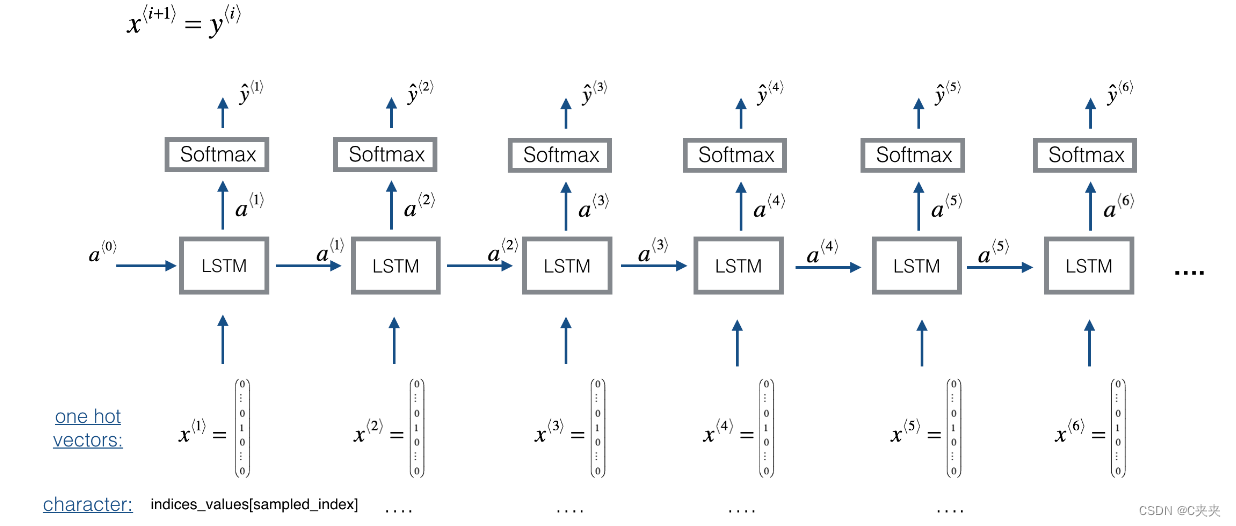
我们将使用从更长的音乐片段中获取的 30 个值的随机片段来训练模型。因此,我们不会费心设置第一个输入 x⟨1⟩=0⃗,我们之前曾这样做过,以表示恐龙名称的开头,因为现在大多数这些音频片段都是从一段音乐中间的某个地方开始的。我们将每个片段设置为具有相同的长度 Tx=30使矢量化更容易。
二、模型的构建
在这一部分中,您将构建和训练一个学习音乐模式的模型。为此,您需要构建一个形状为 X 的模型 (m,Tx,78)和形状的 Y (Ty,m,78).我们将使用具有 64 维隐藏状态的 LSTM。让我们设置 n_a = 64。
n_a = 64
下面介绍如何创建具有多个输入和输出的 Keras 模型。如果你正在构建一个 RNN,即使在测试时,整个输入序列 x⟨1⟩,x⟨2⟩,…,x⟨Tx⟩是预先给出的,例如,如果输入是单词,输出是标签,那么 Keras 具有简单的内置函数来构建模型。但是,对于序列生成,在测试时,我们并不知道 x⟨t 的所有值⟩提前;取而代之的是,我们使用 x⟨t⟩=y⟨t−1 一次生成一个⟩ .因此,代码会稍微复杂一些,您需要实现自己的 for 循环来迭代不同的时间步长。
函数 djmodel() 将调用 LSTM 层 Tx使用 for 循环的次数,并且重要的是所有 Tx副本具有相同的权重。也就是说,它不应该每次都重新启动权重—步骤应具有共享权重。在 Keras 中实现具有可共享权重的层的关键步骤是:
1、定义图层对象(我们将为此使用全局变量)。
2、在传播输入时调用这些对象。
我们已将您需要的图层对象定义为全局变量。请运行下一个单元格以创建它们。请查看 Keras 文档,以确保您了解这些层是什么:Reshape()、LSTM()、Dense()。
reshapor = Reshape((1, 78)) # Used in Step 2.B of djmodel(), below
LSTM_cell = LSTM(n_a, return_state = True) # Used in Step 2.C
densor = Dense(n_values, activation='softmax') # Used in Step 2.D
reshapor、LSTM_cell 和 densor 现在都是层对象,您可以使用它们来实现 djmodel()。为了将 Keras 张量对象 X 传播到这些层之一,请使用 layer_object(X)(或 layer_object([X,Y]) 如果需要多个输入。例如,reshapor(X) 将通过上面定义的 Reshape((1,78)) 层传播 X。
练习:实现 djmodel()。您将需要执行 2 个步骤:
1、创建一个空列表“outputs”,以保存每个时间步的 LSTM 单元的输出。
2、t∈1,…,Tx 环路:
A. 从 X 中选择“t”个时间步长向量。此选择的形状应为 (78,)。为此,请使用以下代码行在 Keras 中创建自定义 Lambda 层:x = Lambda(lambda x: X[:,t,:])(X)
查看 Keras 文档以了解其作用。它正在创建一个“临时”或“未命名”函数(这就是 Lambda 函数),以提取适当的独热向量,并使该函数成为应用于 X 的 Keras Layer 对象。
B. 将 x 调整为 (1,78)。您可能会发现 reshapor() 层(定义如下)很有帮助。
C. 通过LSTM_cell的一个步骤运行 x。请记住使用上一步的隐藏状态 a 初始化LSTM_cell和单元状态 C.使用以下格式:
a, _, c = LSTM_cell(input_x, initial_state=[previous hidden state, previous cell state])
D. 使用密度将 LSTM 的输出激活值传播到密集 + softmax 层。
E. 将预测值附加到“输出”列表中
实现模型
参数:
Tx -- 语料库中序列的长度
n_a -- 模型中使用的激活次数
n_values -- 音乐数据中唯一值的数量
返回: model -- 一个 Keras 模型,带有
# GRADED FUNCTION: djmodel
def djmodel(Tx, n_a, n_values):
# Define the input of your model with a shape
X = Input(shape=(Tx, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
# Step 1: Create empty list to append the outputs while you iterate (≈1 line)
outputs = []
# Step 2: Loop
# Step 2.A: select the "t"th time step vector from X.
x = Lambda(lambda x: X[:,t,:])(X)
# Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line)
x = reshapor(x)
# Step 2.C: Perform one step of the LSTM_cell
a, _, c = LSTM_cell(x, initial_state=[a, c])
# Step 2.D: Apply densor to the hidden state output of LSTM_Cell
out = densor(a)
# Step 2.E: add the output to "outputs"
outputs.append(out)
# Step 3: Create model instance
model = Model(inputs=[X, a0, c0], outputs=outputs)
return model
# 运行以下单元格以定义模型。我们将使用 Tx=30、n_a=64(LSTM 激活的维度)和 n_values=78。此单元可能需要几秒钟才能运行。
model = djmodel(Tx = 30 , n_a = 64, n_values = 78)
# 现在,您需要编译要训练的模型。我们将亚当和绝对的交叉熵损失。
opt = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
# 最后,让我们初始化 a0 和 c0,使 LSTM 的初始状态为零。
m = 60
a0 = np.zeros((m, n_a))
c0 = np.zeros((m, n_a))
现在让我们适合模型!在执行此操作之前,我们将 Y 转换为列表,因为成本函数期望 Y 以这种格式提供(每个时间步长一个列表项)。所以 list(Y) 是一个包含 30 个项目的列表,其中每个列表项的形状为 (60,78)。让我们训练 100 个 epoch。这将需要几分钟时间。
model.fit([X, a0, c0], list(Y), epochs=100)
您应该看到模型损失下降。现在你已经训练了一个模型,让我们进入最后一节,实现一个推理算法,并生成一些音乐!
三、生成音乐
您现在有一个训练有素的模型,它已经学习了爵士独奏者的模式。现在让我们使用这个模型来合成新音乐。
1、预测和抽样
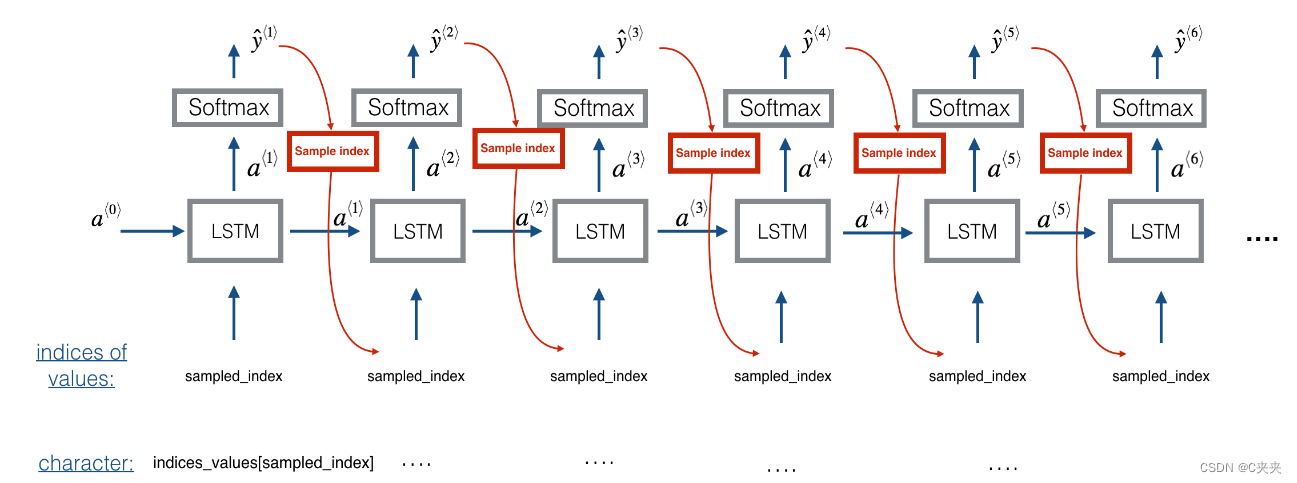
在采样的每一步中,您将从 LSTM 的先前状态获取激活 a 和单元状态 c 作为输入,向前传播一步,并获得新的输出激活和单元状态。然后,可以使用新的激活 a 来生成输出,像以前一样使用 densor。
为了开始模型,我们将初始化 x0 以及 LSTM 激活,并将单元格值 a0 和 c0 设置为零。
练习:实现以下函数以对一系列音乐值进行采样。以下是您需要在生成 Ty 的 for 循环中实现的一些关键步骤
输出字符:
步骤 2.A:使用 LSTM_Cell,输入上一步的 c 和 a,生成当前步骤的 c 和 a。
步骤 2.B:使用 densor(之前定义)计算 a 上的 softmax,以获得当前步骤的输出。
步骤 2.C:通过将刚刚生成的输出附加到输出来保存它。
步骤 2.D:将 x 采样到 be “out” 的 one-hot 版本(预测),以便您可以将其传递给下一个 LSTM 的步骤。我们已经提供了这行代码,它使用 Lambda 函数。
x = Lambda(one_hot)(输出)
[次要技术说明:这行代码实际上不是根据输出中的概率随机抽取一个值,而是使用argmax在每个步骤中选择最有可能的单个注释。
使用 model() 中经过训练的“LSTM_cell”和“densor”来生成一系列值。
参数:
LSTM_cell -- 从 model() 中训练的 “LSTM_cell”,Keras 层对象
densor -- 从 model() 中训练的 “densor”,Keras 层对象
n_values -- 整数,唯一值的琥珀色
n_a -- LSTM_cell中的单位数
Ty -- 整数,要生成的时间步长数
返回:inference_model -- Keras 模型实例
# GRADED FUNCTION: music_inference_model
def music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100):
# Define the input of your model with a shape
x0 = Input(shape=(1, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
x = x0
# Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line)
outputs = []
# Step 2: Loop over Ty and generate a value at every time step
for t in range(Ty):
# Step 2.A: Perform one step of LSTM_cell (≈1 line)
a, _, c = LSTM_cell(x, initial_state=[a, c])
# Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell (≈1 line)
out = densor(a)
# Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 78) (≈1 line)
outputs.append(out)
# Step 2.D: Select the next value according to "out", and set "x" to be the one-hot representation of the
# selected value, which will be passed as the input to LSTM_cell on the next step. We have provided
# the line of code you need to do this.
x = Lambda(one_hot)(out)
# Step 3: Create model instance with the correct "inputs" and "outputs" (≈1 line)
inference_model = Model(inputs=[x0, a0, c0], outputs=outputs)
return inference_model
inference_model = music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 50)
x_initializer = np.zeros((1, 1, 78))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))
练习:实现 predict_and_sample()。此函数接受许多参数,包括输入 [x_initializer, a_initializer, c_initializer]。为了预测与此输入对应的输出,您需要执行 3 个步骤:
1、使用推理模型来预测给定一组输入的输出。输出 pred 应该是一个长度为 50 的列表,其中每个元素都是一个形状为 ( Ty
,n_values)
2、将 pred 转换为 Ty 的 numpy 数组
指标。每个索引对应的都是通过获取 pred 列表中某个元素的 argmax 来计算的。提示。
3、将索引转换为其独热向量表示形式。提示。
使用推理模型预测值的下一个值。
参数:
inference_model -- 用于推理时间的 Keras 模型实例
x_initializer -- 形状为 (1, 1, 78) 的 numpy 数组,初始化值生成的 one-hot 向量
a_initializer -- 形状 (1, n_a) 的 numpy 数组,初始化LSTM_cell的隐藏状态
c_initializer -- 形状为 (1, n_a) 的 numpy 数组,初始化LSTM_cel的单元格状态
返回:
results -- 形状的 numpy-array (Ty, 78),表示生成值的独热向量矩阵
indices -- 形状的 numpy-array (Ty, 1),表示生成的值的索引矩阵
# GRADED FUNCTION: predict_and_sample
def predict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer,
c_initializer = c_initializer):
# Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer.
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
# Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities
indices = np.argmax(pred, axis=-1)
# Step 3: Convert indices to one-hot vectors, the shape of the results should be (1, )
results = to_categorical(indices, num_classes=x_initializer.shape[-1])
return results, indices
results, indices = predict_and_sample(inference_model, x_initializer, a_initializer, c_initializer)
print("np.argmax(results[12]) =", np.argmax(results[12]))
print("np.argmax(results[17]) =", np.argmax(results[17]))
print("list(indices[12:18]) =", list(indices[12:18]))
预期输出:您的结果可能会有所不同,因为 Keras 的结果并不完全可预测。但是,如果您已经使用 model.fit() 训练了 LSTM_cell,如上所述,则恰好训练了 100 个 epoch,则很可能观察到一系列不完全相同的索引。此外,您应该注意:np.argmax(results[12]) 是 list(indices[12:18]) 的第一个元素,np.argmax(results[17]) 是 list(indices[12:18]) 的最后一个元素。

2、生成音乐
最后,您就可以生成音乐了。您的 RNN 会生成一系列值。以下代码通过首先调用 predict_and_sample() 函数来生成音乐。然后将这些值后处理为音乐和弦(这意味着可以同时演奏多个值或音符)。
大多数计算音乐算法都使用一些后处理,因为如果没有这样的后处理,就很难生成听起来不错的音乐。后期处理会执行一些操作,例如通过确保相同的声音不会重复太多次、两个连续的音符在音高上不会相距太远来清理生成的音频,等等。有人可能会争辩说,这些后处理步骤中有很多都是黑客攻击;此外,许多音乐生成文献也专注于手工制作后处理器,很多输出质量取决于后处理的质量,而不仅仅是 RNN 的质量。但是这种后处理确实产生了巨大的差异,所以让我们在实现中也使用它。
out_stream = generate_music(inference_model)
要收听音乐,请单击“文件”->“打开…”。然后转到“output/”并下载“my_music.midi”。如果您有可以读取 MIDI 文件的应用程序,请在您的计算机上播放它,或者使用免费的在线“MIDI 到 mp3”转换工具之一将其转换为 mp3。
作为参考,这里也是我们使用此算法生成的 30 秒音频剪辑。
IPython.display.Audio('./data/30s_trained_model.mp3')
您应该记住以下几点:
- 序列模型可用于生成音乐值,然后将其后处理为 MIDI 音乐。
- 相当相似的模型可用于生成恐龙名称或生成音乐,主要区别在于输入到模型。
- 在 Keras 中,序列生成涉及定义具有共享权重的层,然后在不同的时间步长 1,…,Tx 重复这些层
.
引用
本笔记本中提出的想法主要来自下面引用的三篇计算音乐论文。这里的实现也获得了重要的灵感,并使用了 Ji-Sung Kim 的 github 存储库中的许多组件。
1、Ji-Sung Kim, 2016, deepjazz
2、Jon Gillick、Kevin Tang 和 Robert Keller,2009 年。学习爵士乐语法
3、罗伯特·凯勒(Robert Keller)和大卫·莫里森(David Morrison),2007年,《自动即兴创作的语法方法》
4、弗朗索瓦·帕切特,1999年,《令人惊讶的和声》
我们也感谢弗朗索瓦·日耳曼(François Germain)的宝贵反馈。















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









